Multimodal Alignment and Fusion: A Survey
作者: Songtao Li, Hao Tang
分类: cs.CV
发布日期: 2024-11-26 (更新: 2025-10-11)
备注: Accepted to IJCV 2025
💡 一句话要点
综述多模态对齐与融合技术,涵盖结构视角与方法范式,旨在提升多模态学习系统的泛化性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 多模态融合 跨模态对齐 特征级融合 数据级融合 输出级融合 深度学习 大型语言模型
📋 核心要点
- 现有方法在多模态学习中面临跨模态错位、计算瓶颈和模态差距等挑战,限制了系统的鲁棒性和泛化能力。
- 该综述从结构和方法两个维度系统地分析了多模态对齐与融合技术,为研究者提供了一个全面的技术框架。
- 通过回顾260多篇相关研究,该综述总结了多模态学习在社交媒体分析、医学成像和情感识别等领域的应用。
📝 摘要(中文)
本综述全面概述了机器学习领域中多模态对齐与融合的最新进展,这些进展受益于文本、图像、音频和视频等日益增长和多样化的数据模态。与以往侧重于特定模态或有限融合策略的综述不同,本文提出了一个以结构为中心、方法驱动的框架,强调通用技术。我们通过结构视角(数据级、特征级和输出级融合)和方法范式(包括统计、核方法、图模型、生成模型、对比学习、注意力机制和基于大型语言模型的方法)系统地分类和分析了对齐和融合的关键方法,并从对260多项相关研究的广泛回顾中汲取了见解。此外,本综述还强调了跨模态错位、计算瓶颈、数据质量问题和模态差距等关键挑战,以及解决这些挑战的最新努力。探索了从社交媒体分析和医学成像到情感识别和具身人工智能等应用,以说明稳健的多模态系统的实际影响。所提供的见解旨在指导未来的研究,以优化多模态学习系统,从而提高跨不同领域的扩展性、鲁棒性和泛化性。
🔬 方法详解
问题定义:多模态对齐与融合旨在整合来自不同模态的信息,以提升机器学习模型的性能。现有方法常常面临跨模态数据难以对齐、计算复杂度高、以及不同模态间存在语义鸿沟等问题,这些问题限制了多模态学习系统的泛化能力和鲁棒性。
核心思路:该综述的核心思路是从结构和方法两个维度对多模态对齐与融合技术进行系统性的梳理和分析。通过结构化的视角(数据级、特征级、输出级融合)和方法论的范式(统计、核方法、图模型、生成模型等),将现有方法进行分类和比较,从而帮助研究者更好地理解不同方法的优缺点和适用场景。
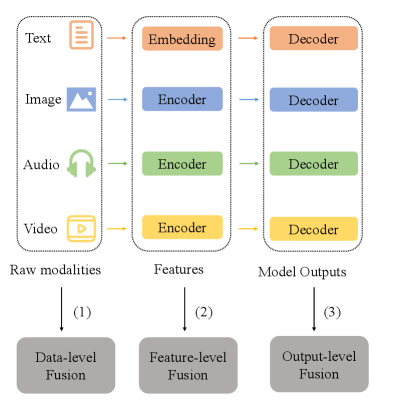
技术框架:该综述构建了一个结构化的框架,首先从数据融合的层级(数据级、特征级、输出级)对方法进行分类。然后,在每个层级下,又根据使用的方法论(统计方法、核方法、图模型、生成模型、对比学习、注意力机制、LLM)进行细分。这种框架能够帮助读者快速定位到自己感兴趣的方法,并了解其在多模态学习中的应用。
关键创新:该综述的创新之处在于其系统性和全面性。不同于以往侧重于特定模态或融合策略的综述,该综述提供了一个更通用的框架,涵盖了多种模态和多种融合方法。此外,该综述还强调了多模态学习中存在的挑战,并对未来的研究方向进行了展望。
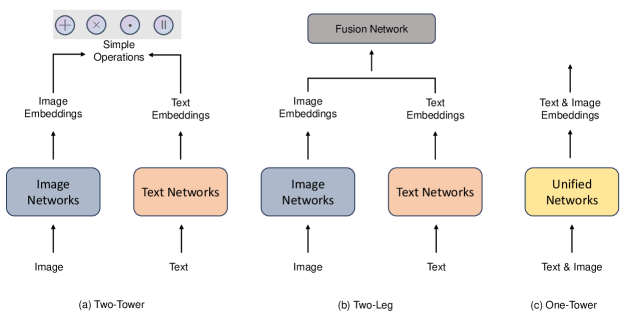
关键设计:该综述的关键设计在于其分类框架。数据级融合侧重于原始数据的整合,例如将图像和文本数据拼接在一起。特征级融合则是在特征空间中进行融合,例如使用神经网络提取不同模态的特征,然后将这些特征进行拼接或加权融合。输出级融合则是在模型输出层面进行融合,例如使用不同的模型处理不同的模态,然后将它们的输出进行组合。在方法论方面,该综述涵盖了多种常用的机器学习方法,并分析了它们在多模态学习中的应用。
🖼️ 关键图片
📊 实验亮点
该综述回顾了超过260篇相关研究,对各种多模态对齐与融合方法进行了全面的分析和比较。虽然综述本身不包含新的实验结果,但它总结了现有研究的性能数据,例如在情感识别任务中,多模态融合方法通常比单模态方法取得更高的准确率。此外,该综述还强调了基于大型语言模型的多模态学习方法在提升模型性能方面的潜力。
🎯 应用场景
多模态对齐与融合技术在多个领域具有广泛的应用前景,包括社交媒体分析(例如,结合文本、图像和视频进行情感分析)、医学成像(例如,结合CT扫描和MRI图像进行疾病诊断)、情感识别(例如,结合语音和面部表情进行情感判断)和具身人工智能(例如,机器人结合视觉和听觉信息进行环境感知和交互)。这些应用能够提升系统的智能化水平和用户体验。
📄 摘要(原文)
This survey provides a comprehensive overview of recent advances in multimodal alignment and fusion within the field of machine learning, driven by the increasing availability and diversity of data modalities such as text, images, audio, and video. Unlike previous surveys that often focus on specific modalities or limited fusion strategies, our work presents a structure-centric and method-driven framework that emphasizes generalizable techniques. We systematically categorize and analyze key approaches to alignment and fusion through both structural perspectives -- data-level, feature-level, and output-level fusion -- and methodological paradigms -- including statistical, kernel-based, graphical, generative, contrastive, attention-based, and large language model (LLM)-based methods, drawing insights from an extensive review of over 260 relevant studies. Furthermore, this survey highlights critical challenges such as cross-modal misalignment, computational bottlenecks, data quality issues, and the modality gap, along with recent efforts to address them. Applications ranging from social media analysis and medical imaging to emotion recognition and embodied AI are explored to illustrate the real-world impact of robust multimodal systems. The insights provided aim to guide future research toward optimizing multimodal learning systems for improved scalability, robustness, and generalizability across diverse domains.