DWCL: Dual-Weighted Contrastive Learning for Multi-View Clustering
作者: Hanning Yuan, Zhihui Zhang, Qi Guo, Lianhua Chi, Sijie Ruan, Jinhui Pang, Xiaoshuai Hao
分类: cs.CV, cs.LG
发布日期: 2024-11-26 (更新: 2025-01-23)
💡 一句话要点
提出双重加权对比学习(DWCL)用于解决多视图聚类中的表示退化和不可靠视图问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多视图聚类 对比学习 表示学习 双重加权 最佳-其他对比 视图质量 视图差异
📋 核心要点
- 现有MVCC方法生成大量不可靠的跨视图配对,且忽略多视图表示差异,导致表示退化。
- 提出双重加权对比学习(DWCL),通过最佳-其他(B-O)对比机制和双重加权策略来解决上述问题。
- 实验结果表明,DWCL在多个数据集上优于现有方法,在准确率和鲁棒性方面均有显著提升。
📝 摘要(中文)
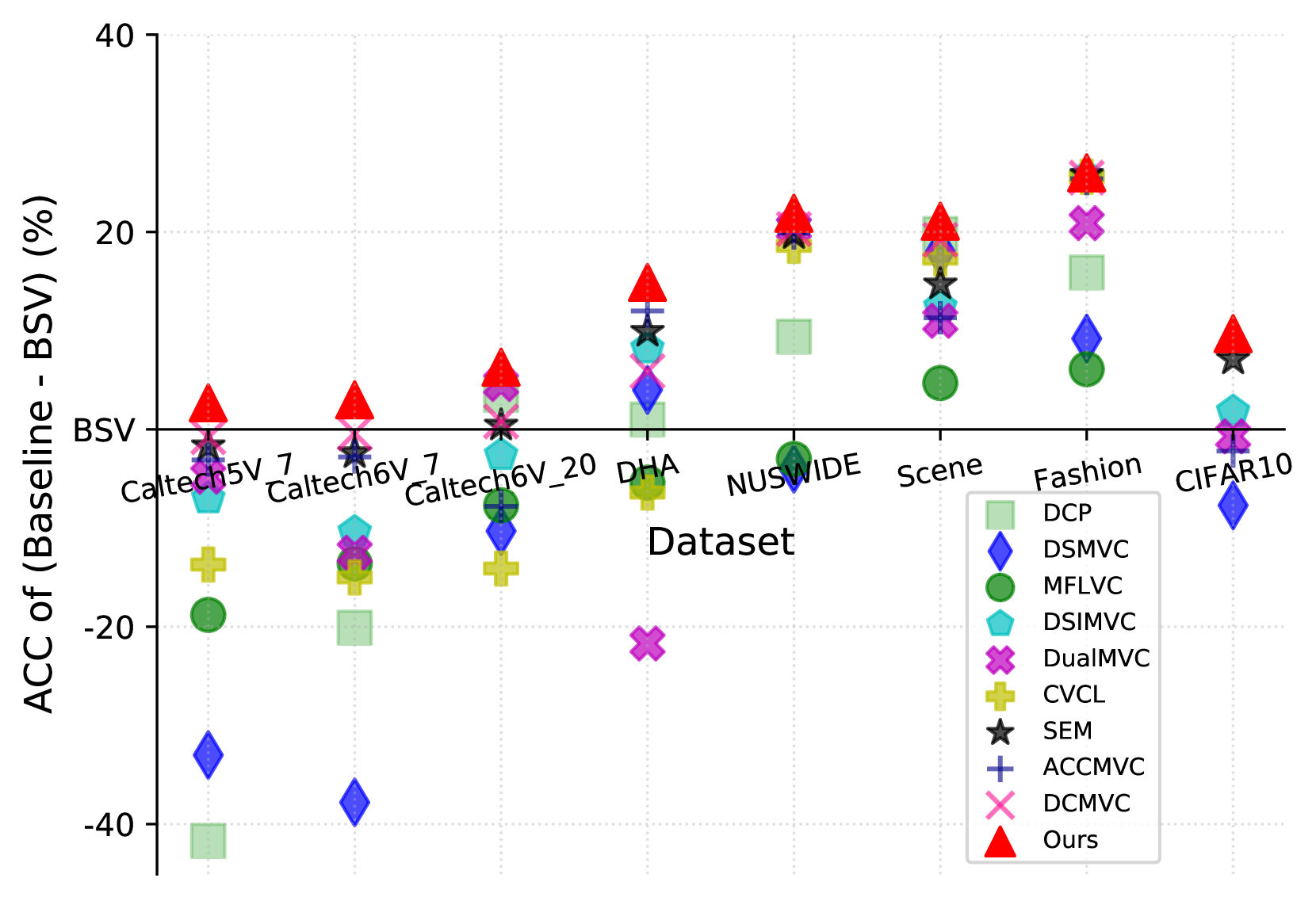
多视图对比聚类(MVCC)通过对比学习从多个视图中生成一致的聚类结构,受到了广泛关注。然而,现有的大多数MVCC方法通过组合任意两个视图来创建跨视图,导致大量不可靠的配对。此外,这些方法通常忽略多视图表示中的差异,从而导致表示退化。为了解决这些挑战,我们提出了一种名为双重加权对比学习(DWCL)的新模型用于多视图聚类。具体来说,为了减少不可靠跨视图的影响,我们引入了一种创新的最佳-其他(B-O)对比机制,以低计算成本增强单个视图的表示。此外,我们开发了一种双重加权策略,该策略结合了反映每个视图质量的视图质量权重和视图差异权重。这种方法通过降低质量低且差异大的跨视图的权重,有效地减轻了表示退化。我们从理论上验证了B-O对比机制的效率和双重加权策略的有效性。大量的实验表明,DWCL在八个多视图数据集上优于以前的方法,展示了MVCC中卓越的性能和鲁棒性。具体而言,与Caltech6V7和MSRCv1数据集上的最先进方法相比,我们的方法分别实现了5.4%和5.6%的绝对准确率提升。
🔬 方法详解
问题定义:现有的多视图对比聚类方法在构建跨视图对比时,通常采用任意两两组合的方式,导致产生大量质量较差、信息不相关的跨视图样本对,影响聚类效果。此外,现有方法往往忽略了不同视图之间的差异性,容易导致表示退化问题,即所有视图学习到相似但可能不准确的表示。
核心思路:DWCL的核心在于通过双重加权策略来缓解不可靠跨视图和表示退化问题。首先,采用Best-Other (B-O)对比机制,避免直接使用所有视图组合,而是选择与每个视图最相关的其他视图进行对比学习。其次,引入双重权重,同时考虑视图的质量和视图之间的差异性,对跨视图对比学习过程进行加权,从而降低低质量和高差异视图的影响。
技术框架:DWCL的整体框架包含以下几个主要模块:1) 特征提取模块:对每个视图的数据进行特征提取,得到多视图表示。2) B-O对比学习模块:利用B-O机制,为每个视图选择最佳的对比视图,并进行对比学习,增强单个视图的表示。3) 双重加权模块:计算视图质量权重和视图差异权重,并将其结合起来,得到最终的跨视图权重。4) 聚类模块:利用学习到的多视图表示进行聚类。
关键创新:DWCL的关键创新在于:1) 提出了Best-Other (B-O)对比机制,有效减少了不可靠跨视图的影响,降低了计算成本。2) 提出了双重加权策略,同时考虑视图质量和视图差异,缓解了表示退化问题。
关键设计:B-O对比机制通过计算视图之间的相似度来选择最佳对比视图。视图质量权重通过视图表示的方差来衡量,方差越大表示视图质量越高。视图差异权重通过计算视图表示之间的距离来衡量,距离越大表示视图差异越大。损失函数由对比学习损失和聚类损失组成,通过联合优化来学习多视图表示和聚类结构。
🖼️ 关键图片


📊 实验亮点
DWCL在八个多视图数据集上进行了广泛的实验,结果表明其性能优于现有的多视图聚类方法。在Caltech6V7和MSRCv1数据集上,DWCL分别实现了5.4%和5.6%的绝对准确率提升,证明了其在多视图聚类任务中的优越性和鲁棒性。
🎯 应用场景
DWCL可应用于各种多视图数据分析任务,例如图像聚类、文本聚类、社交网络分析等。通过有效利用多视图信息,DWCL能够提高聚类性能,发现隐藏在多源异构数据中的潜在模式,为决策提供支持。该方法在医疗诊断、金融风控、智能推荐等领域具有广阔的应用前景。
📄 摘要(原文)
Multi-view contrastive clustering (MVCC) has gained significant attention for generating consistent clustering structures from multiple views through contrastive learning. However, most existing MVCC methods create cross-views by combining any two views, leading to a high volume of unreliable pairs. Furthermore, these approaches often overlook discrepancies in multi-view representations, resulting in representation degeneration. To address these challenges, we introduce a novel model called Dual-Weighted Contrastive Learning (DWCL) for Multi-View Clustering. Specifically, to reduce the impact of unreliable cross-views, we introduce an innovative Best-Other (B-O) contrastive mechanism that enhances the representation of individual views at a low computational cost. Furthermore, we develop a dual weighting strategy that combines a view quality weight, reflecting the quality of each view, with a view discrepancy weight. This approach effectively mitigates representation degeneration by downplaying cross-views that are both low in quality and high in discrepancy. We theoretically validate the efficiency of the B-O contrastive mechanism and the effectiveness of the dual weighting strategy. Extensive experiments demonstrate that DWCL outperforms previous methods across eight multi-view datasets, showcasing superior performance and robustness in MVCC. Specifically, our method achieves absolute accuracy improvements of 5.4\% and 5.6\% compared to state-of-the-art methods on the Caltech6V7 and MSRCv1 datasets, respectively.