ShowUI: One Vision-Language-Action Model for GUI Visual Agent
作者: Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, Mike Zheng Shou
分类: cs.CV, cs.AI, cs.CL, cs.HC
发布日期: 2024-11-26
备注: Technical Report. Github: https://github.com/showlab/ShowUI
🔗 代码/项目: GITHUB
💡 一句话要点
提出ShowUI,一个用于GUI视觉代理的视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI视觉代理 视觉-语言-动作模型 UI引导Token选择 交错信息流 指令跟随 零样本学习 人机交互
📋 核心要点
- 现有GUI代理主要依赖文本信息,缺乏对UI视觉信息的有效利用,限制了其在真实场景中的应用。
- ShowUI通过UI引导的视觉Token选择、交错的视觉-语言-动作流等创新,提升模型对GUI视觉信息的理解和利用能力。
- 实验表明,ShowUI在零样本屏幕截图定位任务上取得了75.1%的准确率,并在多个导航环境中表现出优越的性能。
📝 摘要(中文)
构建图形用户界面(GUI)助手对于提高人类工作流程的生产力具有重要意义。虽然大多数代理是基于语言的,依赖于具有富文本元信息(例如,HTML或可访问性树)的闭源API,但它们在像人类一样感知UI视觉方面存在局限性,突出了对GUI视觉代理的需求。本文开发了一个数字世界的视觉-语言-动作模型,即ShowUI,它具有以下创新:(i)UI引导的视觉Token选择,通过将屏幕截图公式化为UI连接图来降低计算成本,自适应地识别它们的冗余关系,并作为自注意力模块期间Token选择的标准;(ii)交错的视觉-语言-动作流,灵活地统一GUI任务中的各种需求,从而能够有效地管理导航中的视觉-动作历史记录或每个屏幕截图配对多轮查询-动作序列,以提高训练效率;(iii)通过仔细的数据管理和采用重采样策略来解决显著的数据类型不平衡问题,从而构建小规模高质量的GUI指令跟随数据集。凭借上述组件,ShowUI,一个使用256K数据的轻量级2B模型,在零样本屏幕截图定位中实现了强大的75.1%的准确率。它的UI引导的Token选择进一步减少了训练期间33%的冗余视觉Token,并将性能提高了1.4倍。在Web Mind2Web、移动AITW和在线MiniWob环境中的导航实验进一步强调了我们的模型在推进GUI视觉代理方面的有效性和潜力。模型可在https://github.com/showlab/ShowUI获取。
🔬 方法详解
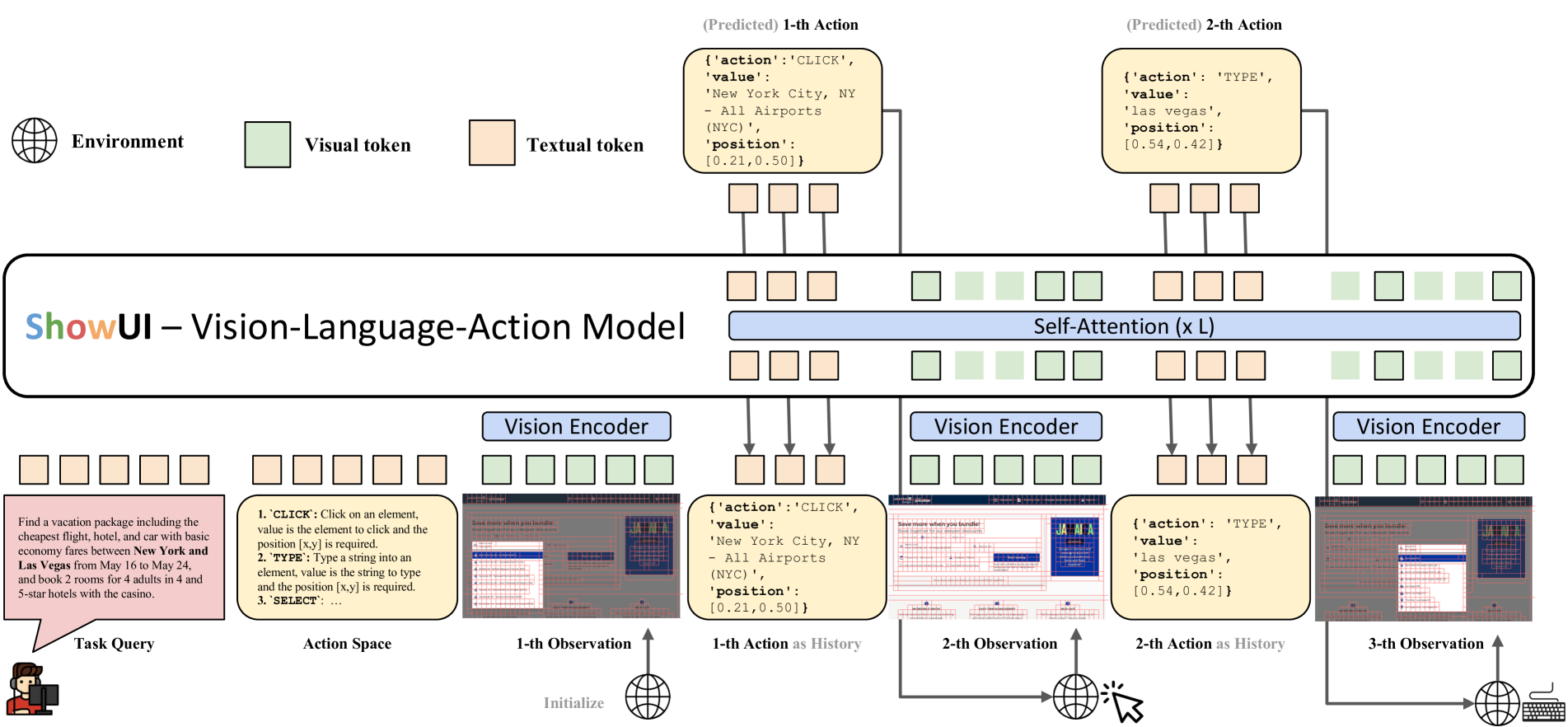
问题定义:现有GUI代理主要依赖于文本信息(如HTML或可访问性树),而忽略了UI的视觉信息,导致其在理解和操作GUI界面时存在局限性。这些方法无法像人类一样直接“看到”和理解屏幕上的元素,从而影响了其泛化能力和鲁棒性。
核心思路:ShowUI的核心思路是构建一个能够有效利用GUI视觉信息的视觉-语言-动作模型。它通过将屏幕截图表示为UI连接图,并利用UI结构来指导视觉Token的选择,从而降低计算成本并提高模型对关键视觉信息的关注。同时,采用交错的视觉-语言-动作流,使模型能够更好地管理历史信息,并提高训练效率。
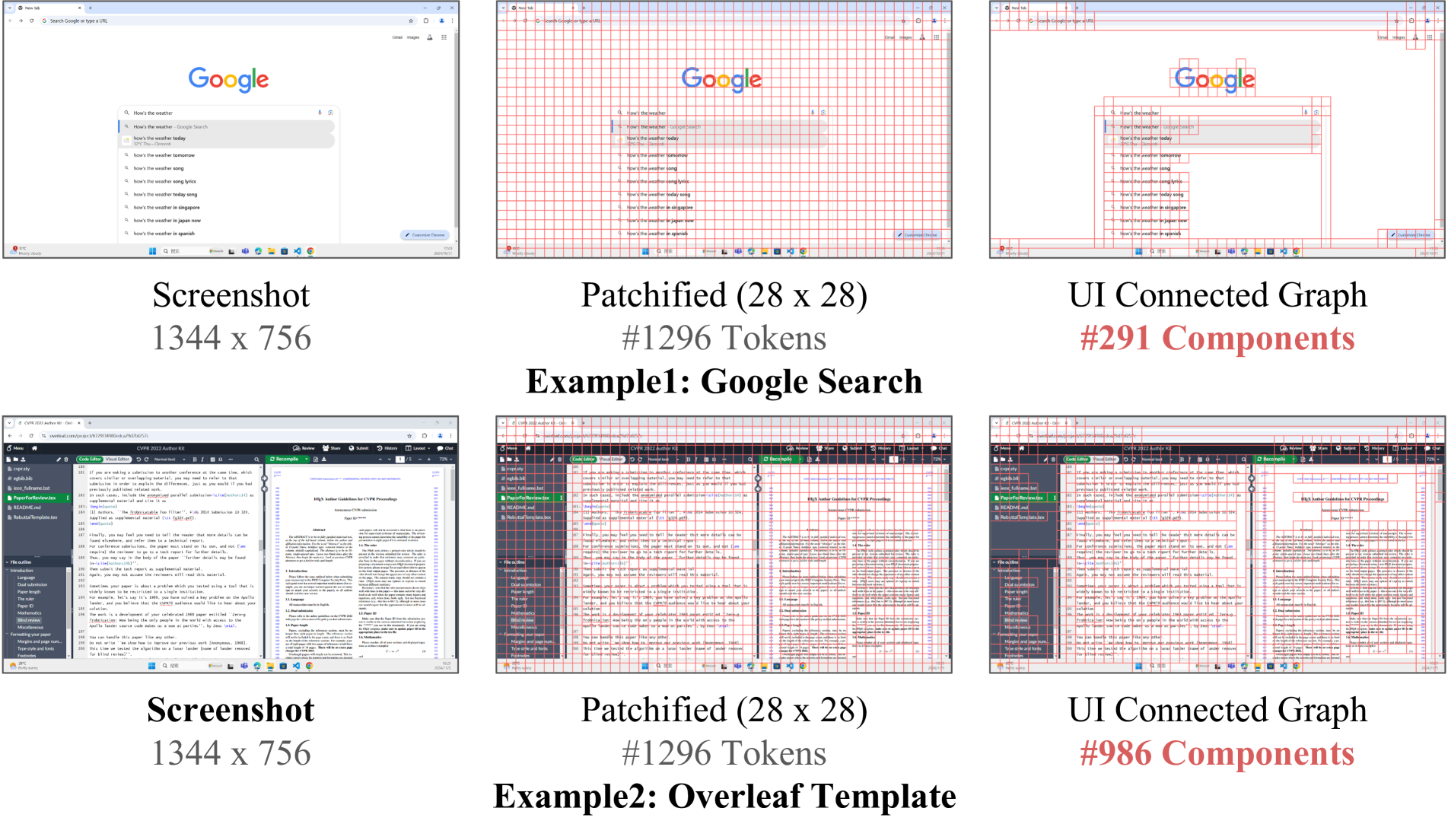
技术框架:ShowUI的整体框架包含以下几个主要模块:1) UI连接图构建模块:将屏幕截图解析为UI连接图,表示UI元素之间的关系。2) UI引导的视觉Token选择模块:根据UI连接图,自适应地选择重要的视觉Token,减少冗余信息。3) 交错的视觉-语言-动作流模块:将视觉、语言和动作信息交错输入模型,实现多轮交互和历史信息管理。4) 视觉-语言-动作模型:基于Transformer架构,融合视觉、语言和动作信息,预测下一步动作。
关键创新:ShowUI的关键创新在于:1) UI引导的视觉Token选择:通过利用UI结构信息,自适应地选择重要的视觉Token,降低计算成本,提高模型效率。2) 交错的视觉-语言-动作流:通过交错输入视觉、语言和动作信息,使模型能够更好地管理历史信息,并支持多轮交互。3) 小规模高质量数据集:通过精心的数据管理和重采样策略,构建了小规模但高质量的GUI指令跟随数据集,提高了模型的训练效率和泛化能力。
关键设计:在UI引导的视觉Token选择中,使用UI连接图来指导Token的选择,保留与UI元素相关的Token,并过滤掉冗余的背景Token。在交错的视觉-语言-动作流中,将视觉、语言和动作信息以交错的方式输入Transformer模型,并使用特殊的Token来区分不同类型的信息。模型采用2B参数规模,使用256K数据进行训练。损失函数包括动作预测损失和语言生成损失。
🖼️ 关键图片

📊 实验亮点
ShowUI在零样本屏幕截图定位任务上取得了75.1%的准确率,显著优于现有方法。UI引导的Token选择减少了33%的冗余视觉Token,并将性能提高了1.4倍。在Web Mind2Web、移动AITW和在线MiniWob等多个导航环境中,ShowUI也表现出优越的性能。
🎯 应用场景
ShowUI在自动化测试、智能助手、无障碍辅助等领域具有广泛的应用前景。它可以用于自动执行GUI操作,例如填写表单、搜索信息等,从而提高工作效率。此外,ShowUI还可以为残疾人士提供辅助功能,例如通过语音或手势控制GUI界面。
📄 摘要(原文)
Building Graphical User Interface (GUI) assistants holds significant promise for enhancing human workflow productivity. While most agents are language-based, relying on closed-source API with text-rich meta-information (e.g., HTML or accessibility tree), they show limitations in perceiving UI visuals as humans do, highlighting the need for GUI visual agents. In this work, we develop a vision-language-action model in digital world, namely ShowUI, which features the following innovations: (i) UI-Guided Visual Token Selection to reduce computational costs by formulating screenshots as an UI connected graph, adaptively identifying their redundant relationship and serve as the criteria for token selection during self-attention blocks; (ii) Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency; (iii) Small-scale High-quality GUI Instruction-following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances. With above components, ShowUI, a lightweight 2B model using 256K data, achieves a strong 75.1% accuracy in zero-shot screenshot grounding. Its UI-guided token selection further reduces 33% of redundant visual tokens during training and speeds up the performance by 1.4x. Navigation experiments across web Mind2Web, mobile AITW, and online MiniWob environments further underscore the effectiveness and potential of our model in advancing GUI visual agents. The models are available at https://github.com/showlab/ShowUI.