Video-Guided Foley Sound Generation with Multimodal Controls
作者: Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Nieto, David Bourgin, Andrew Owens, Justin Salamon
分类: cs.CV, cs.MM, cs.SD, eess.AS
发布日期: 2024-11-26 (更新: 2025-03-17)
备注: Accepted at CVPR 2025. Project site: https://ificl.github.io/MultiFoley/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MultiFoley:多模态控制的视频引导Foley音效生成模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频音效生成 多模态控制 Foley音效 音频生成 深度学习
📋 核心要点
- 现有视频音效生成方法缺乏对生成声音的灵活控制,难以产生艺术化的音效,与真实音源差异大。
- MultiFoley模型通过文本、音频和视频多模态条件控制,实现对生成音效的精细化和个性化定制。
- MultiFoley在混合数据集上进行联合训练,显著提升了生成音频的质量和同步性,超越了现有技术水平。
📝 摘要(中文)
本文提出了一种名为MultiFoley的模型,用于视频引导的音效生成,该模型支持通过文本、音频和视频进行多模态条件控制。给定一段无声视频和一段文本提示,MultiFoley允许用户创建干净的声音(例如,滑板轮子旋转而没有风噪声)或更奇特的声音(例如,使狮子的吼叫听起来像猫的喵叫)。MultiFoley还允许用户从音效(SFX)库或部分视频中选择参考音频进行条件控制。该模型的关键创新在于其在低质量音频的互联网视频数据集和专业SFX录音上的联合训练,从而能够生成高质量、全带宽(48kHz)的音频。通过自动评估和人工研究,证明MultiFoley成功地跨各种条件输入生成了同步的高质量声音,并且优于现有方法。
🔬 方法详解
问题定义:现有的视频音效生成方法通常难以生成具有艺术性和创造性的音效,并且缺乏对生成过程的灵活控制。用户难以根据自己的需求定制音效,例如,去除不想要的环境噪音,或者将一种声音的特征转移到另一种声音上。现有方法在生成高质量、全带宽的音频方面也存在挑战。
核心思路:MultiFoley的核心思路是利用多模态信息(视频、文本、音频)作为条件,引导生成器产生期望的音效。通过联合训练互联网视频数据和专业音效数据,模型能够学习到更丰富的音效知识,并生成更高质量的音频。这种多模态条件控制的设计允许用户更灵活地操纵生成过程,实现更具创造性的音效设计。
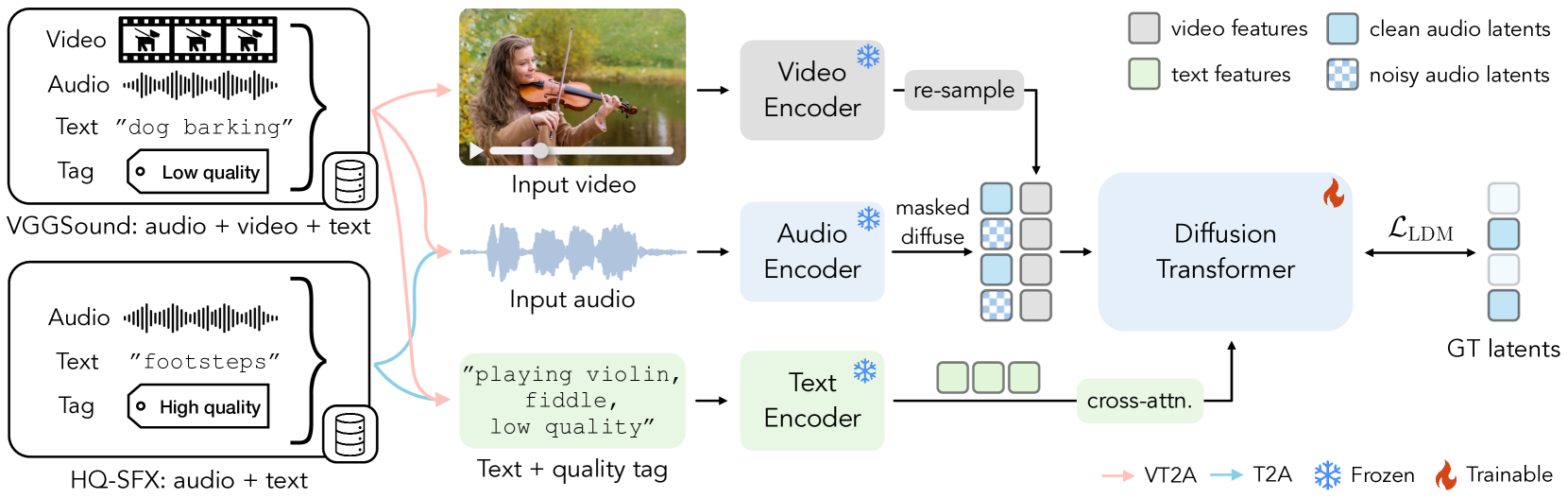
技术框架:MultiFoley的整体框架包含一个生成器网络和一个判别器网络。生成器以无声视频、文本提示和可选的参考音频作为输入,生成相应的音效。判别器则用于区分生成的音效和真实的音效,从而提高生成器的生成质量。模型在包含互联网视频和专业音效的数据集上进行联合训练。
关键创新:MultiFoley的关键创新在于其多模态条件控制和联合训练策略。多模态条件控制允许用户通过多种方式引导音效生成,从而实现更灵活的音效设计。联合训练策略则利用了互联网视频数据的丰富性和专业音效数据的高质量,从而提高了生成音频的质量和泛化能力。
关键设计:MultiFoley使用了Transformer架构作为生成器的核心模块,用于处理视频、文本和音频输入。损失函数包括对抗损失、重构损失和一致性损失,用于保证生成音频的质量、与输入视频的同步性以及与参考音频的一致性。模型生成48kHz的全带宽音频,保证了音效的细节和逼真度。
🖼️ 关键图片

📊 实验亮点
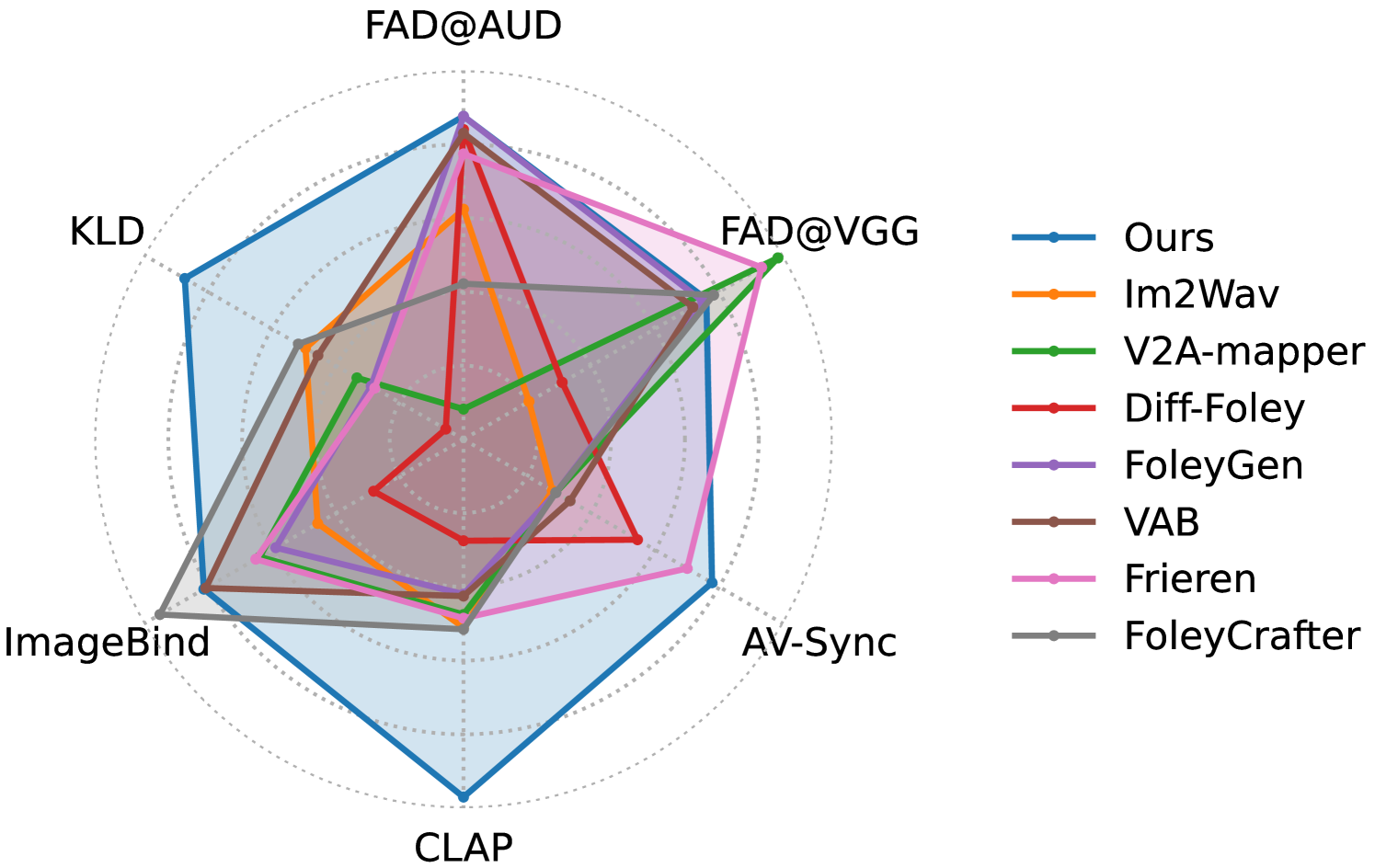
MultiFoley在自动评估和人工评估中均表现出色。自动评估指标显示,MultiFoley生成的音频在质量和同步性方面均优于现有方法。人工评估结果表明,用户更倾向于选择MultiFoley生成的音效,认为其更符合视频内容,更具艺术性。此外,MultiFoley能够生成48kHz的全带宽音频,显著提升了音效的听觉体验。
🎯 应用场景
MultiFoley可广泛应用于电影制作、游戏开发、虚拟现实等领域,为视频内容创作提供高质量、可定制的音效。它能够帮助音效设计师快速生成各种逼真或奇特的音效,提高工作效率,降低制作成本。未来,该技术有望进一步发展,实现更智能化的音效生成和编辑。
📄 摘要(原文)
Generating sound effects for videos often requires creating artistic sound effects that diverge significantly from real-life sources and flexible control in the sound design. To address this problem, we introduce MultiFoley, a model designed for video-guided sound generation that supports multimodal conditioning through text, audio, and video. Given a silent video and a text prompt, MultiFoley allows users to create clean sounds (e.g., skateboard wheels spinning without wind noise) or more whimsical sounds (e.g., making a lion's roar sound like a cat's meow). MultiFoley also allows users to choose reference audio from sound effects (SFX) libraries or partial videos for conditioning. A key novelty of our model lies in its joint training on both internet video datasets with low-quality audio and professional SFX recordings, enabling high-quality, full-bandwidth (48kHz) audio generation. Through automated evaluations and human studies, we demonstrate that MultiFoley successfully generates synchronized high-quality sounds across varied conditional inputs and outperforms existing methods. Please see our project page for video results: https://ificl.github.io/MultiFoley/