HyperSeg: Towards Universal Visual Segmentation with Large Language Model
作者: Cong Wei, Yujie Zhong, Haoxian Tan, Yong Liu, Zheng Zhao, Jie Hu, Yujiu Yang
分类: cs.CV
发布日期: 2024-11-26 (更新: 2024-12-02)
💡 一句话要点
HyperSeg:基于大语言模型的通用视觉分割模型,实现图像和视频的像素级理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通用分割 视觉大语言模型 图像理解 视频理解 像素级感知 推理感知 混合实体识别 细粒度视觉感知
📋 核心要点
- 现有统一分割方法在图像和视频场景适应性以及复杂推理分割方面存在局限,难以处理复杂指令。
- HyperSeg利用VLLM的推理能力,结合混合实体识别和细粒度视觉感知器模块,实现像素级通用分割。
- 实验结果表明,HyperSeg在通用图像和视频分割任务,特别是复杂推理感知任务中表现出色。
📝 摘要(中文)
本文旨在利用视觉大语言模型(VLLM)强大的推理能力,解决图像和视频感知的通用分割问题。尽管当前统一分割方法取得了显著进展,但在适应图像和视频场景以及复杂推理分割方面存在局限性,难以处理各种具有挑战性的指令,并实现对细粒度视觉-语言相关性的准确理解。我们提出了HyperSeg,这是第一个基于VLLM的通用分割模型,用于像素级的图像和视频感知,涵盖通用分割任务和需要强大推理能力和世界知识的更复杂的推理感知任务。此外,为了充分利用VLLM的识别能力和细粒度的视觉信息,HyperSeg集成了混合实体识别和细粒度视觉感知器模块,用于各种分割任务。结合时间适配器,HyperSeg实现了对时间信息的全面理解。实验结果验证了我们的见解在解决通用图像和视频分割任务(包括更复杂的推理感知任务)中的有效性。我们的代码已开源。
🔬 方法详解
问题定义:现有统一分割方法难以同时处理图像和视频,并且在处理需要复杂推理的分割任务时表现不佳。它们无法充分理解细粒度的视觉-语言关联,导致在处理复杂指令时精度不足。
核心思路:HyperSeg的核心思路是利用视觉大语言模型(VLLM)强大的推理能力和世界知识,结合专门设计的视觉感知模块,实现对图像和视频的像素级通用分割。通过VLLM进行高级语义理解和推理,并利用视觉感知模块提取细粒度的视觉特征,从而克服现有方法的局限性。
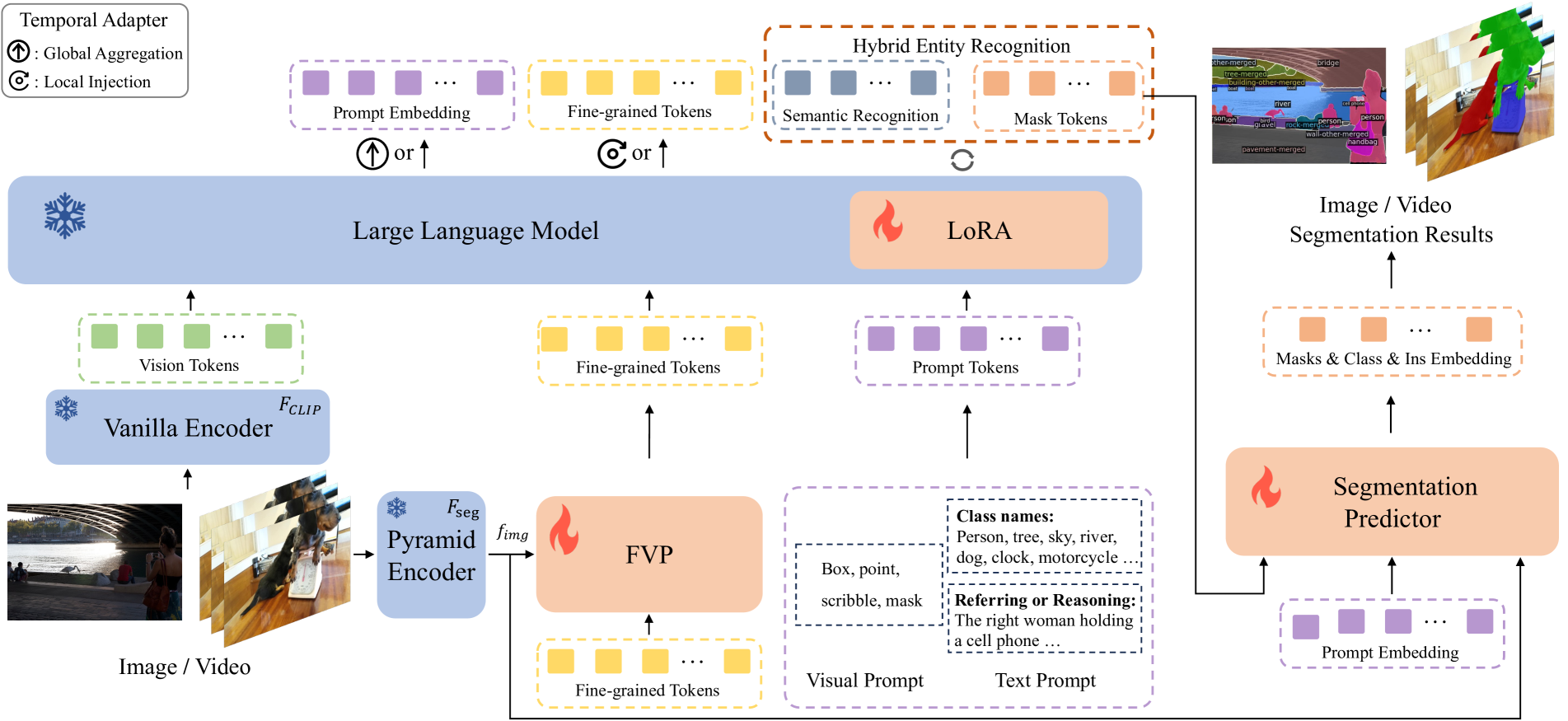
技术框架:HyperSeg的整体架构包含以下几个主要模块:1) VLLM:负责高级语义理解和推理。2) 混合实体识别模块:用于识别图像或视频中的实体。3) 细粒度视觉感知器模块:用于提取细粒度的视觉特征。4) 时间适配器:用于处理视频中的时间信息。整个流程是,首先将图像或视频输入VLLM进行初步理解,然后通过混合实体识别和细粒度视觉感知器模块提取视觉特征,最后结合时间适配器处理时间信息,最终输出像素级的分割结果。
关键创新:HyperSeg的关键创新在于将VLLM引入通用分割任务,并结合专门设计的视觉感知模块,实现了对图像和视频的像素级理解。与现有方法相比,HyperSeg能够处理更复杂的推理任务,并更好地理解细粒度的视觉-语言关联。
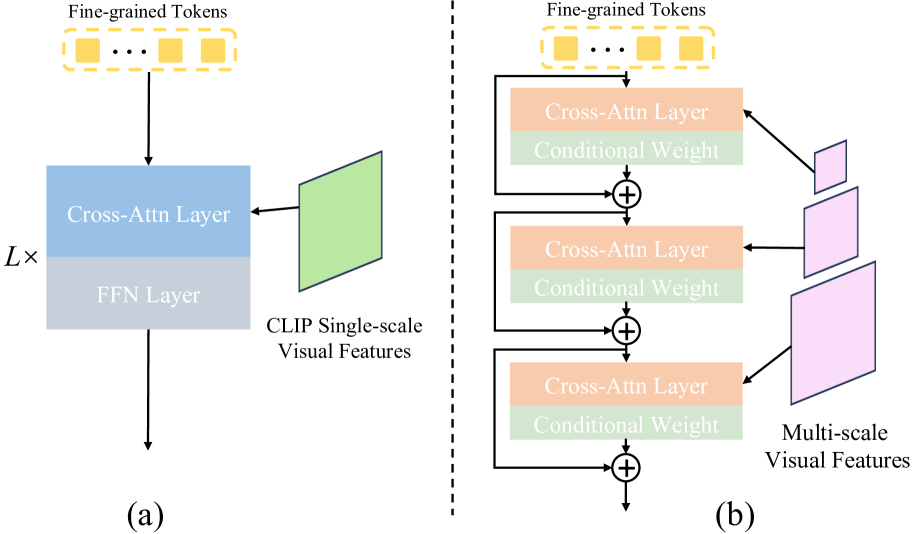
关键设计:HyperSeg的关键设计包括:1) 混合实体识别模块的设计,用于识别图像或视频中的实体。2) 细粒度视觉感知器模块的设计,用于提取细粒度的视觉特征。3) 时间适配器的设计,用于处理视频中的时间信息。这些模块的设计都旨在充分利用VLLM的推理能力和视觉信息的细粒度特征。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了HyperSeg在通用图像和视频分割任务中的有效性,包括更复杂的推理感知任务。具体性能数据和对比基线在论文中给出,表明HyperSeg在各种分割任务上都取得了显著的提升。实验结果证明了VLLM在通用分割任务中的潜力,并为未来的研究提供了新的方向。
🎯 应用场景
HyperSeg具有广泛的应用前景,包括自动驾驶、智能监控、医疗影像分析、视频编辑等领域。它可以用于识别和分割图像和视频中的各种物体和场景,从而实现更智能的视觉感知和理解。未来,HyperSeg可以进一步扩展到更多的应用场景,例如虚拟现实、增强现实等。
📄 摘要(原文)
This paper aims to address universal segmentation for image and video perception with the strong reasoning ability empowered by Visual Large Language Models (VLLMs). Despite significant progress in current unified segmentation methods, limitations in adaptation to both image and video scenarios, as well as the complex reasoning segmentation, make it difficult for them to handle various challenging instructions and achieve an accurate understanding of fine-grained vision-language correlations. We propose HyperSeg, the first VLLM-based universal segmentation model for pixel-level image and video perception, encompassing generic segmentation tasks and more complex reasoning perception tasks requiring powerful reasoning abilities and world knowledge. Besides, to fully leverage the recognition capabilities of VLLMs and the fine-grained visual information, HyperSeg incorporates hybrid entity recognition and fine-grained visual perceiver modules for various segmentation tasks. Combined with the temporal adapter, HyperSeg achieves a comprehensive understanding of temporal information. Experimental results validate the effectiveness of our insights in resolving universal image and video segmentation tasks, including the more complex reasoning perception tasks. Our code is available.