Context-Aware Multimodal Pretraining
作者: Karsten Roth, Zeynep Akata, Dima Damen, Ivana Balažević, Olivier J. Hénaff
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-11-22
💡 一句话要点
提出上下文感知多模态预训练,提升视觉-语言模型在少样本学习中的适应性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态预训练 上下文感知 少样本学习 视觉-语言模型 对比学习
📋 核心要点
- 现有视觉-语言预训练模型在少样本学习中适应性不足,缺乏对上下文信息的有效利用。
- 论文提出上下文感知多模态预训练方法,使模型能够利用额外上下文信息,提升少样本适应能力。
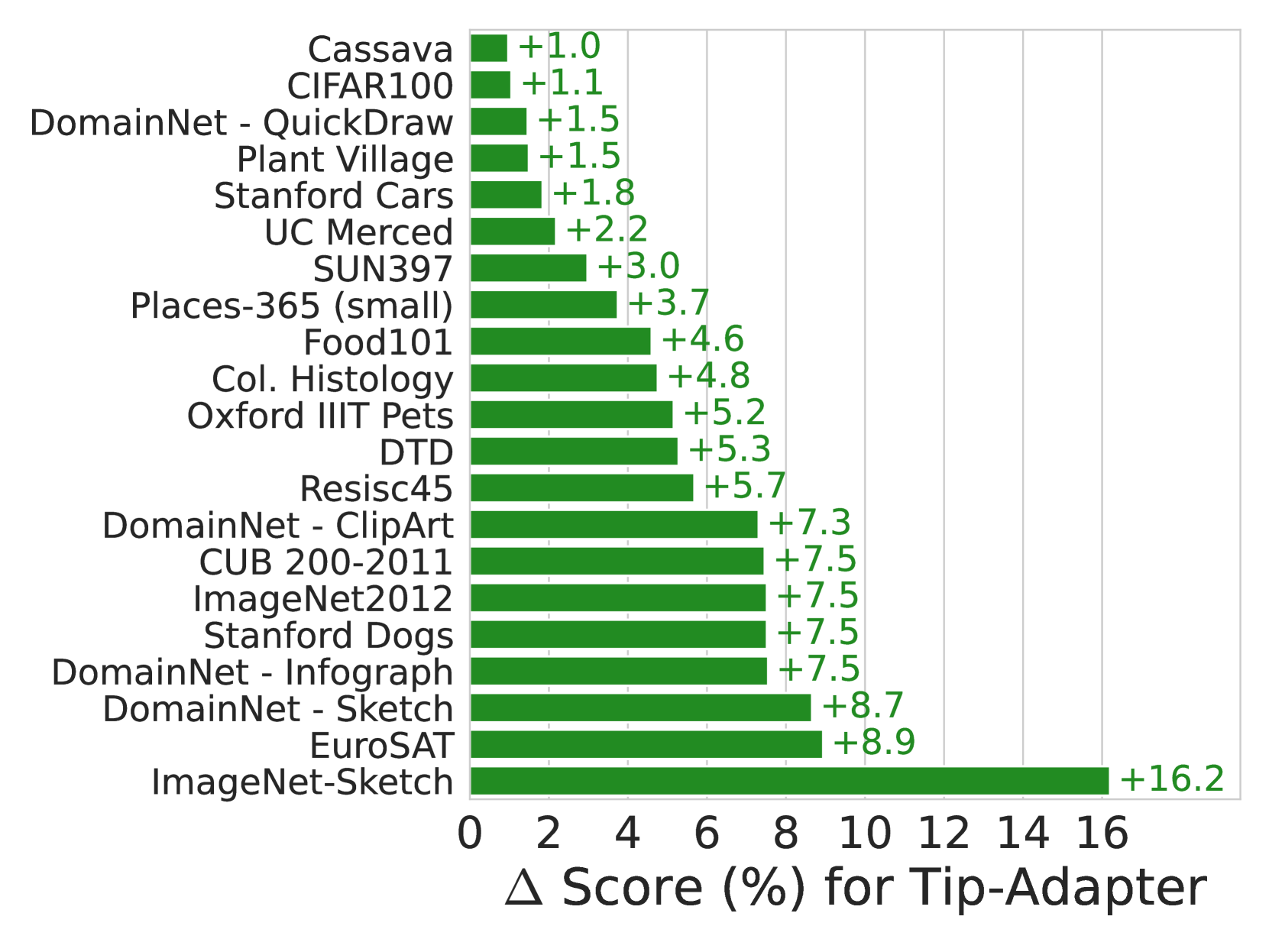
- 实验表明,该方法在多个下游任务中显著提升了少样本学习性能,同时保持了零样本泛化能力。
📝 摘要(中文)
大规模多模态表征学习在测试时成功地优化了零样本迁移。然而,标准的预训练范式(基于大量图像-文本数据的对比学习)并没有明确地鼓励表征支持少样本适应。本文提出了一种简单但经过精心设计的扩展,用于多模态预训练,使表征能够适应额外的上下文。通过使用该目标,我们证明了视觉-语言模型可以被训练成表现出显著提高的少样本适应性:在21个下游任务中,我们发现测试时样本效率提高了四倍,平均少样本适应增益超过5%,同时保持了跨模型规模和训练时长的零样本泛化性能。特别地,配备了简单的、无需训练的、基于度量的适应机制,我们的表征很容易超过更复杂和昂贵的基于优化的方案,从而大大简化了对新领域的泛化。
🔬 方法详解
问题定义:现有的大规模多模态预训练方法,例如基于对比学习的方法,虽然在零样本迁移方面表现出色,但缺乏对少样本学习的优化。这些方法没有充分利用上下文信息,导致模型在面对新任务时需要大量的样本才能适应。因此,如何提高视觉-语言模型在少样本学习中的适应性是一个关键问题。
核心思路:本文的核心思路是通过引入上下文感知机制,使模型能够更好地利用少量样本中的信息。具体来说,模型在预训练阶段学习如何根据给定的上下文调整其表征,从而在少样本学习阶段能够更快地适应新任务。这种方法避免了复杂的优化过程,而是通过简单的度量学习来实现快速适应。
技术框架:该方法在标准的多模态预训练框架的基础上,增加了一个上下文编码器。整体流程如下:首先,输入图像和文本数据,以及相应的上下文信息(例如,任务描述或少量样本)。然后,图像和文本数据通过各自的编码器提取特征,上下文信息通过上下文编码器提取特征。接下来,将图像、文本和上下文特征进行融合,得到最终的表征。最后,使用对比学习目标函数对模型进行训练,使模型能够学习到与上下文相关的表征。
关键创新:该方法最重要的创新点在于引入了上下文感知机制,使得模型能够根据上下文信息调整其表征。与传统的预训练方法相比,该方法能够更好地利用少量样本中的信息,从而提高少样本学习的性能。此外,该方法采用简单的度量学习方法进行适应,避免了复杂的优化过程,大大简化了模型的部署和应用。
关键设计:在具体实现上,上下文编码器可以使用Transformer或其他序列模型。损失函数采用对比学习损失,例如InfoNCE。关键的设计在于如何有效地融合图像、文本和上下文特征。一种常用的方法是使用注意力机制,让模型能够根据上下文信息动态地调整图像和文本特征的权重。此外,还可以使用不同的上下文编码器和融合策略,以适应不同的任务和数据集。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在21个下游任务中,测试时样本效率提高了四倍,平均少样本适应增益超过5%,同时保持了零样本泛化性能。配备简单的基于度量的适应机制,该方法超越了更复杂和昂贵的基于优化的方案,证明了其在少样本学习方面的优越性。
🎯 应用场景
该研究成果可广泛应用于各种需要快速适应新任务的视觉-语言场景,例如:机器人导航、图像检索、视觉问答等。通过利用少量样本和上下文信息,模型能够快速适应新的环境和任务要求,降低了人工干预的成本,提高了系统的智能化水平。未来,该方法有望推动视觉-语言模型在实际应用中的普及。
📄 摘要(原文)
Large-scale multimodal representation learning successfully optimizes for zero-shot transfer at test time. Yet the standard pretraining paradigm (contrastive learning on large amounts of image-text data) does not explicitly encourage representations to support few-shot adaptation. In this work, we propose a simple, but carefully designed extension to multimodal pretraining which enables representations to accommodate additional context. Using this objective, we show that vision-language models can be trained to exhibit significantly increased few-shot adaptation: across 21 downstream tasks, we find up to four-fold improvements in test-time sample efficiency, and average few-shot adaptation gains of over 5%, while retaining zero-shot generalization performance across model scales and training durations. In particular, equipped with simple, training-free, metric-based adaptation mechanisms, our representations easily surpass more complex and expensive optimization-based schemes, vastly simplifying generalization to new domains.