Large-Scale Data-Free Knowledge Distillation for ImageNet via Multi-Resolution Data Generation
作者: Minh-Tuan Tran, Trung Le, Xuan-May Le, Jianfei Cai, Mehrtash Harandi, Dinh Phung
分类: cs.CV
发布日期: 2024-11-26
🔗 代码/项目: GITHUB
💡 一句话要点
提出MUSE:通过多分辨率数据生成实现ImageNet大规模无数据知识蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无数据知识蒸馏 知识迁移 图像生成 类激活图 多分辨率学习
📋 核心要点
- 现有无数据知识蒸馏方法在高分辨率图像数据集上生成质量差、缺乏类别特征的图像,限制了性能。
- MUSE通过在低分辨率下生成图像,并利用类激活图(CAM)保留关键类别特征,提升生成图像质量。
- MUSE采用多分辨率生成和嵌入多样性技术,增强潜在空间表示,在ImageNet上取得显著性能提升。
📝 摘要(中文)
无数据知识蒸馏(DFKD)是一种先进的技术,它能够在不依赖原始训练数据的情况下,将知识从教师模型迁移到学生模型。虽然DFKD方法在CIFAR10和CIFAR100等较小的数据集上取得了成功,但在ImageNet等较大、高分辨率的数据集上遇到了挑战。先前方法的一个主要问题是它们在高分辨率(例如,$224 imes 224$)下生成合成图像,而没有利用真实图像的信息,这通常导致噪声图像,并且缺乏大型数据集中必不可少的类别特定特征。此外,生成有效知识迁移所需的大量数据的计算成本可能过高。在本文中,我们引入了MUlti-reSolution data-freE (MUSE)来解决这些限制。MUSE以较低的分辨率生成图像,同时使用类激活图(CAM)来确保生成的图像保留关键的类别特定特征。为了进一步增强模型多样性,我们提出了多分辨率生成和嵌入多样性技术,这些技术加强了潜在空间表示,从而带来了显著的性能提升。实验结果表明,MUSE在小型和大型数据集上都实现了最先进的性能,在几乎所有的ImageNet和子集实验中,性能提升高达两位数。代码可在https://github.com/tmtuan1307/muse获得。
🔬 方法详解
问题定义:论文旨在解决无数据知识蒸馏(DFKD)在大规模高分辨率图像数据集(如ImageNet)上的性能瓶颈问题。现有DFKD方法直接在高分辨率下生成合成图像,由于缺乏真实图像的指导,生成的图像质量差,包含大量噪声,并且难以捕捉到类别相关的关键特征,导致知识迁移效果不佳。此外,生成大量高分辨率图像的计算成本也很高。
核心思路:论文的核心思路是降低生成图像的分辨率,从而降低生成难度,并利用类激活图(CAM)来引导图像生成过程,确保生成的低分辨率图像能够保留关键的类别特定特征。同时,通过多分辨率生成和嵌入多样性技术,进一步增强生成数据的多样性,提升知识迁移的效果。
技术框架:MUSE框架主要包含以下几个阶段:1) 低分辨率图像生成:使用生成器网络生成低分辨率的合成图像。2) 类激活图引导:利用教师模型的类激活图(CAM)作为指导,优化生成器网络,使得生成的图像能够激活教师模型中与类别相关的特征。3) 多分辨率生成:生成不同分辨率的图像,以增加数据的多样性。4) 嵌入多样性:通过正则化项,鼓励生成图像在潜在空间中的多样性。5) 知识蒸馏:使用生成的合成图像训练学生模型,使其学习教师模型的知识。
关键创新:MUSE的关键创新在于:1) 低分辨率生成与CAM引导:通过在低分辨率下生成图像,降低了生成难度,并利用CAM引导图像生成,保证了生成图像的类别相关性。2) 多分辨率生成与嵌入多样性:通过生成不同分辨率的图像和鼓励潜在空间多样性,增强了生成数据的多样性,提升了知识迁移的效果。与现有方法相比,MUSE不再盲目地在高分辨率下生成图像,而是更加注重生成图像的质量和类别相关性。
关键设计:MUSE的关键设计包括:1) 生成器网络结构:采用常见的生成对抗网络(GAN)结构,但针对低分辨率图像生成进行了优化。2) CAM损失函数:设计了基于CAM的损失函数,用于引导生成器网络生成能够激活教师模型中与类别相关的特征的图像。3) 多分辨率策略:选择合适的分辨率组合,以平衡生成图像的质量和多样性。4) 嵌入多样性正则化项:设计了正则化项,用于鼓励生成图像在潜在空间中的多样性,避免模式崩塌。
🖼️ 关键图片
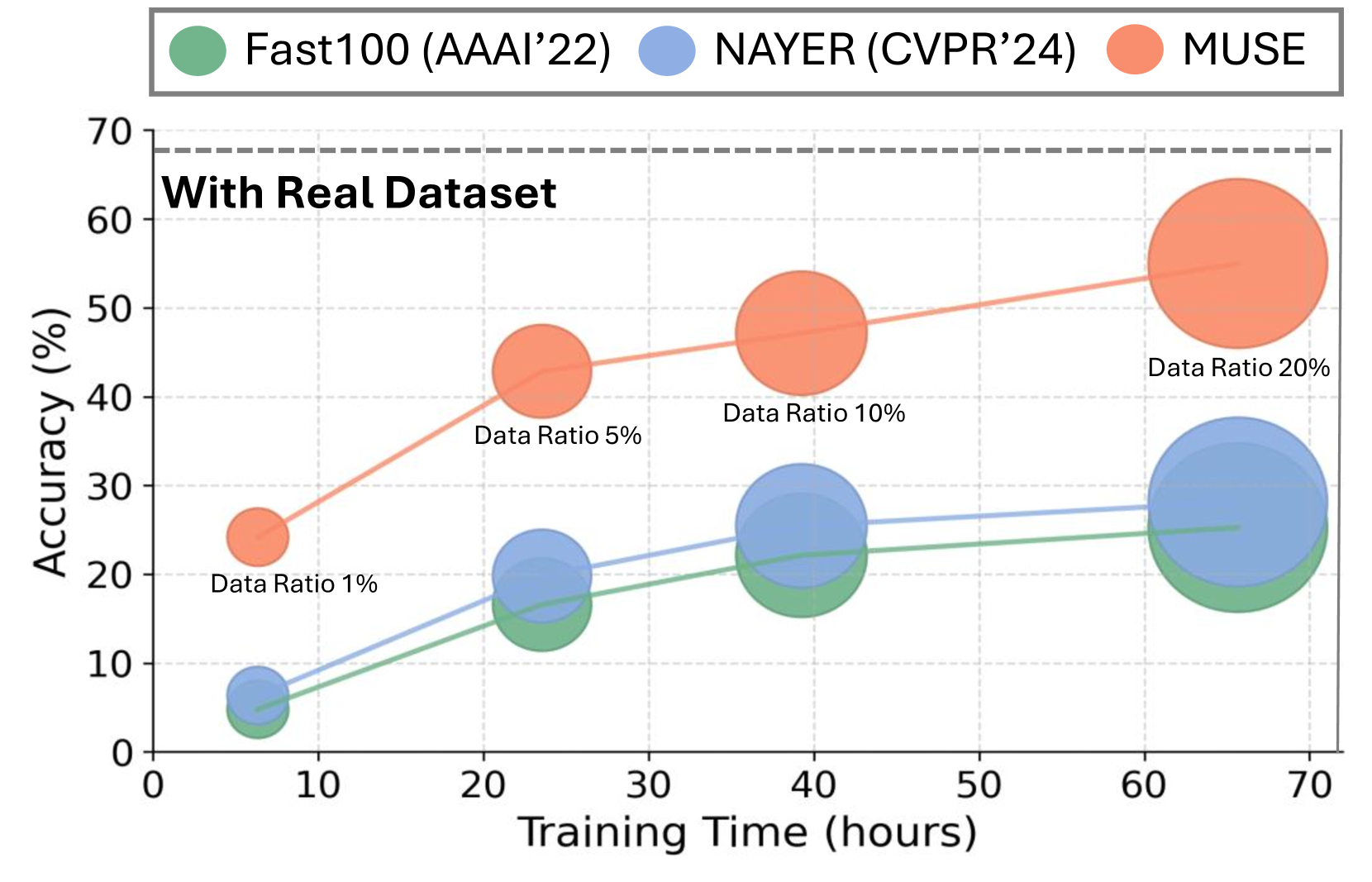
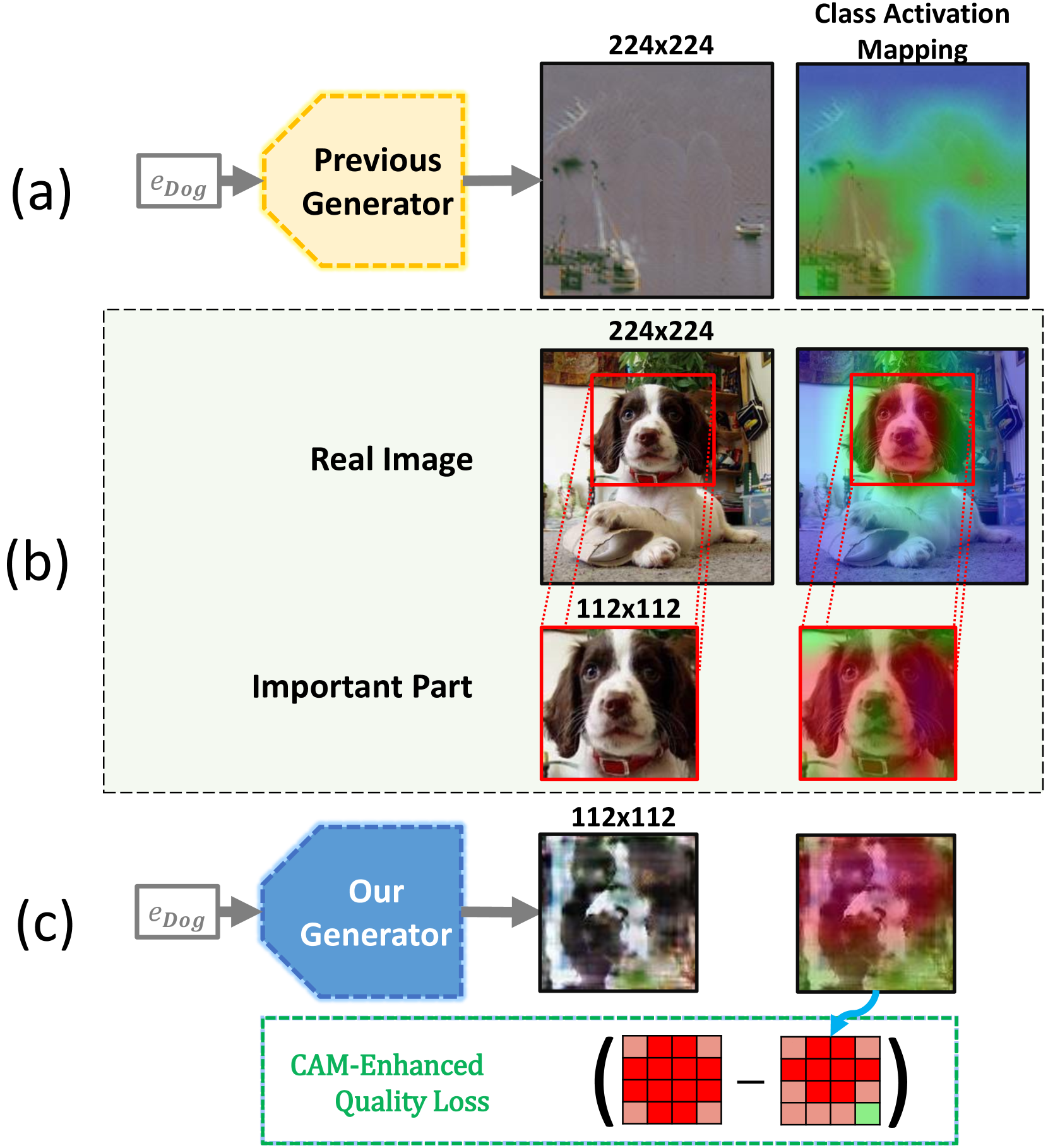
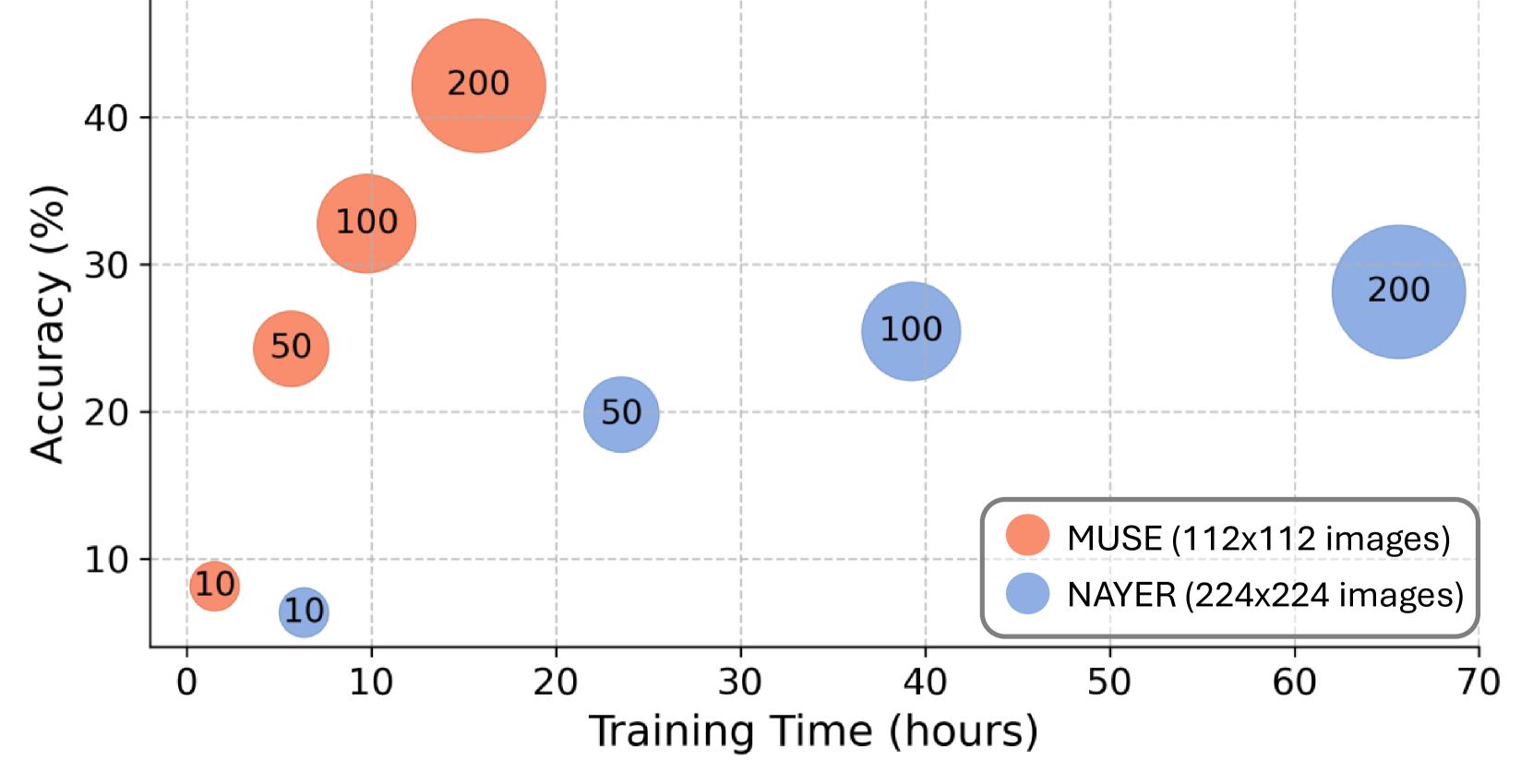
📊 实验亮点
MUSE在ImageNet数据集上取得了显著的性能提升,在多个实验中,相比于现有的无数据知识蒸馏方法,性能提升高达两位数。例如,在某些实验设置下,MUSE的性能甚至接近于使用真实数据训练的学生模型。这些结果表明,MUSE能够有效地解决大规模高分辨率图像数据集上的无数据知识蒸馏问题。
🎯 应用场景
MUSE可应用于模型压缩、模型加速、隐私保护等领域。例如,在资源受限的设备上部署大型模型时,可以使用MUSE进行无数据知识蒸馏,将知识从大型教师模型迁移到小型学生模型,从而在保证性能的同时降低计算成本。此外,MUSE还可以用于保护训练数据隐私,避免直接使用原始数据进行模型训练。
📄 摘要(原文)
Data-Free Knowledge Distillation (DFKD) is an advanced technique that enables knowledge transfer from a teacher model to a student model without relying on original training data. While DFKD methods have achieved success on smaller datasets like CIFAR10 and CIFAR100, they encounter challenges on larger, high-resolution datasets such as ImageNet. A primary issue with previous approaches is their generation of synthetic images at high resolutions (e.g., $224 \times 224$) without leveraging information from real images, often resulting in noisy images that lack essential class-specific features in large datasets. Additionally, the computational cost of generating the extensive data needed for effective knowledge transfer can be prohibitive. In this paper, we introduce MUlti-reSolution data-freE (MUSE) to address these limitations. MUSE generates images at lower resolutions while using Class Activation Maps (CAMs) to ensure that the generated images retain critical, class-specific features. To further enhance model diversity, we propose multi-resolution generation and embedding diversity techniques that strengthen latent space representations, leading to significant performance improvements. Experimental results demonstrate that MUSE achieves state-of-the-art performance across both small- and large-scale datasets, with notable performance gains of up to two digits in nearly all ImageNet and subset experiments. Code is available at https://github.com/tmtuan1307/muse.