ENCLIP: Ensembling and Clustering-Based Contrastive Language-Image Pretraining for Fashion Multimodal Search with Limited Data and Low-Quality Images
作者: Prithviraj Purushottam Naik, Rohit Agarwal
分类: cs.CV, cs.AI, cs.MM
发布日期: 2024-11-25
💡 一句话要点
提出ENCLIP,通过集成和聚类提升CLIP在有限数据和低质量图像下的时尚多模态搜索性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态搜索 对比学习 图像聚类 模型集成 时尚智能 CLIP模型 低质量图像
📋 核心要点
- 时尚领域多模态搜索面临数据量少、图像质量差的挑战,传统CLIP模型难以直接应用并取得良好效果。
- ENCLIP通过训练多个CLIP模型并集成,结合聚类技术对图像进行分组,从而提升模型在小样本和低质量图像上的泛化能力。
- 实验结果验证了ENCLIP方法的有效性,证明其在数据稀缺和图像质量差的情况下,能显著提升时尚多模态搜索的性能。
📝 摘要(中文)
本文提出了一种名为ENCLIP的创新方法,旨在提升对比语言-图像预训练(CLIP)模型在时尚智能领域多模态搜索中的性能。该方法主要解决数据可用性有限和图像质量低劣带来的挑战。ENCLIP算法包括训练和集成多个CLIP模型实例,并利用聚类技术将相似图像分组。实验结果表明,该方法能够有效提升CLIP模型在时尚智能领域的性能,尤其是在数据稀缺和图像质量较差的情况下。ENCLIP为优化CLIP模型在上述场景中的应用提供了一种实用的解决方案,对时尚智能领域具有重要贡献。
🔬 方法详解
问题定义:论文旨在解决时尚领域多模态搜索中,由于数据量有限和图像质量较低,导致现有CLIP模型性能下降的问题。现有方法难以有效利用有限的数据和处理低质量的图像,从而影响搜索结果的准确性和相关性。
核心思路:ENCLIP的核心思路是通过集成多个CLIP模型来提高模型的鲁棒性和泛化能力。同时,利用聚类技术将相似的图像分组,从而在训练过程中更好地利用有限的数据,并减少低质量图像带来的噪声影响。
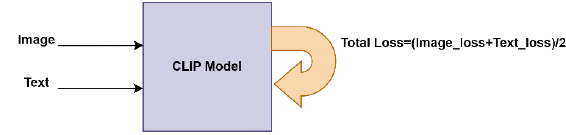
技术框架:ENCLIP方法主要包含以下几个阶段:1) 训练多个CLIP模型实例;2) 使用聚类算法(具体算法未知)对图像进行分组;3) 将分组后的图像数据用于训练集成的CLIP模型;4) 使用训练好的集成模型进行多模态搜索。整体流程旨在提高模型对图像和文本之间关系的理解,从而提升搜索准确性。
关键创新:ENCLIP的关键创新在于将模型集成和聚类技术相结合,以应对时尚领域数据稀缺和图像质量差的挑战。与传统的CLIP模型相比,ENCLIP能够更好地利用有限的数据,并降低低质量图像对模型性能的影响。这种集成和聚类的策略是ENCLIP区别于其他方法的本质特征。
关键设计:论文中未明确给出关键参数设置、损失函数和网络结构的具体细节。但是,可以推测,损失函数可能仍然采用CLIP中使用的对比损失,而网络结构则沿用CLIP的图像编码器和文本编码器。聚类算法的选择和参数设置,以及模型集成的具体方法(例如,加权平均或投票)是影响ENCLIP性能的关键设计因素,但论文中未详细说明。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了ENCLIP方法的有效性,但具体的性能数据、对比基线和提升幅度等信息在摘要中未给出。因此,实验亮点的具体细节未知。但可以推断,ENCLIP在时尚多模态搜索任务上,相比于原始CLIP模型或其他基线方法,在准确率、召回率等指标上有所提升。
🎯 应用场景
ENCLIP方法可广泛应用于电商平台的时尚商品搜索、搭配推荐等场景。通过该方法,用户可以更准确地通过文本描述或图像找到所需的时尚商品,提升用户体验和购买转化率。未来,该方法还可扩展到其他图像质量较差或数据稀缺的领域,例如医疗图像分析、遥感图像处理等。
📄 摘要(原文)
Multimodal search has revolutionized the fashion industry, providing a seamless and intuitive way for users to discover and explore fashion items. Based on their preferences, style, or specific attributes, users can search for products by combining text and image information. Text-to-image searches enable users to find visually similar items or describe products using natural language. This paper presents an innovative approach called ENCLIP, for enhancing the performance of the Contrastive Language-Image Pretraining (CLIP) model, specifically in Multimodal Search targeted towards the domain of fashion intelligence. This method focuses on addressing the challenges posed by limited data availability and low-quality images. This paper proposes an algorithm that involves training and ensembling multiple instances of the CLIP model, and leveraging clustering techniques to group similar images together. The experimental findings presented in this study provide evidence of the effectiveness of the methodology. This approach unlocks the potential of CLIP in the domain of fashion intelligence, where data scarcity and image quality issues are prevalent. Overall, the ENCLIP method represents a valuable contribution to the field of fashion intelligence and provides a practical solution for optimizing the CLIP model in scenarios with limited data and low-quality images.