Chat2SVG: Vector Graphics Generation with Large Language Models and Image Diffusion Models
作者: Ronghuan Wu, Wanchao Su, Jing Liao
分类: cs.CV, cs.GR
发布日期: 2024-11-25 (更新: 2025-11-12)
备注: Project Page: https://chat2svg.github.io/
💡 一句话要点
Chat2SVG:结合大语言模型与图像扩散模型的矢量图形生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到SVG生成 矢量图形 大语言模型 图像扩散模型 几何建模 自然语言编辑 混合模型
📋 核心要点
- 现有文本到SVG生成方法在形状规则性、泛化能力和表达性方面存在局限性,难以生成高质量的矢量图形。
- Chat2SVG利用大语言模型生成SVG模板,并结合图像扩散模型进行双阶段优化,提升几何复杂度和视觉效果。
- 实验结果表明,Chat2SVG在视觉保真度、路径规则性和语义对齐方面优于现有方法,并支持自然语言编辑。
📝 摘要(中文)
可缩放矢量图形(SVG)已成为数字设计中矢量图形的事实标准,它具有分辨率独立性和对各个元素的精确控制。尽管SVG有诸多优点,但创建高质量的SVG内容仍然具有挑战性,因为它需要专业的编辑软件技术以及大量的时间来制作复杂的形状。最近的文本到SVG生成方法旨在使矢量图形的创建更容易,但它们在形状规则性、泛化能力和表达性方面仍然存在局限性。为了应对这些挑战,我们提出了Chat2SVG,这是一个混合框架,它结合了大语言模型(LLM)和图像扩散模型的优势,用于文本到SVG的生成。我们的方法首先使用LLM从基本的几何图元生成语义上有意义的SVG模板。在图像扩散模型的指导下,一个双阶段优化流程在潜在空间中细化路径,并调整点坐标以增强几何复杂性。大量的实验表明,Chat2SVG在视觉保真度、路径规则性和语义对齐方面优于现有方法。此外,我们的系统还支持通过自然语言指令进行直观的编辑,使所有用户都可以进行专业的矢量图形创建。
🔬 方法详解
问题定义:论文旨在解决文本到SVG生成任务中,现有方法生成的矢量图形在形状规则性、泛化能力和表达性方面存在的不足。现有方法难以生成具有复杂几何形状和良好视觉效果的SVG图像,且缺乏直观的编辑能力。
核心思路:论文的核心思路是结合大语言模型(LLM)和图像扩散模型的优势。LLM负责生成具有语义信息的SVG模板,提供初始的结构和内容;图像扩散模型则负责指导SVG模板的优化,提升视觉质量和几何复杂度。这种混合方法旨在克服现有方法在规则性、泛化性和表达性方面的局限性。
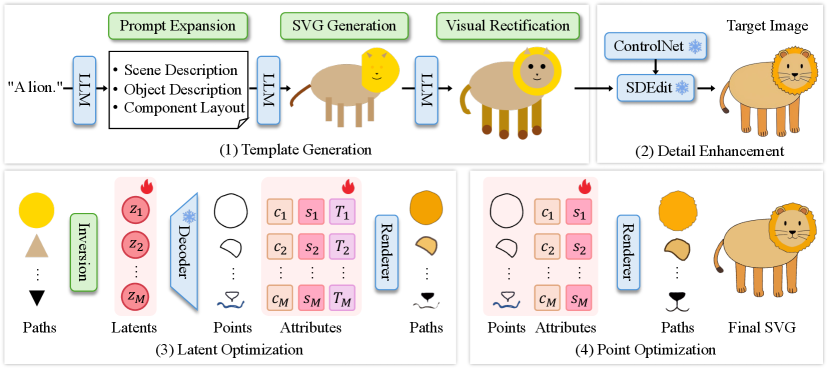
技术框架:Chat2SVG框架包含两个主要阶段:1) LLM驱动的SVG模板生成:利用LLM将文本描述转换为由基本几何图元组成的SVG模板。LLM负责理解文本语义,并生成相应的SVG结构。2) 图像扩散模型引导的双阶段优化:该阶段包含两个子阶段:a) 潜在空间路径优化:利用图像扩散模型在潜在空间中优化SVG路径,使其更符合目标图像的视觉特征。b) 点坐标调整:调整SVG路径上的点坐标,进一步提升几何复杂度和视觉效果。
关键创新:该方法最重要的创新点在于结合了LLM的语义理解能力和图像扩散模型的图像生成能力,实现了一种混合的文本到SVG生成框架。与现有方法相比,Chat2SVG能够生成更具语义信息、视觉效果更好、几何形状更复杂的SVG图像。此外,该框架还支持通过自然语言指令进行编辑,提高了用户交互的便捷性。
关键设计:在LLM驱动的SVG模板生成阶段,使用了预训练的LLM(具体模型未知)进行文本到SVG代码的转换。在图像扩散模型引导的双阶段优化阶段,使用了预训练的图像扩散模型(具体模型未知)作为视觉引导。潜在空间路径优化和点坐标调整的具体实现细节(如损失函数、优化算法等)未知。
🖼️ 关键图片

📊 实验亮点
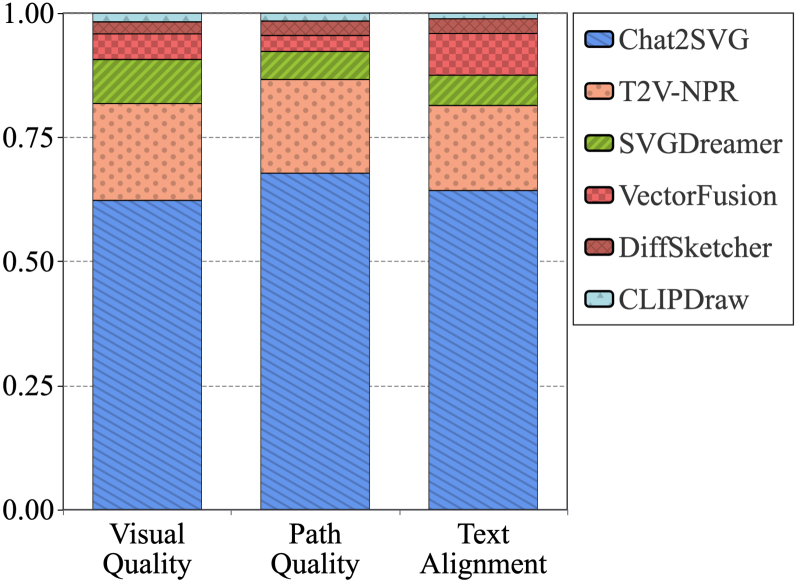
实验结果表明,Chat2SVG在视觉保真度、路径规则性和语义对齐方面显著优于现有方法。具体性能数据和对比基线未知,但论文强调了在视觉质量和语义一致性方面的提升。此外,Chat2SVG支持自然语言编辑,为用户提供了更直观的交互方式。
🎯 应用场景
Chat2SVG具有广泛的应用前景,包括数字艺术创作、网页设计、图形设计、教育等领域。它可以帮助设计师和艺术家更高效地创建高质量的矢量图形,降低矢量图形创作的门槛。此外,该技术还可以应用于自动化内容生成、个性化定制等场景,具有重要的实际价值和商业潜力。未来,该技术有望进一步发展,实现更复杂、更逼真的矢量图形生成。
📄 摘要(原文)
Scalable Vector Graphics (SVG) has become the de facto standard for vector graphics in digital design, offering resolution independence and precise control over individual elements. Despite their advantages, creating high-quality SVG content remains challenging, as it demands technical expertise with professional editing software and a considerable time investment to craft complex shapes. Recent text-to-SVG generation methods aim to make vector graphics creation more accessible, but they still encounter limitations in shape regularity, generalization ability, and expressiveness. To address these challenges, we introduce Chat2SVG, a hybrid framework that combines the strengths of Large Language Models (LLMs) and image diffusion models for text-to-SVG generation. Our approach first uses an LLM to generate semantically meaningful SVG templates from basic geometric primitives. Guided by image diffusion models, a dual-stage optimization pipeline refines paths in latent space and adjusts point coordinates to enhance geometric complexity. Extensive experiments show that Chat2SVG outperforms existing methods in visual fidelity, path regularity, and semantic alignment. Additionally, our system enables intuitive editing through natural language instructions, making professional vector graphics creation accessible to all users.