FTMoMamba: Motion Generation with Frequency and Text State Space Models
作者: Chengjian Li, Xiangbo Shu, Qiongjie Cui, Yazhou Yao, Jinhui Tang
分类: cs.CV
发布日期: 2024-11-26
备注: 8 pages, 6 figures
💡 一句话要点
FTMoMamba:利用频率和文本状态空间模型进行运动生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 文本到运动生成 扩散模型 状态空间模型 频域分析 运动捕捉
📋 核心要点
- 现有运动生成方法忽略了频域信息的重要性,难以捕捉细粒度运动。
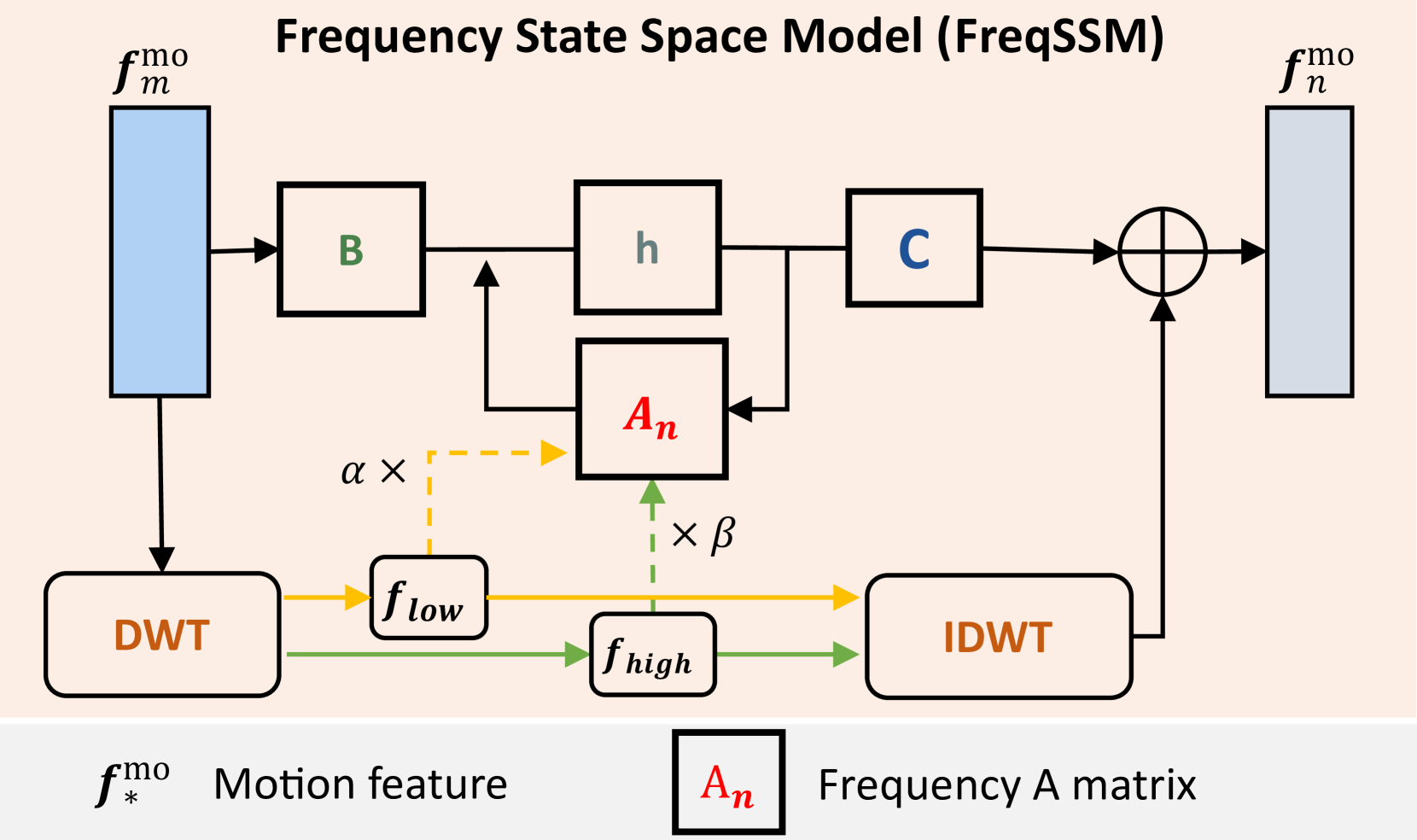
- FTMoMamba通过FreqSSM分解序列频率,分别生成静态姿势和细粒度运动,学习细粒度表示。
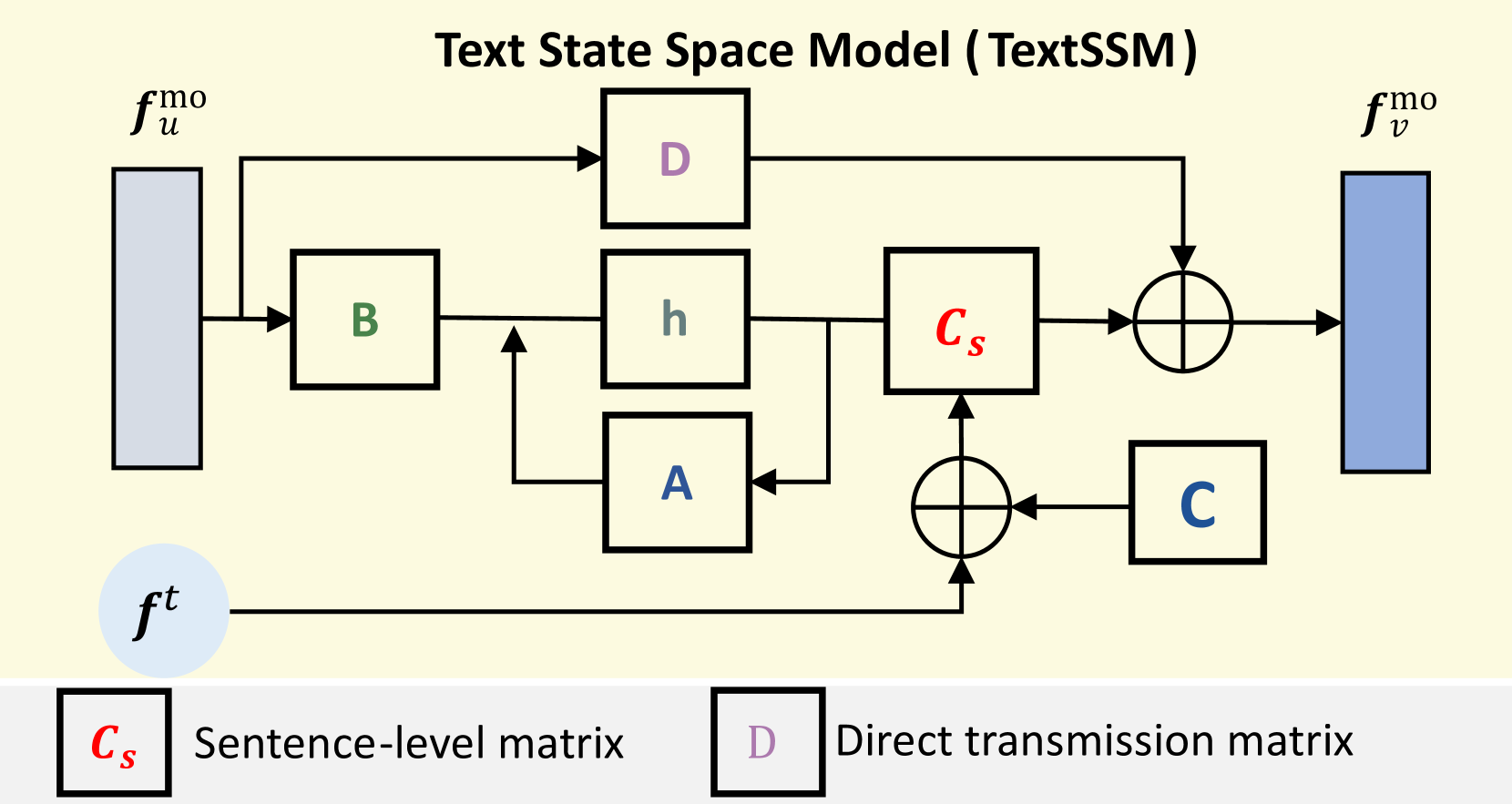
- TextSSM在句子级别编码文本特征,对齐文本语义与序列特征,保证文本和运动一致性。
📝 摘要(中文)
扩散模型在人体运动生成方面取得了显著成果。然而,现有方法通常忽略了频域信息在捕捉潜在空间中细粒度运动的重要性(例如,低频对应静态姿势,高频对应细粒度运动)。此外,文本和运动之间存在语义差异,导致生成的运动与文本描述不一致。本文提出了一种新的基于扩散的FTMoMamba框架,该框架配备了频率状态空间模型(FreqSSM)和文本状态空间模型(TextSSM)。具体而言,为了学习细粒度表示,FreqSSM将序列分解为低频和高频分量,分别指导静态姿势(例如,坐、躺)和细粒度运动(例如,过渡、绊倒)的生成。为了确保文本和运动之间的一致性,TextSSM在句子级别编码文本特征,将文本语义与序列特征对齐。大量实验表明,FTMoMamba在文本到运动生成任务上取得了优异的性能,尤其是在HumanML3D数据集上获得了最低的FID,为0.181(远低于MLD的0.421)。
🔬 方法详解
问题定义:现有文本到运动生成方法难以捕捉运动中的细粒度信息,并且生成的运动与文本描述之间存在语义不一致的问题。现有方法没有充分利用运动序列的频域信息,并且缺乏有效的文本和运动特征对齐机制。
核心思路:论文的核心思路是将运动序列分解为不同的频率分量,利用频率状态空间模型(FreqSSM)分别处理低频和高频分量,从而更好地捕捉静态姿势和细粒度运动。同时,使用文本状态空间模型(TextSSM)在句子级别编码文本特征,并将文本语义与运动序列特征对齐,以确保生成运动与文本描述的一致性。
技术框架:FTMoMamba框架基于扩散模型,包含以下主要模块:1) FreqSSM:将运动序列分解为低频和高频分量,并分别进行建模。2) TextSSM:在句子级别编码文本特征。3) 扩散模型:利用FreqSSM和TextSSM提取的特征,生成运动序列。整体流程为:首先,使用TextSSM编码文本描述;然后,使用FreqSSM处理运动序列;最后,利用扩散模型生成与文本描述相符的运动序列。
关键创新:论文的关键创新在于提出了FreqSSM和TextSSM。FreqSSM能够有效地捕捉运动序列中的频域信息,从而更好地生成细粒度运动。TextSSM能够有效地对齐文本语义和运动序列特征,从而确保生成运动与文本描述的一致性。与现有方法相比,FTMoMamba能够更好地捕捉运动中的细粒度信息,并生成与文本描述更加一致的运动。
关键设计:FreqSSM使用状态空间模型来建模不同频率分量的运动序列。TextSSM使用Transformer网络来编码文本特征。扩散模型使用U-Net结构,并结合FreqSSM和TextSSM提取的特征进行运动生成。损失函数包括扩散模型的损失函数和文本-运动对齐的损失函数。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
FTMoMamba在HumanML3D数据集上取得了显著的性能提升,获得了最低的FID分数0.181,远低于MLD的0.421。这表明FTMoMamba能够生成更加逼真和自然的运动序列,并且与文本描述更加一致。实验结果验证了FreqSSM和TextSSM的有效性,以及FTMoMamba在文本到运动生成任务上的优越性。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、动画制作等领域,实现更加逼真和自然的虚拟人物运动生成。通过文本描述驱动人物运动,可以极大地提高内容创作的效率和灵活性,并为用户提供更加个性化的互动体验。未来,该技术有望应用于机器人控制领域,实现机器人根据自然语言指令执行复杂动作。
📄 摘要(原文)
Diffusion models achieve impressive performance in human motion generation. However, current approaches typically ignore the significance of frequency-domain information in capturing fine-grained motions within the latent space (e.g., low frequencies correlate with static poses, and high frequencies align with fine-grained motions). Additionally, there is a semantic discrepancy between text and motion, leading to inconsistency between the generated motions and the text descriptions. In this work, we propose a novel diffusion-based FTMoMamba framework equipped with a Frequency State Space Model (FreqSSM) and a Text State Space Model (TextSSM). Specifically, to learn fine-grained representation, FreqSSM decomposes sequences into low-frequency and high-frequency components, guiding the generation of static pose (e.g., sits, lay) and fine-grained motions (e.g., transition, stumble), respectively. To ensure the consistency between text and motion, TextSSM encodes text features at the sentence level, aligning textual semantics with sequential features. Extensive experiments show that FTMoMamba achieves superior performance on the text-to-motion generation task, especially gaining the lowest FID of 0.181 (rather lower than 0.421 of MLD) on the HumanML3D dataset.