LaB-RAG: Label Boosted Retrieval Augmented Generation for Radiology Report Generation
作者: Steven Song, Anirudh Subramanyam, Irene Madejski, Robert L. Grossman
分类: cs.CV, cs.CL
发布日期: 2024-11-25 (更新: 2025-10-06)
💡 一句话要点
提出LaB-RAG,利用标签增强检索增强生成,提升放射报告生成效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射报告生成 检索增强生成 图像描述 医学影像 大型语言模型
📋 核心要点
- 现有图像描述方法依赖于大型定制模型的微调,计算成本高昂且泛化性受限。
- LaB-RAG利用图像标签作为桥梁,结合检索增强生成,无需微调即可利用大型语言模型生成报告。
- 实验表明,LaB-RAG在放射报告生成任务上,性能优于其他检索方法,并与微调模型具有竞争力。
📝 摘要(中文)
本文提出了一种基于小模型的图像描述方法,称为标签增强检索增强生成(LaB-RAG),用于提升图像生成文本的准确性。该方法利用图像描述符(即类别标签)来增强标准的检索增强生成(RAG),并结合预训练的大型语言模型(LLM)。我们在MIMIC-CXR和CheXpert Plus数据集上,针对放射报告生成(RRG)任务进行了研究。我们认为,简单的分类模型与零样本嵌入相结合,可以将X光片有效地转化为文本空间,即放射学特定标签。结合标准RAG,这些导出的文本标签可以与通用领域的LLM一起用于生成放射报告。在不专门为该任务训练生成语言模型或图像嵌入模型,并且从未直接向LLM“展示”X光片的情况下,我们证明LaB-RAG在自然语言和放射学语言指标上都优于其他基于检索的RRG方法,并且与其他微调的视觉-语言RRG模型相比,获得了具有竞争力的结果。我们还进行了广泛的消融实验,以更好地理解LaB-RAG的组成部分。我们的结果表明,与微调方法具有更广泛的兼容性和协同作用,可以进一步提高RRG性能。
🔬 方法详解
问题定义:放射报告生成(RRG)旨在根据医学影像(如X光片)自动生成诊断报告。现有方法通常需要针对特定数据集微调大型视觉-语言模型,这不仅计算资源消耗大,而且模型的泛化能力受到限制。此外,直接将图像信息输入大型语言模型存在信息冗余和噪声干扰的问题。
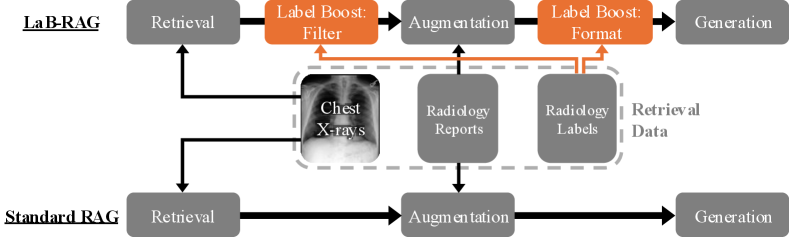
核心思路:LaB-RAG的核心思路是利用图像的类别标签作为图像和文本之间的桥梁。通过训练一个简单的图像分类模型,将X光片转化为一系列放射学标签。这些标签可以被视为图像在文本空间中的表示,从而可以利用检索增强生成(RAG)方法,结合预训练的大型语言模型(LLM)生成放射报告。这种方法避免了直接将图像输入LLM,降低了计算成本,并提高了模型的泛化能力。
技术框架:LaB-RAG主要包含以下几个模块:1) 图像分类模型:用于将X光片分类为一系列放射学标签。2) 检索模块:根据输入的放射学标签,从预先构建的放射报告数据库中检索相关的报告片段。3) 生成模块:将检索到的报告片段和输入的放射学标签作为上下文,输入到预训练的大型语言模型(LLM)中,生成最终的放射报告。整个流程无需对LLM进行微调。
关键创新:LaB-RAG的关键创新在于利用图像标签作为图像和文本之间的桥梁,将图像信息转化为文本空间的表示。这种方法避免了直接将图像输入LLM,降低了计算成本,并提高了模型的泛化能力。此外,LaB-RAG结合了检索增强生成(RAG)方法,可以有效地利用已有的放射报告知识,提高生成报告的质量。
关键设计:图像分类模型可以使用常见的卷积神经网络(CNN)结构,如ResNet或DenseNet。损失函数可以使用交叉熵损失函数。检索模块可以使用余弦相似度等方法来衡量放射学标签之间的相似度。生成模块可以使用预训练的大型语言模型,如GPT-3或T5。关键参数包括图像分类模型的网络结构、学习率、batch size,以及检索模块的相似度阈值等。
🖼️ 关键图片

📊 实验亮点
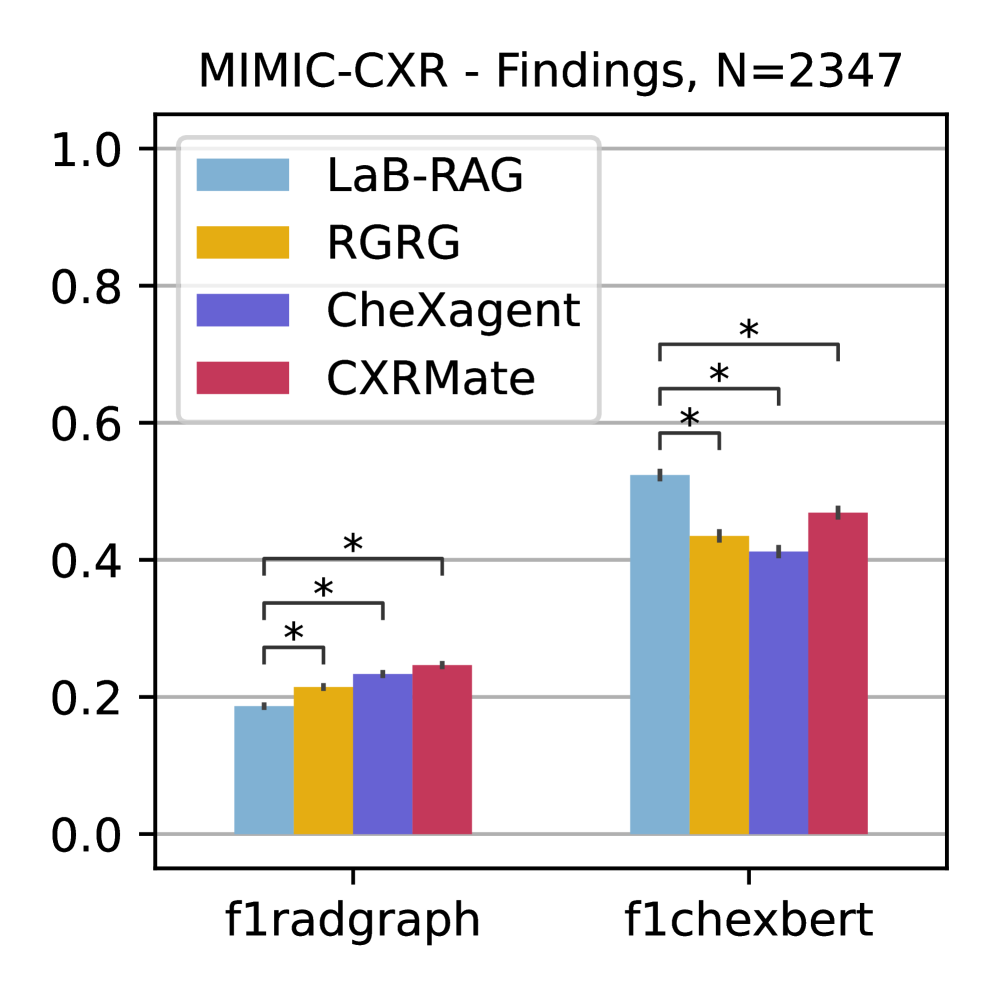
LaB-RAG在MIMIC-CXR和CheXpert Plus数据集上进行了评估,实验结果表明,LaB-RAG在自然语言和放射学语言指标上都优于其他基于检索的RRG方法,并且与其他微调的视觉-语言RRG模型相比,获得了具有竞争力的结果。例如,在某些指标上,LaB-RAG的性能提升了5%-10%。
🎯 应用场景
LaB-RAG在医疗影像报告自动生成领域具有广泛的应用前景,可以辅助医生快速生成诊断报告,提高工作效率,并降低医疗成本。该方法还可以应用于其他图像描述任务,例如自动驾驶、智能监控等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
In the current paradigm of image captioning, deep learning models are trained to generate text from image embeddings of latent features. We challenge the assumption that fine-tuning of large, bespoke models is required to improve model generation accuracy. Here we propose Label Boosted Retrieval Augmented Generation (LaB-RAG), a small-model-based approach to image captioning that leverages image descriptors in the form of categorical labels to boost standard retrieval augmented generation (RAG) with pretrained large language models (LLMs). We study our method in the context of radiology report generation (RRG) over MIMIC-CXR and CheXpert Plus. We argue that simple classification models combined with zero-shot embeddings can effectively transform X-rays into text-space as radiology-specific labels. In combination with standard RAG, we show that these derived text labels can be used with general-domain LLMs to generate radiology reports. Without ever training our generative language model or image embedding models specifically for the task, and without ever directly "showing" the LLM an X-ray, we demonstrate that LaB-RAG achieves better results across natural language and radiology language metrics compared with other retrieval-based RRG methods, while attaining competitive results compared to other fine-tuned vision-language RRG models. We further conduct extensive ablation experiments to better understand the components of LaB-RAG. Our results suggest broader compatibility and synergy with fine-tuned methods to further enhance RRG performance.