Advancing Content Moderation: Evaluating Large Language Models for Detecting Sensitive Content Across Text, Images, and Videos
作者: Nouar AlDahoul, Myles Joshua Toledo Tan, Harishwar Reddy Kasireddy, Yasir Zaki
分类: cs.CV, cs.AI
发布日期: 2024-11-26
备注: 55 pages, 16 figures
💡 一句话要点
评估大型语言模型在文本、图像和视频中检测敏感内容的能力,提升内容审核效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内容审核 大型语言模型 多模态学习 敏感内容检测 自然语言处理
📋 核心要点
- 现有内容审核方法在准确检测敏感内容,同时减少误报和漏报方面存在局限性,需要更先进的算法。
- 论文核心在于评估和比较现有大型语言模型(LLM)在检测文本、图像和视频等多模态敏感内容方面的能力。
- 实验结果表明,LLM在内容审核方面优于传统技术,能够实现更高的准确率和更低的错误率。
📝 摘要(中文)
在网站和媒体平台上广泛传播的仇恨言论、骚扰、有害和色情内容以及暴力行为带来了巨大的挑战,并引起了社会各界的广泛关注。政府、教育工作者和家长经常与媒体平台在如何监管、控制和限制此类内容的传播方面存在分歧。检测和审查媒体内容的技术是解决这些挑战的关键方案。自然语言处理和计算机视觉技术已被广泛用于自动识别和过滤文本、图像和视频中的敏感内容,例如攻击性语言、暴力、裸露和成瘾内容,从而使平台能够大规模地执行内容策略。然而,现有方法在实现高检测精度和减少误报和漏报方面仍然存在局限性。因此,更复杂的文本和图像上下文理解算法可能为改进内容审查以构建更有效的审查系统开辟了空间。本文评估了现有的基于LLM的内容审核解决方案,例如OpenAI审核模型和Llama-Guard3,并研究了它们检测敏感内容的能力。此外,我们还探索了最近的LLM,如GPT、Gemini和Llama,以识别媒体渠道中的不当内容。各种文本和视觉数据集,如X推文、亚马逊评论、新闻文章、人物照片、卡通、素描和暴力视频已被用于评估和比较。结果表明,LLM优于传统技术,实现了更高的准确率和更低的误报率和漏报率。这突出了将LLM集成到网站、社交媒体平台和视频共享服务中以进行监管和内容审核的潜力。
🔬 方法详解
问题定义:论文旨在解决当前内容审核系统在准确性和效率方面的不足,特别是在处理文本、图像和视频等多模态数据时。现有方法容易出现误报和漏报,无法有效识别隐藏在上下文中的敏感内容。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语义理解和推理能力,提升内容审核的准确性和鲁棒性。LLM能够更好地理解上下文信息,从而更准确地识别各种形式的敏感内容。
技术框架:论文采用评估和比较的方式,没有提出新的模型架构。主要流程包括:1) 选择合适的LLM,如OpenAI moderation model, Llama-Guard3, GPT, Gemini, Llama等;2) 构建包含文本、图像和视频的多模态数据集;3) 使用LLM对数据集中的内容进行敏感性检测;4) 评估LLM的性能,并与传统方法进行比较。
关键创新:论文的主要创新在于对现有LLM在内容审核任务上的能力进行了全面的评估和比较,揭示了LLM在多模态内容审核方面的潜力。虽然没有提出新的模型,但通过实验验证了LLM在实际应用中的有效性。
关键设计:论文的关键设计在于数据集的选择和评估指标的选取。数据集涵盖了各种类型的敏感内容,包括仇恨言论、骚扰、暴力、色情内容等。评估指标包括准确率、误报率和漏报率,用于全面衡量LLM的性能。
🖼️ 关键图片


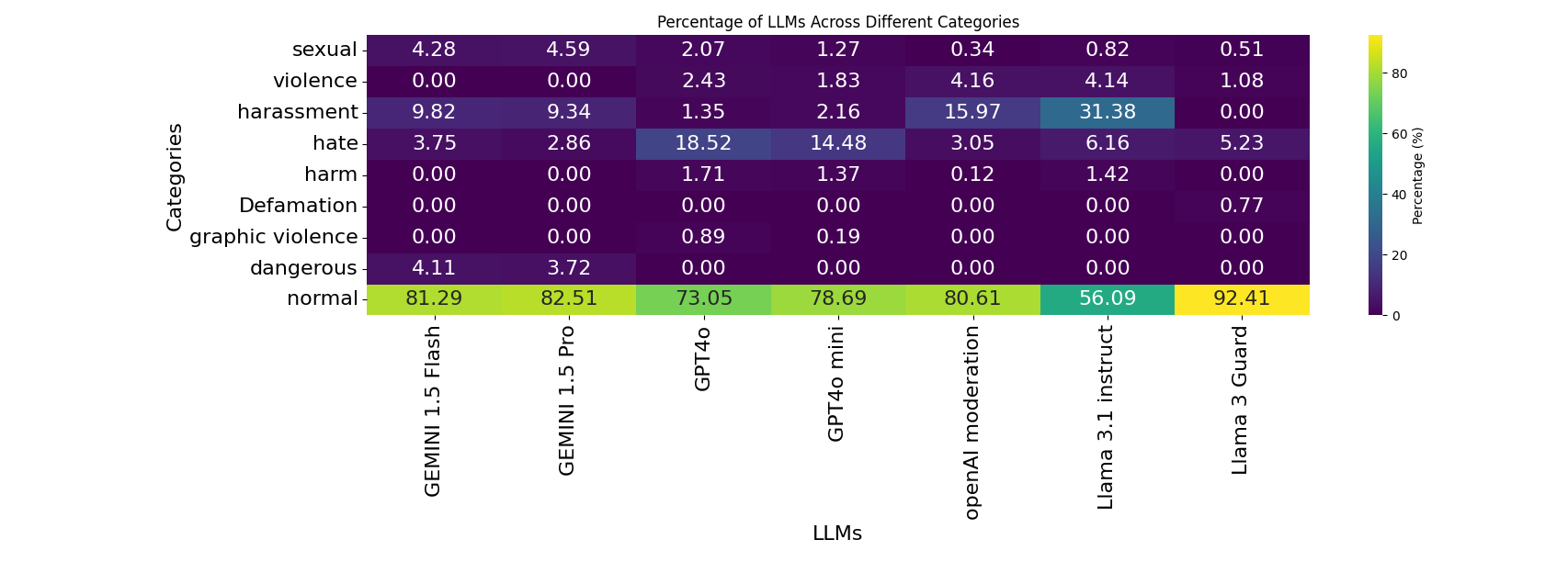
📊 实验亮点
实验结果表明,大型语言模型在内容审核任务中表现出色,相较于传统方法,在准确率方面有显著提升,同时降低了误报率和漏报率。这表明LLM在理解上下文和识别复杂敏感内容方面具有优势,为构建更高效的内容审核系统提供了新的可能性。
🎯 应用场景
该研究成果可应用于各种在线平台的内容审核,包括社交媒体、视频分享网站、电商平台等。通过集成LLM,可以更有效地识别和过滤敏感内容,维护网络环境的健康,保护用户免受有害信息的侵害。未来,该技术有望应用于自动化内容审核系统,降低人工审核的成本和工作量。
📄 摘要(原文)
The widespread dissemination of hate speech, harassment, harmful and sexual content, and violence across websites and media platforms presents substantial challenges and provokes widespread concern among different sectors of society. Governments, educators, and parents are often at odds with media platforms about how to regulate, control, and limit the spread of such content. Technologies for detecting and censoring the media contents are a key solution to addressing these challenges. Techniques from natural language processing and computer vision have been used widely to automatically identify and filter out sensitive content such as offensive languages, violence, nudity, and addiction in both text, images, and videos, enabling platforms to enforce content policies at scale. However, existing methods still have limitations in achieving high detection accuracy with fewer false positives and false negatives. Therefore, more sophisticated algorithms for understanding the context of both text and image may open rooms for improvement in content censorship to build a more efficient censorship system. In this paper, we evaluate existing LLM-based content moderation solutions such as OpenAI moderation model and Llama-Guard3 and study their capabilities to detect sensitive contents. Additionally, we explore recent LLMs such as GPT, Gemini, and Llama in identifying inappropriate contents across media outlets. Various textual and visual datasets like X tweets, Amazon reviews, news articles, human photos, cartoons, sketches, and violence videos have been utilized for evaluation and comparison. The results demonstrate that LLMs outperform traditional techniques by achieving higher accuracy and lower false positive and false negative rates. This highlights the potential to integrate LLMs into websites, social media platforms, and video-sharing services for regulatory and content moderation purposes.