SelfSplat: Pose-Free and 3D Prior-Free Generalizable 3D Gaussian Splatting
作者: Gyeongjin Kang, Jisang Yoo, Jihyeon Park, Seungtae Nam, Hyeonsoo Im, Sangheon Shin, Sangpil Kim, Eunbyung Park
分类: cs.CV
发布日期: 2024-11-26 (更新: 2025-04-06)
备注: Project page: https://gynjn.github.io/selfsplat/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SelfSplat:提出一种无需位姿和3D先验的可泛化3D高斯溅射方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 高斯溅射 自监督学习 位姿估计 深度估计 多视角几何 无先验知识
📋 核心要点
- 现有方法在无位姿和无3D先验的条件下,难以从多视角图像中实现高质量的3D重建,主要挑战在于数据缺失和几何信息不足。
- SelfSplat通过结合显式3D表示与自监督深度和位姿估计,实现位姿精度和3D重建质量的相互提升,从而解决上述问题。
- 在RealEstate10K等数据集上的实验表明,SelfSplat在外观和几何质量上超越了现有方法,并具有良好的跨数据集泛化能力。
📝 摘要(中文)
SelfSplat 是一种新颖的 3D 高斯溅射模型,旨在从无位姿的多视角图像中执行无需位姿和 3D 先验的可泛化 3D 重建。由于缺乏真值数据、学习到的几何信息以及需要在没有微调的情况下实现精确的 3D 重建,这些设置本质上是不适定的,这使得传统方法难以获得高质量的结果。我们的模型通过有效地将显式 3D 表示与自监督深度和位姿估计技术相结合来应对这些挑战,从而在位姿精度和 3D 重建质量方面实现互惠互利的改进。此外,我们还结合了一个匹配感知位姿估计网络和一个深度细化模块,以增强跨视角的几何一致性,确保更准确和稳定的 3D 重建。为了展示我们方法的性能,我们在大型真实世界数据集(包括 RealEstate10K、ACID 和 DL3DV)上对其进行了评估。SelfSplat 在外观和几何质量方面均优于先前的最先进方法,并且还展示了强大的跨数据集泛化能力。广泛的消融研究和分析也验证了我们提出的方法的有效性。
🔬 方法详解
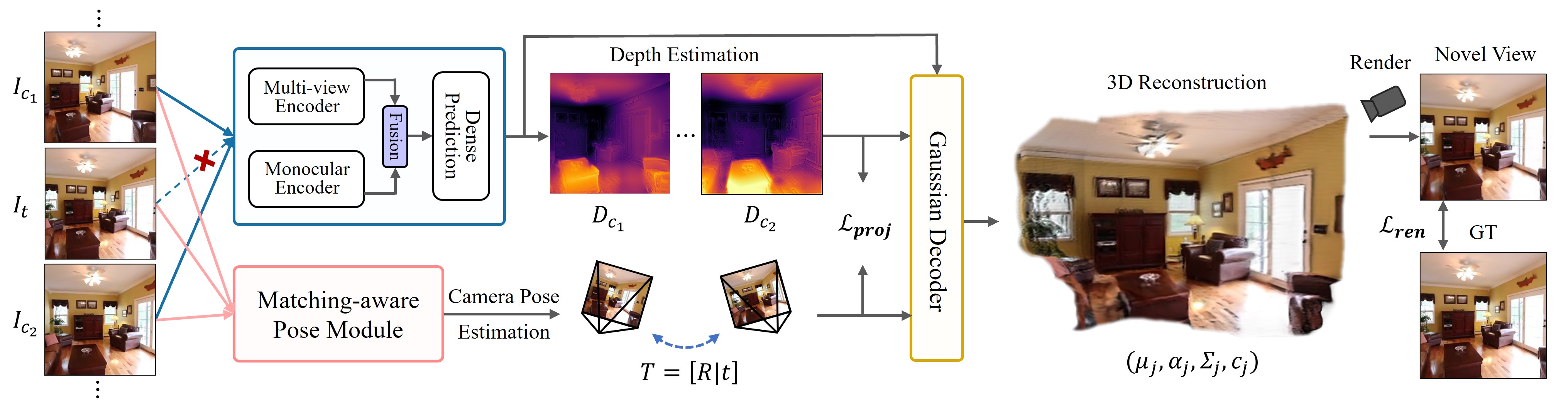
问题定义:论文旨在解决从无位姿的多视角图像中进行3D重建的问题,尤其是在缺乏ground truth位姿和3D先验知识的情况下。现有方法通常依赖于精确的位姿信息或预训练的3D模型,难以在这种具有挑战性的场景下实现高质量的重建。现有方法的痛点在于几何信息的缺失和位姿估计的不准确性,导致重建结果的质量下降。
核心思路:SelfSplat的核心思路是将显式的3D高斯溅射表示与自监督的深度和位姿估计相结合。通过自监督学习,模型可以从多视角图像中同时学习深度信息和相机位姿,从而避免了对外部位姿信息的依赖。这种相互促进的方式能够提升位姿估计的准确性和3D重建的质量。
技术框架:SelfSplat的整体框架包含以下几个主要模块:1) 3D高斯溅射表示:使用3D高斯分布来表示场景的几何和外观信息。2) 自监督深度估计:利用多视角图像之间的几何约束,通过自监督学习的方式估计场景的深度图。3) 位姿估计网络:使用匹配感知的位姿估计网络来预测相机位姿。4) 深度细化模块:对估计的深度图进行细化,以提高几何一致性。整个流程通过迭代优化3D高斯参数、深度图和相机位姿,最终实现高质量的3D重建。
关键创新:SelfSplat的关键创新在于将显式的3D表示(高斯溅射)与自监督学习相结合,从而在无需位姿和3D先验的情况下实现可泛化的3D重建。与现有方法相比,SelfSplat不需要预训练的3D模型或精确的位姿信息,因此更具灵活性和泛化能力。此外,匹配感知的位姿估计网络和深度细化模块进一步提升了几何一致性和重建质量。
关键设计:SelfSplat的关键设计包括:1) 匹配感知的位姿估计网络:该网络通过学习图像之间的匹配关系来提高位姿估计的准确性。2) 深度细化模块:该模块利用多视角图像之间的几何约束来细化深度图,从而提高几何一致性。3) 自监督损失函数:论文设计了一系列自监督损失函数,包括光度一致性损失、深度一致性损失等,用于约束深度图和位姿的估计。
🖼️ 关键图片


📊 实验亮点
SelfSplat在RealEstate10K、ACID和DL3DV等大型真实世界数据集上进行了评估,实验结果表明,SelfSplat在外观和几何质量方面均优于现有的state-of-the-art方法。此外,SelfSplat还展示了强大的跨数据集泛化能力,表明其具有良好的鲁棒性和适应性。消融实验验证了各个模块的有效性。
🎯 应用场景
SelfSplat在无需预先位姿信息和3D先验知识的情况下进行3D重建,具有广泛的应用前景,例如在机器人导航、自动驾驶、虚拟现实/增强现实、以及城市建模等领域。该技术可以用于快速构建场景的3D模型,无需昂贵的传感器或人工干预,降低了3D重建的成本,并加速了相关应用的发展。
📄 摘要(原文)
We propose SelfSplat, a novel 3D Gaussian Splatting model designed to perform pose-free and 3D prior-free generalizable 3D reconstruction from unposed multi-view images. These settings are inherently ill-posed due to the lack of ground-truth data, learned geometric information, and the need to achieve accurate 3D reconstruction without finetuning, making it difficult for conventional methods to achieve high-quality results. Our model addresses these challenges by effectively integrating explicit 3D representations with self-supervised depth and pose estimation techniques, resulting in reciprocal improvements in both pose accuracy and 3D reconstruction quality. Furthermore, we incorporate a matching-aware pose estimation network and a depth refinement module to enhance geometry consistency across views, ensuring more accurate and stable 3D reconstructions. To present the performance of our method, we evaluated it on large-scale real-world datasets, including RealEstate10K, ACID, and DL3DV. SelfSplat achieves superior results over previous state-of-the-art methods in both appearance and geometry quality, also demonstrates strong cross-dataset generalization capabilities. Extensive ablation studies and analysis also validate the effectiveness of our proposed methods. Code and pretrained models are available at https://gynjn.github.io/selfsplat/