DreamRunner: Fine-Grained Compositional Story-to-Video Generation with Retrieval-Augmented Motion Adaptation
作者: Zun Wang, Jialu Li, Han Lin, Jaehong Yoon, Mohit Bansal
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-11-25 (更新: 2025-11-14)
备注: AAAI 2026, Project website: https://zunwang1.github.io/DreamRunner
💡 一句话要点
DreamRunner:提出检索增强运动适配的细粒度组合故事到视频生成方法
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 故事视频生成 文本到视频 检索增强 运动适配 细粒度控制
📋 核心要点
- 现有故事到视频生成方法难以处理复杂场景描述,无法保证角色一致性和运动的真实性。
- DreamRunner利用LLM进行细粒度规划,并引入检索增强运动适配,实现更逼真的视频生成。
- 实验表明,DreamRunner在角色一致性、文本对齐和生成质量上均优于现有方法,并在T2V-ComBench上取得显著提升。
📝 摘要(中文)
故事视频生成(SVG)旨在生成遵循结构化叙事的连贯且视觉丰富的多场景视频。现有方法主要采用LLM进行高层规划,将故事分解为场景级描述,然后独立生成并拼接在一起。然而,这些方法难以生成与复杂单场景描述对齐的高质量视频,因为可视化这种复杂描述涉及多个角色和事件的连贯组合、复杂的运动合成和多角色定制。为了解决这些挑战,我们提出了DREAMRUNNER,一种新的故事到视频生成方法:首先,我们使用大型语言模型(LLM)来构建输入脚本,以促进粗粒度的场景规划以及细粒度的对象级布局规划。接下来,DREAMRUNNER提出检索增强的测试时自适应,以捕获每个场景中对象的运动先验,支持基于检索视频的各种运动定制,从而促进生成具有复杂、脚本化运动的新视频。最后,我们提出了一种新的基于空间-时间区域的3D注意力和先验注入模块SR3AI,用于细粒度的对象-运动绑定和逐帧空间-时间语义控制。我们将DREAMRUNNER与各种SVG基线进行比较,证明了其在角色一致性、文本对齐和平滑过渡方面的最先进性能。此外,DREAMRUNNER在组合文本到视频生成中表现出强大的细粒度条件遵循能力,在T2V-ComBench上显著优于基线。最后,我们通过定性示例验证了DREAMRUNNER生成多对象交互的强大能力。
🔬 方法详解
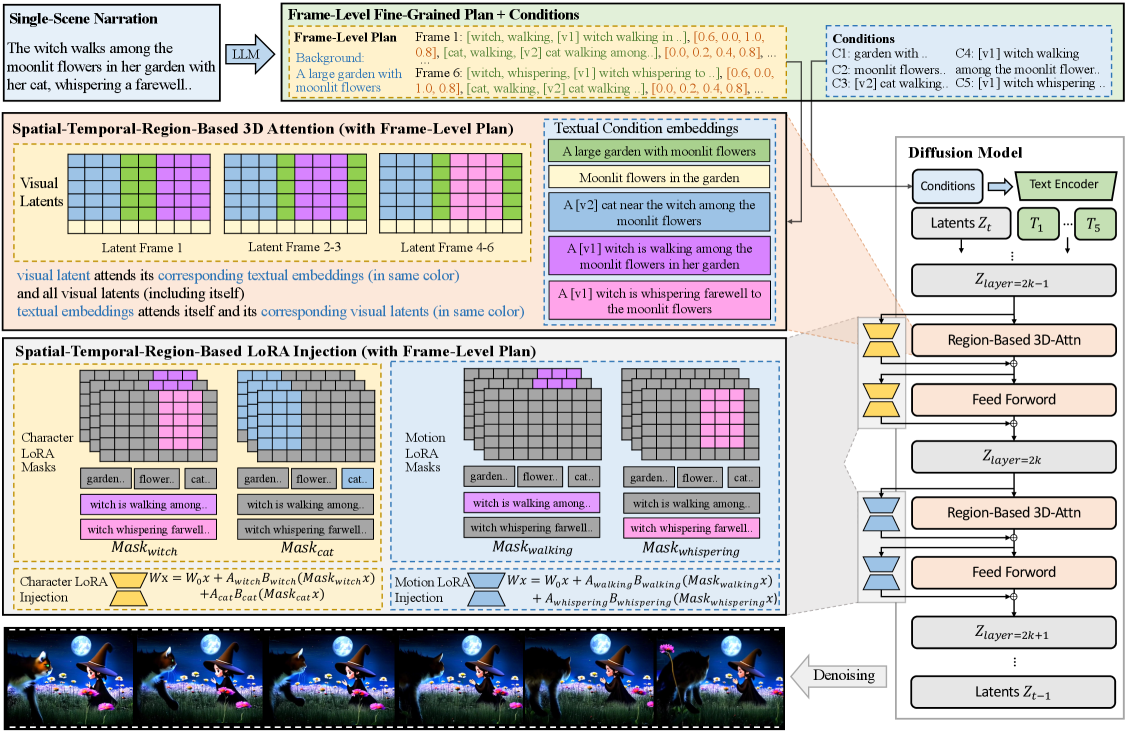
问题定义:现有故事到视频生成方法主要依赖大型语言模型进行粗粒度的场景规划,然后独立生成各个场景并拼接。这种方法难以处理复杂的单场景描述,尤其是在角色众多、动作复杂的情况下,生成的视频往往缺乏角色一致性和运动的真实性。现有方法难以实现细粒度的对象控制和运动定制,导致生成视频的质量受限。
核心思路:DreamRunner的核心思路是通过细粒度的场景和对象规划,以及检索增强的运动适配,来提升生成视频的质量和真实性。首先,利用LLM进行更精细的场景和对象布局规划,为后续的视频生成提供更精确的指导。然后,通过检索相关的视频片段,提取运动先验,并将其融入到生成过程中,从而实现更逼真的运动效果。
技术框架:DreamRunner的整体框架包括以下几个主要模块:1) LLM驱动的场景和对象规划:利用LLM将故事分解为细粒度的场景描述,并规划每个场景中的对象布局。2) 检索增强的运动适配:通过检索相关的视频片段,提取运动先验,并将其用于指导视频生成。3) 空间-时间区域的3D注意力和先验注入模块(SR3AI):用于细粒度的对象-运动绑定和逐帧空间-时间语义控制。整个流程是从故事脚本开始,经过LLM规划、运动检索和适配,最终生成高质量的视频。
关键创新:DreamRunner的关键创新在于:1) 细粒度的场景和对象规划:通过LLM进行更精细的规划,为视频生成提供更精确的指导。2) 检索增强的运动适配:通过检索相关的视频片段,提取运动先验,并将其融入到生成过程中,从而实现更逼真的运动效果。3) SR3AI模块:用于细粒度的对象-运动绑定和逐帧空间-时间语义控制,进一步提升了生成视频的质量。与现有方法相比,DreamRunner能够更好地处理复杂的场景描述,生成更逼真、更符合故事设定的视频。
关键设计:SR3AI模块是关键设计之一,它利用空间-时间区域的3D注意力机制,将对象和运动进行绑定,并注入运动先验。具体的网络结构和损失函数细节未知,但可以推测其目标是最小化生成视频与检索到的运动先验之间的差异,并保证生成视频的连贯性和真实性。检索模块的具体实现方式(例如,使用何种嵌入模型进行视频检索)也未知。
🖼️ 关键图片


📊 实验亮点
DreamRunner在多个故事视频生成基准测试中取得了最先进的性能,尤其是在角色一致性、文本对齐和平滑过渡方面。在T2V-ComBench上,DreamRunner显著优于现有基线,证明了其强大的细粒度条件遵循能力。定性结果也表明,DreamRunner能够生成具有复杂多对象交互的视频,验证了其在复杂场景下的生成能力。
🎯 应用场景
DreamRunner在游戏开发、电影制作、教育娱乐等领域具有广泛的应用前景。它可以用于自动生成游戏过场动画、电影片段,或者为教育内容创建生动的视频素材。该技术还可以应用于虚拟现实和增强现实领域,为用户提供更沉浸式的体验。未来,DreamRunner有望成为内容创作的重要工具,降低视频制作的成本和门槛。
📄 摘要(原文)
Storytelling video generation (SVG) aims to produce coherent and visually rich multi-scene videos that follow a structured narrative. Existing methods primarily employ LLM for high-level planning to decompose a story into scene-level descriptions, which are then independently generated and stitched together. However, these approaches struggle with generating high-quality videos aligned with the complex single-scene description, as visualizing such complex description involves coherent composition of multiple characters and events, complex motion synthesis and multi-character customization. To address these challenges, we propose DREAMRUNNER, a novel story-to-video generation method: First, we structure the input script using a large language model (LLM) to facilitate both coarse-grained scene planning as well as fine-grained object-level layout planning. Next, DREAMRUNNER presents retrieval-augmented test-time adaptation to capture target motion priors for objects in each scene, supporting diverse motion customization based on retrieved videos, thus facilitating the generation of new videos with complex, scripted motions. Lastly, we propose a novel spatial-temporal region-based 3D attention and prior injection module SR3AI for fine-grained object-motion binding and frame-by-frame spatial-temporal semantic control. We compare DREAMRUNNER with various SVG baselines, demonstrating state-of-the-art performance in character consistency, text alignment, and smooth transitions. Additionally, DREAMRUNNER exhibits strong fine-grained condition-following ability in compositional text-to-video generation, significantly outperforming baselines on T2V-ComBench. Finally, we validate DREAMRUNNER's robust ability to generate multi-object interactions with qualitative examples.