DOGR: Towards Versatile Visual Document Grounding and Referring
作者: Yinan Zhou, Yuxin Chen, Haokun Lin, Yichen Wu, Shuyu Yang, Zhongang Qi, Chen Ma, Li Zhu, Ying Shan
分类: cs.CV, cs.AI
发布日期: 2024-11-26 (更新: 2025-08-06)
备注: 22 pages, 16 figures
💡 一句话要点
DOGR:面向通用视觉文档定位与指代的模型、数据引擎与评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文档理解 多模态学习 定位与指代 数据引擎 评测基准
📋 核心要点
- 现有视觉文档理解模型在细粒度定位和指代能力方面存在不足,缺乏高质量数据集和全面评测基准。
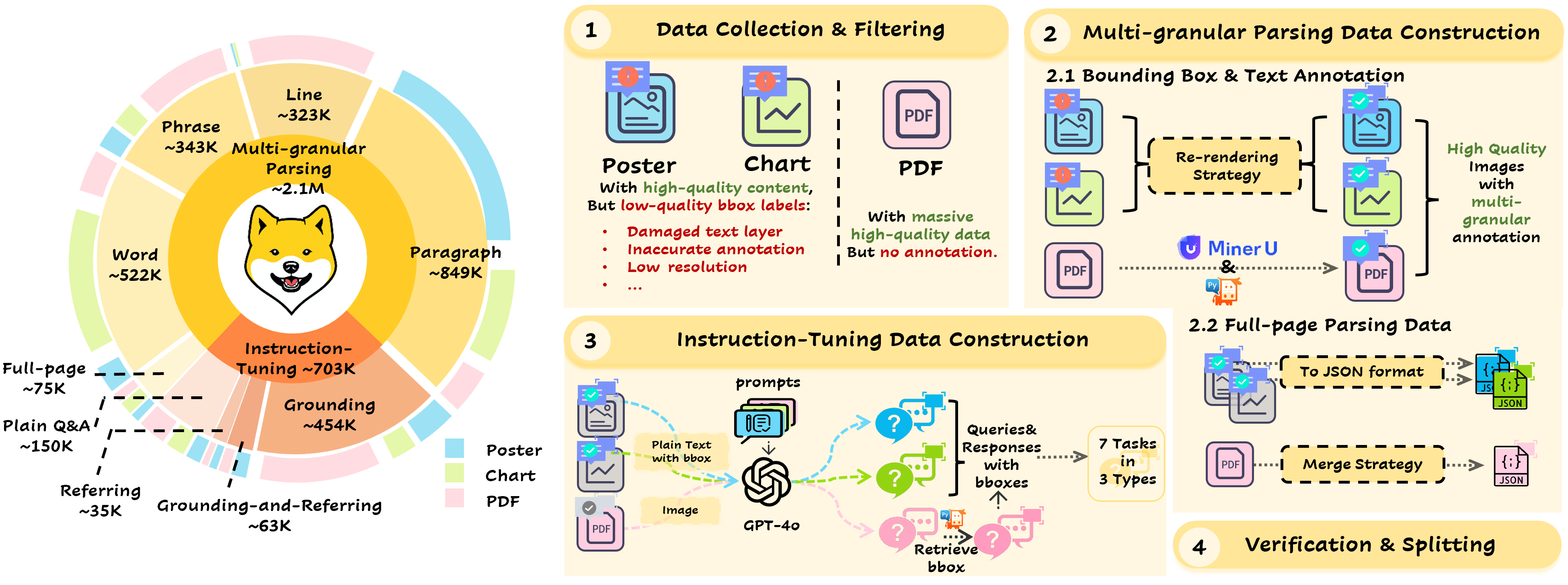
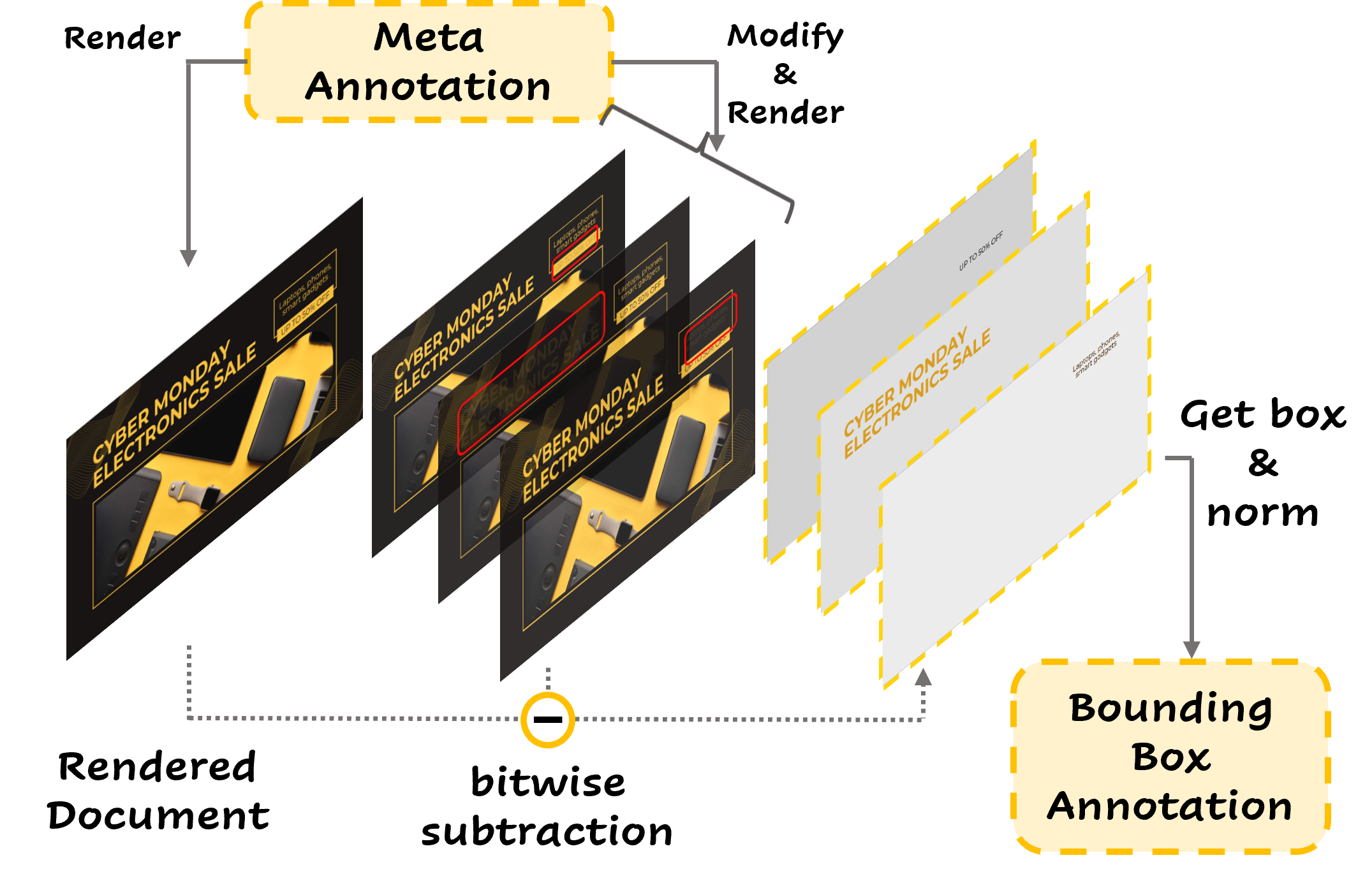
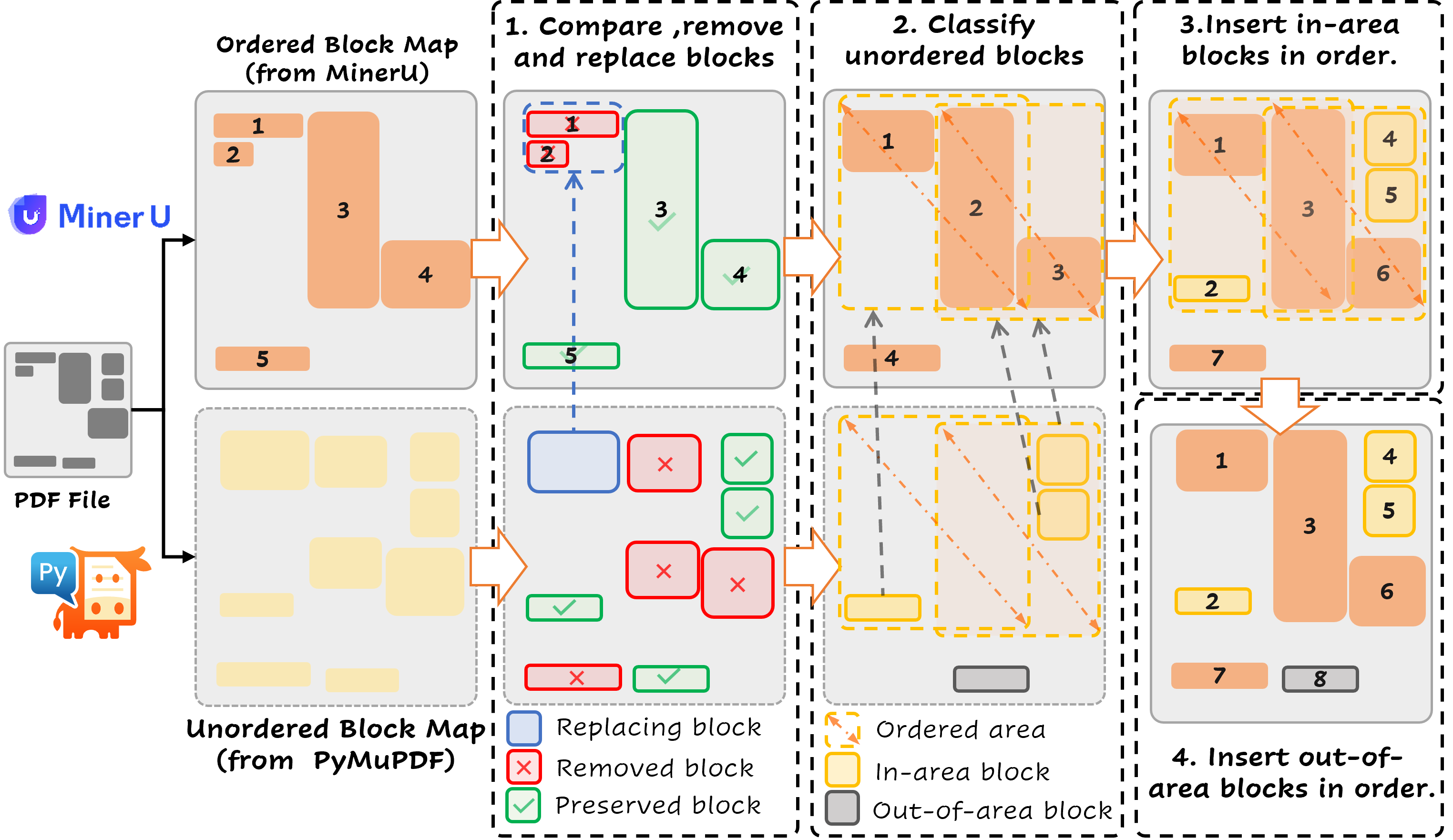
- DOGR提出了一种数据引擎(DOGR-Engine),用于生成多粒度解析和指令调优数据,以提升MLLM的定位和指代能力。
- DOGR构建了DOGR-Bench评测基准,涵盖多种文档类型和任务,并提出了DOGR模型作为强大的基线。
📝 摘要(中文)
随着多模态大型语言模型(MLLM)的最新进展,定位和指代能力在实现详细理解和灵活用户交互方面受到越来越多的关注。然而,由于缺乏细粒度数据集和全面的基准,这些能力在视觉文档理解中仍然不发达。为了填补这一空白,我们提出了文档定位和指代数据引擎(DOGR-Engine),它生成两种高质量的细粒度文档数据:(1)多粒度解析数据,以提高文本定位和识别能力;(2)指令调优数据,以激活MLLM在对话和推理中的定位和指代能力。使用DOGR-Engine,我们构建了DOGR-Bench,这是一个基准,涵盖三种文档类型(图表、海报和PDF文档)的七个定位和指代任务,从而对细粒度文档理解进行全面评估。利用生成的数据,我们进一步开发了DOGR,这是一个强大的基线模型,擅长文本定位和识别,同时在对话和推理过程中精确定位和指代关键文本信息,从而将文档理解提升到更精细的粒度,并实现灵活的交互模式。
🔬 方法详解
问题定义:现有视觉文档理解模型在处理细粒度任务时,例如文本定位、指代和推理,面临数据稀缺和评测标准不完善的挑战。缺乏高质量、细粒度的数据集限制了模型训练,而缺乏全面的基准则难以有效评估模型性能。现有方法难以实现对文档的精细化理解和灵活交互。
核心思路:DOGR的核心思路是构建一个数据引擎(DOGR-Engine),自动生成高质量的细粒度文档数据,包括多粒度解析数据和指令调优数据。这些数据用于训练和评估模型,从而提升模型在文本定位、指代和推理方面的能力。通过数据驱动的方式,弥补现有数据集的不足,并提供更全面的评测。
技术框架:DOGR的整体框架包括三个主要部分:DOGR-Engine(数据引擎)、DOGR-Bench(评测基准)和DOGR(模型)。DOGR-Engine负责生成训练数据,包括多粒度解析数据和指令调优数据。DOGR-Bench提供了一系列定位和指代任务,用于评估模型性能。DOGR模型是基于MLLM的基线模型,利用生成的数据进行训练,并在DOGR-Bench上进行评估。
关键创新:DOGR的关键创新在于提出了DOGR-Engine,能够自动生成高质量的细粒度文档数据。与现有数据集相比,DOGR-Engine生成的数据具有更高的质量和更细的粒度,能够更好地支持模型训练和评估。此外,DOGR-Bench提供了一个全面的评测基准,涵盖多种文档类型和任务,能够更准确地评估模型性能。
关键设计:DOGR-Engine的关键设计包括多粒度解析和指令调优两个部分。多粒度解析数据用于提升文本定位和识别能力,包括字符级别、单词级别和段落级别的标注。指令调优数据用于激活MLLM的定位和指代能力,通过对话和推理的方式进行训练。DOGR模型采用基于MLLM的架构,并针对文档理解任务进行了优化。具体的参数设置和网络结构细节在论文中未详细说明。
🖼️ 关键图片
📊 实验亮点
DOGR在DOGR-Bench上进行了实验,结果表明DOGR模型在文本定位、指代和推理方面取得了显著的性能提升。具体的性能数据和对比基线在论文中未详细说明,但强调了DOGR模型在细粒度文档理解方面的优势。DOGR的实验结果验证了DOGR-Engine生成数据的有效性,并证明了DOGR模型作为基线的潜力。
🎯 应用场景
DOGR的研究成果可应用于智能文档处理、信息抽取、人机交互等领域。例如,可以用于自动解析财务报表、合同等文档,提取关键信息并进行推理。此外,还可以用于构建智能助手,用户可以通过自然语言与文档进行交互,例如提问、查找信息等。未来,DOGR有望推动视觉文档理解技术的发展,实现更智能、更高效的文档处理。
📄 摘要(原文)
With recent advances in Multimodal Large Language Models (MLLMs), grounding and referring capabilities have gained increasing attention for achieving detailed understanding and flexible user interaction. However, these capabilities still remain underdeveloped in visual document understanding due to the scarcity of fine-grained datasets and comprehensive benchmarks. To fill this gap, we propose the DOcument Grounding and Referring data engine (DOGR-Engine), which generates two types of high-quality fine-grained document data: (1) multi-granular parsing data to improve text localization and recognition, and (2) instruction-tuning data to activate MLLMs' grounding and referring capabilities in dialogue and reasoning. Using the DOGR-Engine, we construct DOGR-Bench, a benchmark covering seven grounding and referring tasks across three document types (chart, poster, and PDF document), offering a comprehensive evaluation of fine-grained document understanding. Leveraging the generated data, we further develop DOGR, a strong baseline model that excels in text localization and recognition, while precisely grounds and refers to key textual information during conversation and reasoning, thereby advancing document understanding to a finer granularity and enable flexible interaction paradigms.