Grounding-IQA: Grounding Multimodal Language Model for Image Quality Assessment
作者: Zheng Chen, Xun Zhang, Wenbo Li, Renjing Pei, Fenglong Song, Xiongkuo Min, Xiaohong Liu, Xin Yuan, Yong Guo, Yulun Zhang
分类: cs.CV
发布日期: 2024-11-26 (更新: 2025-10-05)
备注: Code is available at: https://github.com/zhengchen1999/Grounding-IQA
🔗 代码/项目: GITHUB
💡 一句话要点
提出Grounding-IQA,通过多模态 grounding 提升图像质量评估的细粒度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像质量评估 多模态学习 视觉Grounding 视觉问答 细粒度分析 数据集构建 基准测试
📋 核心要点
- 现有基于多模态大语言模型的图像质量评估方法依赖于通用上下文描述,缺乏细粒度质量评估能力。
- 提出Grounding-IQA范式,将多模态指代和grounding与图像质量评估相结合,实现更细粒度的质量感知。
- 构建了包含160K样本的GIQA-160K数据集,并设计了GIQA-Bench基准测试,实验验证了该方法在细粒度IQA上的有效性。
📝 摘要(中文)
多模态大型语言模型(MLLM)的发展使得通过自然语言描述评估图像质量成为可能,从而实现了更细致的评估。然而,这些基于MLLM的IQA方法主要依赖于一般的上下文描述,有时限制了细粒度的质量评估。为了解决这个限制,我们引入了一种新的图像质量评估(IQA)任务范式,grounding-IQA。该范式将多模态指代和grounding与IQA集成,以实现更细粒度的质量感知,从而扩展现有的IQA。具体来说,grounding-IQA包括两个子任务:grounding-IQA-description (GIQA-DES)和视觉问答(GIQA-VQA)。GIQA-DES涉及具有精确位置(例如,边界框)的详细描述,而GIQA-VQA侧重于局部区域的质量问答。为了实现grounding-IQA,我们通过我们提出的自动标注流程构建了一个相应的数据集GIQA-160K。此外,我们开发了一个精心设计的基准测试GIQA-Bench。该基准测试从三个角度评估grounding-IQA的性能:描述质量、VQA准确性和grounding精度。实验表明,我们提出的方法有助于更细粒度的IQA应用。
🔬 方法详解
问题定义:现有基于多模态大语言模型的图像质量评估方法,主要依赖于全局的上下文描述,无法针对图像的局部区域进行细粒度的质量评估。这限制了其在需要精确定位缺陷或评估局部质量的应用场景中的表现。因此,需要一种能够将图像质量评估与视觉 grounding 相结合的方法,以实现更精细的质量感知。
核心思路:论文的核心思路是将图像质量评估任务与多模态的指代和 grounding 相结合。通过让模型能够理解图像中特定区域的质量,并用自然语言描述其质量问题,从而实现更细粒度的质量评估。这种方法借鉴了人类在评估图像质量时,会关注图像的特定区域并描述其质量特征的习惯。
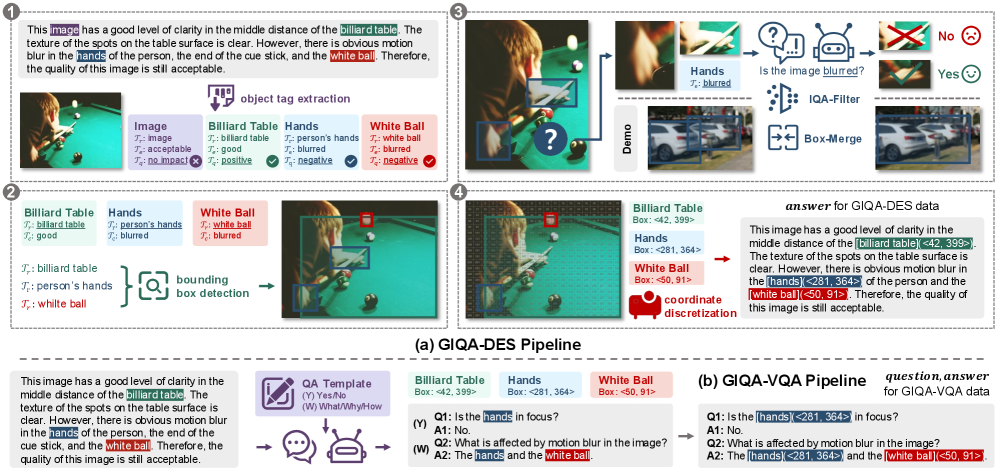
技术框架:Grounding-IQA 框架包含两个主要的子任务:GIQA-DES (grounding-IQA-description) 和 GIQA-VQA (grounding-IQA-VQA)。GIQA-DES 任务要求模型生成包含精确位置(边界框)的详细描述,用于描述图像中特定区域的质量问题。GIQA-VQA 任务则要求模型回答关于图像局部区域质量的视觉问题。为了支持这两个任务,作者构建了 GIQA-160K 数据集,并设计了 GIQA-Bench 基准测试。
关键创新:该论文的关键创新在于提出了 grounding-IQA 这一新的图像质量评估范式。与传统的 IQA 方法不同,grounding-IQA 能够将图像质量评估与视觉 grounding 相结合,从而实现更细粒度的质量感知。此外,GIQA-160K 数据集和 GIQA-Bench 基准测试的构建,为 grounding-IQA 领域的研究提供了数据和评估标准。
关键设计:GIQA-160K 数据集的构建采用了自动标注流程,以提高标注效率和数据质量。GIQA-Bench 基准测试从描述质量、VQA 准确性和 grounding 精度三个角度评估 grounding-IQA 的性能。具体的模型架构和损失函数选择取决于所使用的多模态大语言模型,论文中没有详细说明。
🖼️ 关键图片

📊 实验亮点
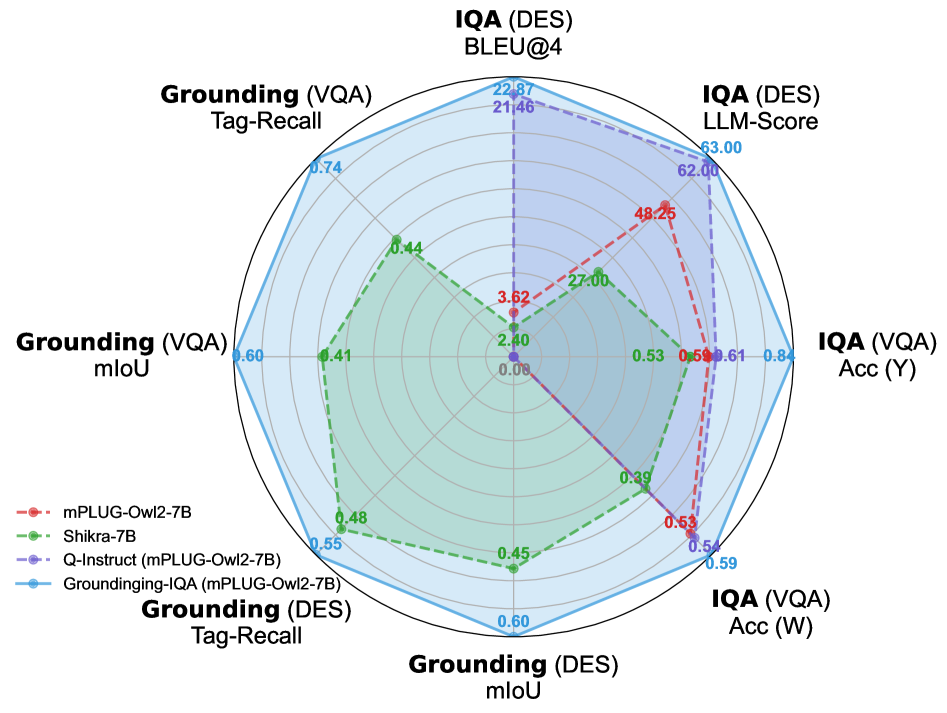
论文构建了包含160K样本的GIQA-160K数据集,并设计了GIQA-Bench基准测试,从描述质量、VQA准确性和grounding精度三个角度评估 grounding-IQA 的性能。实验结果表明,该方法能够实现更细粒度的图像质量评估,为后续研究奠定了基础。具体的性能数据和对比基线在论文中没有详细给出。
🎯 应用场景
Grounding-IQA 在工业质检、医学影像分析、遥感图像处理等领域具有广泛的应用前景。例如,在工业质检中,可以用于自动检测产品表面的缺陷,并生成详细的缺陷描述。在医学影像分析中,可以辅助医生诊断疾病,并提供关于病灶区域质量的详细信息。在遥感图像处理中,可以用于评估图像的清晰度和质量,为后续的图像分析提供保障。
📄 摘要(原文)
The development of multimodal large language models (MLLMs) enables the evaluation of image quality through natural language descriptions. This advancement allows for more detailed assessments. However, these MLLM-based IQA methods primarily rely on general contextual descriptions, sometimes limiting fine-grained quality assessment. To address this limitation, we introduce a new image quality assessment (IQA) task paradigm, grounding-IQA. This paradigm integrates multimodal referring and grounding with IQA to realize more fine-grained quality perception, thereby extending existing IQA. Specifically, grounding-IQA comprises two subtasks: grounding-IQA-description (GIQA-DES) and visual question answering (GIQA-VQA). GIQA-DES involves detailed descriptions with precise locations (e.g., bounding boxes), while GIQA-VQA focuses on quality QA for local regions. To realize grounding-IQA, we construct a corresponding dataset, GIQA-160K, through our proposed automated annotation pipeline. Furthermore, we develop a well-designed benchmark, GIQA-Bench. The benchmark evaluates the grounding-IQA performance from three perspectives: description quality, VQA accuracy, and grounding precision. Experiments demonstrate that our proposed method facilitates the more fine-grained IQA application. Code: https://github.com/zhengchen1999/Grounding-IQA.