FLEX-CLIP: Feature-Level GEneration Network Enhanced CLIP for X-shot Cross-modal Retrieval
作者: Jingyou Xie, Jiayi Kuang, Zhenzhou Lin, Jiarui Ouyang, Zishuo Zhao, Ying Shen
分类: cs.CV, cs.CL
发布日期: 2024-11-26
💡 一句话要点
提出FLEX-CLIP,通过特征生成网络增强CLIP,解决X-shot跨模态检索中的特征退化和数据不平衡问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨模态检索 小样本学习 特征生成 VAE-GAN CLIP 特征融合 门控残差网络
📋 核心要点
- 现有小样本跨模态检索方法在目标域中存在特征退化,且面临严重的数据不平衡问题,影响检索性能。
- FLEX-CLIP通过多模态VAE-GAN生成伪样本缓解数据不平衡,并使用门控残差网络融合特征,减少特征退化。
- 实验结果表明,FLEX-CLIP在四个基准数据集上取得了显著提升,性能超越现有最优方法7%-15%。
📝 摘要(中文)
本文提出了一种新颖的特征级生成网络增强CLIP模型,名为FLEX-CLIP,用于解决小样本跨模态检索(CMR)问题。该问题是指在目标域包含与源域不相交的类别的情况下,从一种模态的查询中检索另一种模态中语义相似的实例。与经典的小样本CMR方法相比,像CLIP这样的视觉-语言预训练方法已经显示出良好的小样本或零样本学习性能。然而,它们仍然面临着目标域中的特征退化和极端的数据不平衡等挑战。为了解决这些问题,FLEX-CLIP包括两个训练阶段。在多模态特征生成阶段,我们提出了一个复合多模态VAE-GAN网络,以捕获真实的特征分布模式,并基于CLIP特征生成伪样本,从而解决数据不平衡问题。在公共空间投影阶段,我们开发了一个门控残差网络,将CLIP特征与投影特征融合,从而减少X-shot场景中的特征退化。在四个基准数据集上的实验结果表明,该方法比最先进的方法提高了7%-15%,消融研究表明增强了CLIP特征。
🔬 方法详解
问题定义:论文旨在解决小样本跨模态检索(X-shot CMR)中,由于目标域数据有限且类别与源域不同,导致CLIP等预训练模型在目标域上特征表达能力下降的问题。现有的方法难以有效应对目标域的特征退化和数据不平衡,限制了检索精度。
核心思路:论文的核心思路是通过特征生成来缓解数据不平衡,并利用特征融合来减少特征退化。具体来说,使用VAE-GAN生成与真实数据分布相似的伪样本,增加训练数据,并设计门控残差网络融合原始CLIP特征和投影特征,保留更多原始信息。
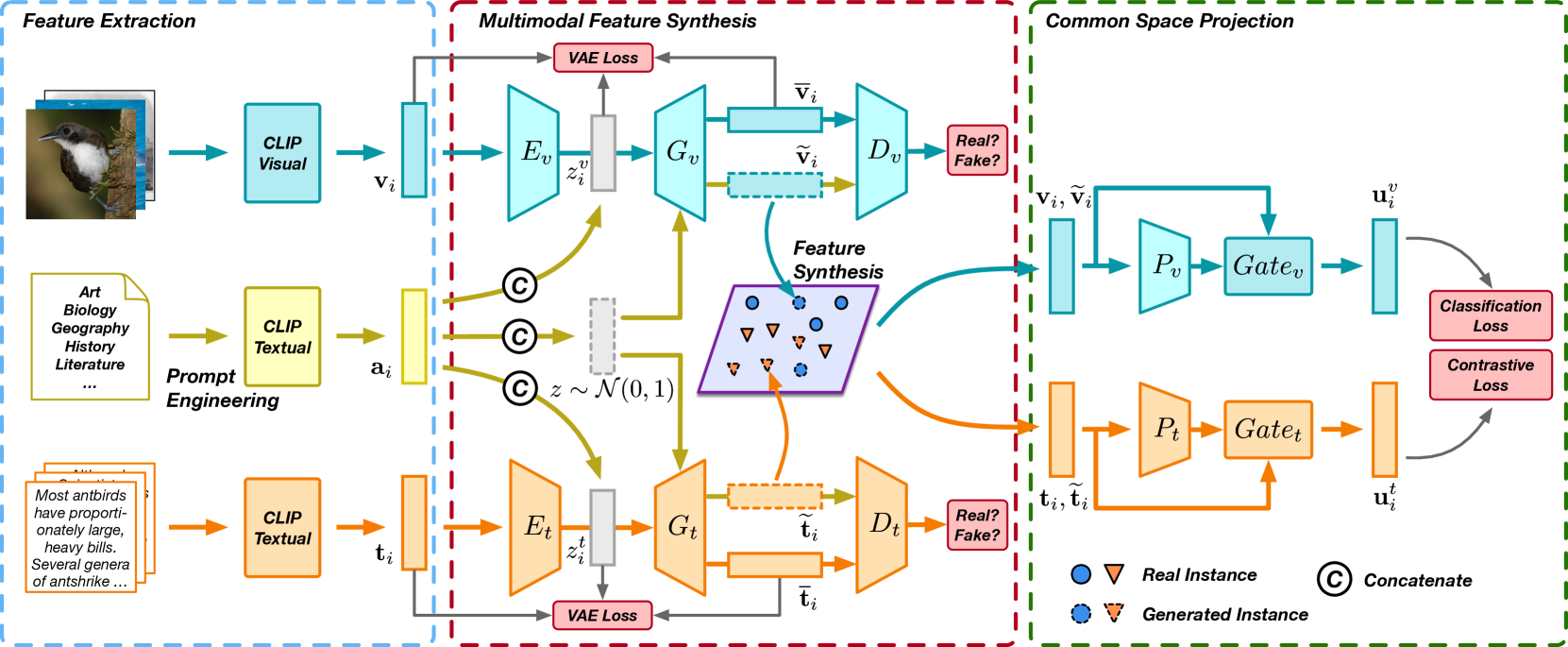
技术框架:FLEX-CLIP包含两个主要训练阶段:多模态特征生成和公共空间投影。在多模态特征生成阶段,使用复合多模态VAE-GAN网络,以CLIP特征为基础生成伪样本。在公共空间投影阶段,使用门控残差网络将CLIP特征与投影特征进行融合。整体流程是先通过VAE-GAN进行数据增强,然后通过门控残差网络进行特征融合和投影,最后进行检索。
关键创新:论文的关键创新在于提出了一个复合多模态VAE-GAN网络用于特征生成,以及一个门控残差网络用于特征融合。与传统的数据增强方法相比,VAE-GAN能够生成更逼真的伪样本,更好地模拟真实数据分布。门控残差网络能够自适应地融合原始CLIP特征和投影特征,避免信息丢失。
关键设计:VAE-GAN的具体结构未知,但强调了其复合多模态的特性,可能包含多个编码器和解码器,分别处理不同模态的特征。门控残差网络使用门控机制来控制CLIP特征和投影特征的融合比例,具体门控函数的选择未知。损失函数的设计也未知,但可能包含对抗损失、重构损失和检索损失等。
🖼️ 关键图片

📊 实验亮点
FLEX-CLIP在四个基准数据集上取得了显著的性能提升,相较于现有最优方法,性能提升了7%-15%。消融实验证明了多模态特征生成和门控残差网络对CLIP特征的增强作用。这些结果表明FLEX-CLIP能够有效缓解特征退化和数据不平衡问题,提升小样本跨模态检索的准确率。
🎯 应用场景
该研究成果可应用于图像-文本跨模态检索、视频-文本跨模态检索等领域,例如在电商平台中,用户可以通过上传一张商品图片来搜索相关的文本描述或商品信息。该方法在数据稀缺场景下具有重要价值,可以提升检索系统的智能化水平和用户体验。
📄 摘要(原文)
Given a query from one modality, few-shot cross-modal retrieval (CMR) retrieves semantically similar instances in another modality with the target domain including classes that are disjoint from the source domain. Compared with classical few-shot CMR methods, vision-language pretraining methods like CLIP have shown great few-shot or zero-shot learning performance. However, they still suffer challenges due to (1) the feature degradation encountered in the target domain and (2) the extreme data imbalance. To tackle these issues, we propose FLEX-CLIP, a novel Feature-level Generation Network Enhanced CLIP. FLEX-CLIP includes two training stages. In multimodal feature generation, we propose a composite multimodal VAE-GAN network to capture real feature distribution patterns and generate pseudo samples based on CLIP features, addressing data imbalance. For common space projection, we develop a gate residual network to fuse CLIP features with projected features, reducing feature degradation in X-shot scenarios. Experimental results on four benchmark datasets show a 7%-15% improvement over state-of-the-art methods, with ablation studies demonstrating enhancement of CLIP features.