MUSE-VL: Modeling Unified VLM through Semantic Discrete Encoding
作者: Rongchang Xie, Chen Du, Ping Song, Chang Liu
分类: cs.CV
发布日期: 2024-11-26 (更新: 2025-07-28)
备注: ICCV 2025
💡 一句话要点
MUSE-VL:通过语义离散编码建模统一的视觉-语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多模态学习 语义离散编码 跨模态对齐 视觉理解 视觉生成 统一模型
📋 核心要点
- 现有视觉-语言统一模型依赖的视觉tokenizers仅关注低级信息,难以与语言token对齐,导致训练复杂且性能受限。
- MUSE-VL提出语义离散编码(SDE),通过在视觉tokenizer中引入语义约束,实现视觉和语言token的有效对齐。
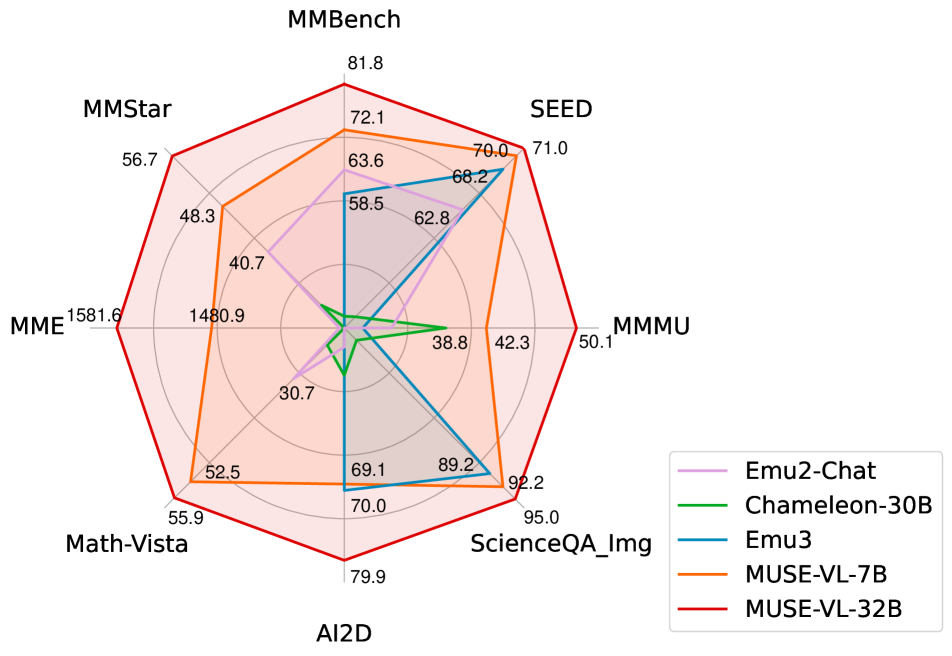
- 实验表明,MUSE-VL在理解和生成任务上均超越现有SOTA模型,尤其在理解任务上显著优于Emu3和LLaVA-NeXT。
📝 摘要(中文)
本文提出MUSE-VL,一个通过语义离散编码(Semantic Discrete Encoding, SDE)实现的统一视觉-语言模型,用于多模态理解和生成。近年来,研究界开始探索用于视觉生成和理解的统一模型。然而,现有的视觉标记器(例如VQGAN)仅考虑低级信息,这使得它们难以与语言标记对齐,导致高训练复杂性,并需要大量的训练数据才能达到最佳性能,并且其性能远低于专门的理解模型。本文提出的语义离散编码(SDE)通过向视觉标记器添加语义约束,有效地对齐视觉标记和语言标记的信息,从而大大减少了训练数据量,并提高了统一模型的性能。在相同的LLM规模下,我们的方法比之前的SOTA模型Emu3提高了4.8%的理解性能,并且超过了专门的理解模型LLaVA-NeXT 34B 3.7%。我们的模型还在视觉生成基准测试中超越了现有的统一模型。
🔬 方法详解
问题定义:现有视觉-语言统一模型在视觉表征学习方面存在瓶颈。具体来说,现有的视觉tokenizer,如VQGAN,主要关注像素级别的低级特征,缺乏高级语义信息的编码能力。这导致视觉token与语言token之间的语义鸿沟,使得模型难以有效地进行跨模态对齐和推理。此外,这种低级表征需要大量的训练数据才能勉强达到可接受的性能,并且最终性能仍然不如专门的视觉理解模型。
核心思路:MUSE-VL的核心思路是通过语义离散编码(SDE)弥合视觉和语言token之间的语义鸿沟。SDE的核心在于,在视觉tokenizer的训练过程中,引入语义约束,使得视觉token不仅包含低级视觉信息,还能够编码高级语义信息。这样,视觉token就能够更好地与语言token对齐,从而提高模型的跨模态理解和生成能力。
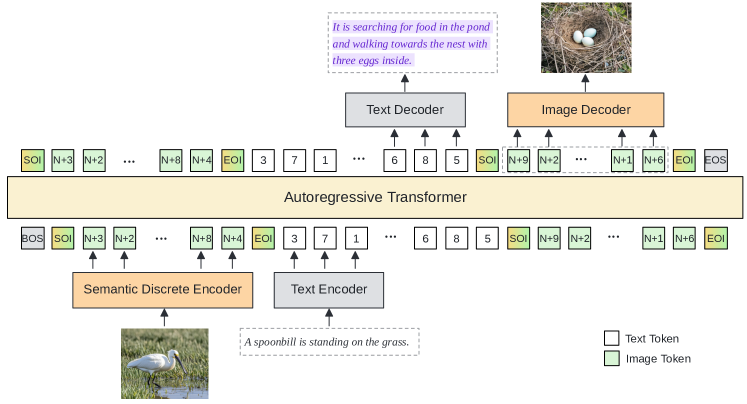
技术框架:MUSE-VL的整体框架包含一个视觉编码器、一个语义离散编码器(SDE)和一个大型语言模型(LLM)。首先,视觉编码器将输入图像转换为视觉特征。然后,SDE将这些视觉特征转换为语义离散token,这些token包含了图像的高级语义信息。最后,LLM将这些语义离散token与语言token一起处理,以完成各种视觉-语言任务,例如图像描述、视觉问答和图像生成。
关键创新:MUSE-VL最重要的技术创新点在于语义离散编码(SDE)。SDE通过在视觉tokenizer的训练过程中引入语义约束,使得视觉token能够编码高级语义信息。与传统的视觉tokenizer相比,SDE能够更好地对齐视觉和语言token,从而提高模型的跨模态理解和生成能力。
关键设计:SDE的关键设计包括以下几个方面:1) 使用对比学习来学习视觉token的语义表示。2) 使用KL散度损失来约束视觉token的分布,使其与语言token的分布更加接近。3) 使用一个可学习的码本(codebook)来将视觉特征量化为离散token。具体的参数设置和网络结构细节在论文中有详细描述,例如对比学习的温度系数、KL散度损失的权重等。
🖼️ 关键图片

📊 实验亮点
MUSE-VL在多个视觉-语言基准测试中取得了显著的性能提升。在理解任务上,与之前的SOTA模型Emu3相比,MUSE-VL提高了4.8%的性能,并且超过了专门的理解模型LLaVA-NeXT 34B 3.7%。在生成任务上,MUSE-VL也超越了现有的统一模型。这些结果表明,MUSE-VL提出的语义离散编码(SDE)能够有效地提高视觉-语言模型的性能。
🎯 应用场景
MUSE-VL具有广泛的应用前景,包括但不限于:智能客服、自动驾驶、医疗诊断、教育娱乐等领域。它可以用于构建更智能的视觉-语言交互系统,例如能够理解图像内容并回答用户问题的智能助手,或者能够根据用户指令生成图像的创意工具。该研究的突破将推动多模态人工智能的发展,实现更自然、更高效的人机交互。
📄 摘要(原文)
We introduce MUSE-VL, a Unified Vision-Language Model through Semantic discrete Encoding for multimodal understanding and generation. Recently, the research community has begun exploring unified models for visual generation and understanding. However, existing vision tokenizers (e.g., VQGAN) only consider low-level information, which makes it difficult to align with language tokens. This results in high training complexity and necessitates a large amount of training data to achieve optimal performance. Additionally, their performance is still far from dedicated understanding models. This paper proposes Semantic Discrete Encoding (SDE), which effectively aligns the information of visual tokens and language tokens by adding semantic constraints to the visual tokenizer. This greatly reduces the amount of training data and improves the performance of the unified model. With the same LLM size, our method improved the understanding performance by 4.8% compared to the previous SOTA Emu3 and surpassed the dedicated understanding model LLaVA-NeXT 34B by 3.7%. Our model also surpasses the existing unified models on visual generation benchmarks.