KinMo: Kinematic-aware Human Motion Understanding and Generation
作者: Pengfei Zhang, Pinxin Liu, Pablo Garrido, Hyeongwoo Kim, Bindita Chaudhuri
分类: cs.CV, cs.AI, cs.GR
发布日期: 2024-11-23 (更新: 2025-08-03)
备注: Accepted to ICCV 2025; Project page: https://andypinxinliu.github.io/KinMo
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
KinMo:提出基于运动学感知的分层描述框架,用于提升人体运动理解与生成能力
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 人体运动理解 运动生成 分层表示 文本-运动对齐 运动学感知
📋 核心要点
- 现有方法依赖全局动作描述,忽略了运动细节,导致文本与运动模态间存在歧义。
- KinMo提出分层可描述的运动表示,结合运动学群组运动及其交互,实现细粒度描述。
- 实验表明,KinMo显著提升了文本-运动检索性能,并实现了更细粒度的运动生成和编辑。
📝 摘要(中文)
当前的人体运动合成框架依赖于全局动作描述,这造成了一种模态差距,限制了运动理解和生成能力。单一的粗略描述(如“跑”)无法捕捉速度、肢体位置和运动学动态等细节变化,导致文本和运动模态之间的歧义。为了解决这个问题,我们提出了KinMo,一个统一的框架,它建立在分层可描述的运动表示之上,通过结合运动学群组运动及其相互作用来扩展全局动作。我们设计了一个自动标注流程,为这种分解生成高质量、细粒度的描述,从而产生了KinMo数据集,并为数据集丰富提供了一种可扩展且经济高效的解决方案。为了利用这些结构化描述,我们提出了分层文本-运动对齐,逐步整合额外的运动细节,从而提高语义运动理解。此外,我们引入了一种由粗到精的运动生成程序,以利用增强的空间理解来改进运动合成。实验结果表明,KinMo显著提高了运动理解能力,这通过增强的文本-运动检索性能以及实现更细粒度的运动生成和编辑能力得到证明。
🔬 方法详解
问题定义:现有的人体运动合成方法主要依赖于全局动作描述,例如“跑步”、“跳跃”等。这种粗粒度的描述方式无法捕捉到运动过程中的细节变化,例如速度的快慢、肢体位置的细微差异以及运动学动态的变化。这导致文本描述和实际运动之间存在较大的模态差距,限制了运动理解和生成的能力。现有方法难以实现细粒度的运动控制和编辑。
核心思路:KinMo的核心思路是将人体运动分解为更细粒度的运动学群组运动及其相互作用,并为这些细粒度的运动单元生成高质量的文本描述。通过这种分层描述的方式,KinMo能够更精确地捕捉运动的细节信息,从而缩小文本和运动模态之间的差距。此外,KinMo还设计了分层文本-运动对齐方法,逐步整合运动细节,提升语义运动理解。
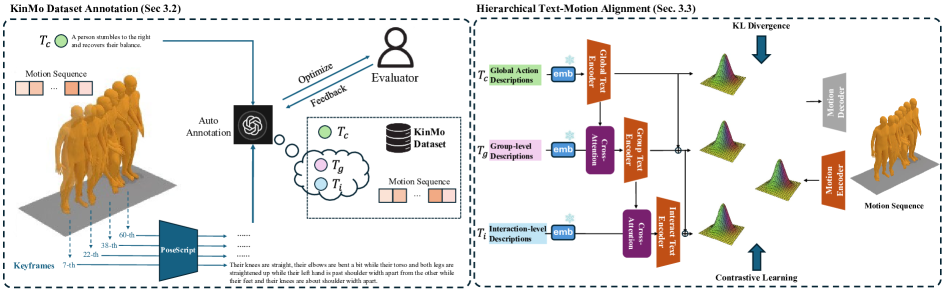
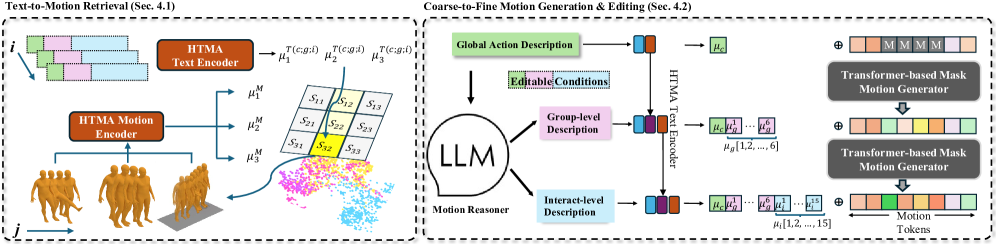
技术框架:KinMo框架主要包含以下几个关键模块:1) 自动标注流程:用于生成高质量、细粒度的运动描述,构建KinMo数据集。2) 分层运动表示:将人体运动分解为运动学群组运动及其相互作用。3) 分层文本-运动对齐:逐步整合运动细节,提升语义运动理解。4) 由粗到精的运动生成:利用增强的空间理解来改进运动合成。
关键创新:KinMo最重要的创新点在于其分层可描述的运动表示方法。与传统的全局动作描述方法不同,KinMo能够捕捉到运动过程中的细节变化,从而实现更精确的运动理解和生成。此外,KinMo提出的自动标注流程为数据集的构建提供了一种可扩展且经济高效的解决方案。
关键设计:KinMo的关键设计包括:1) 自动标注流程的设计,需要保证标注的质量和效率。2) 分层运动表示的粒度选择,需要在细节和计算复杂度之间进行权衡。3) 分层文本-运动对齐方法的具体实现,需要考虑如何有效地整合不同层次的运动信息。4) 由粗到精的运动生成过程,需要设计合适的网络结构和损失函数,以保证生成运动的自然性和真实性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
KinMo通过实验验证了其在运动理解和生成方面的优越性。实验结果表明,KinMo显著提高了文本-运动检索性能,这意味着KinMo能够更准确地理解文本描述所对应的运动。此外,KinMo还实现了更细粒度的运动生成和编辑能力,例如可以根据文本描述生成不同速度的跑步动作,或对运动进行局部编辑。具体的性能数据和对比基线在论文中未详细说明,属于未知信息。
🎯 应用场景
KinMo的研究成果具有广泛的应用前景,例如:1) 虚拟现实和增强现实:可以生成更逼真、更自然的虚拟人物运动。2) 游戏开发:可以实现更精细的运动控制和角色动画。3) 运动分析和康复:可以用于分析运动员的运动姿态,或辅助患者进行康复训练。4) 人机交互:可以使机器人能够理解人类的运动意图,并做出相应的反应。未来,KinMo有望推动人机交互、虚拟现实等领域的发展。
📄 摘要(原文)
Current human motion synthesis frameworks rely on global action descriptions, creating a modality gap that limits both motion understanding and generation capabilities. A single coarse description, such as run, fails to capture details such as variations in speed, limb positioning, and kinematic dynamics, leading to ambiguities between text and motion modalities. To address this challenge, we introduce KinMo, a unified framework built on a hierarchical describable motion representation that extends beyond global actions by incorporating kinematic group movements and their interactions. We design an automated annotation pipeline to generate high-quality, fine-grained descriptions for this decomposition, resulting in the KinMo dataset and offering a scalable and cost-efficient solution for dataset enrichment. To leverage these structured descriptions, we propose Hierarchical Text-Motion Alignment that progressively integrates additional motion details, thereby improving semantic motion understanding. Furthermore, we introduce a coarse-to-fine motion generation procedure to leverage enhanced spatial understanding to improve motion synthesis. Experimental results show that KinMo significantly improves motion understanding, demonstrated by enhanced text-motion retrieval performance and enabling more fine-grained motion generation and editing capabilities. Project Page: https://andypinxinliu.github.io/KinMo