Open-Vocabulary Online Semantic Mapping for SLAM
作者: Tomas Berriel Martins, Martin R. Oswald, Javier Civera
分类: cs.CV, cs.RO
发布日期: 2024-11-22 (更新: 2025-09-29)
备注: Accepted for IEEE Robotics and Automation Letters
💡 一句话要点
提出OVO:一种用于SLAM的开放词汇在线语义地图构建方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义SLAM 在线3D地图构建 CLIP模型 语义分割 机器人导航
📋 核心要点
- 现有语义SLAM方法计算和内存开销大,难以实现高效的在线开放词汇语义地图构建。
- 提出OVO方法,利用CLIP向量描述3D分割块,并通过新颖的CLIP融合方法降低计算和内存占用。
- 实验表明,OVO在分割性能上优于现有方法,并成功集成到Gaussian-SLAM和ORB-SLAM2中。
📝 摘要(中文)
本文提出了一种开放词汇在线3D语义地图构建流程,我们称之为OVO。给定一系列带有位姿的RGB-D图像帧,我们检测并跟踪3D分割块,并使用CLIP向量来描述它们。这些CLIP向量通过一种新颖的CLIP融合方法,从观察它们的视角进行计算。值得注意的是,我们的OVO比离线基线具有显著更低的计算和内存占用,同时显示出比离线和在线方法更好的分割指标。除了卓越的分割性能外,我们还展示了我们的地图构建贡献与两个不同的完整SLAM骨干网络(Gaussian-SLAM和ORB-SLAM2)集成的实验结果,这是首次使用神经网络来融合CLIP描述符,并展示了具有回环检测的端到端开放词汇在线3D地图构建。
🔬 方法详解
问题定义:现有语义SLAM方法在构建3D语义地图时,通常依赖于预定义的词汇表,难以处理未知的物体类别。此外,离线方法计算和内存开销巨大,无法满足实时性要求。因此,需要一种能够进行开放词汇在线3D语义地图构建的方法,同时降低计算和内存占用。
核心思路:本文的核心思路是利用CLIP模型强大的zero-shot能力,将3D分割块表示为CLIP向量,从而实现开放词汇的语义描述。同时,通过一种新颖的CLIP融合方法,有效地融合来自不同视角的CLIP特征,降低计算复杂度,并提高语义描述的准确性。
技术框架:OVO的整体流程如下:1) 输入RGB-D图像序列和对应的相机位姿;2) 对图像进行3D分割,得到3D分割块;3) 使用CLIP模型提取每个分割块的CLIP向量;4) 通过CLIP融合方法,将来自不同视角的CLIP向量进行融合,得到该分割块的最终语义描述;5) 将语义信息集成到SLAM系统中,构建3D语义地图。
关键创新:本文最重要的技术创新点在于提出了一种新颖的CLIP融合方法,该方法能够有效地融合来自不同视角的CLIP特征,从而提高语义描述的准确性,并降低计算复杂度。此外,本文首次将神经网络用于融合CLIP描述符,并实现了端到端的开放词汇在线3D地图构建。
关键设计:CLIP融合方法的具体实现细节未知,论文中可能涉及一些参数设置,损失函数的设计,以及网络结构的选取,但摘要中没有明确说明。
🖼️ 关键图片
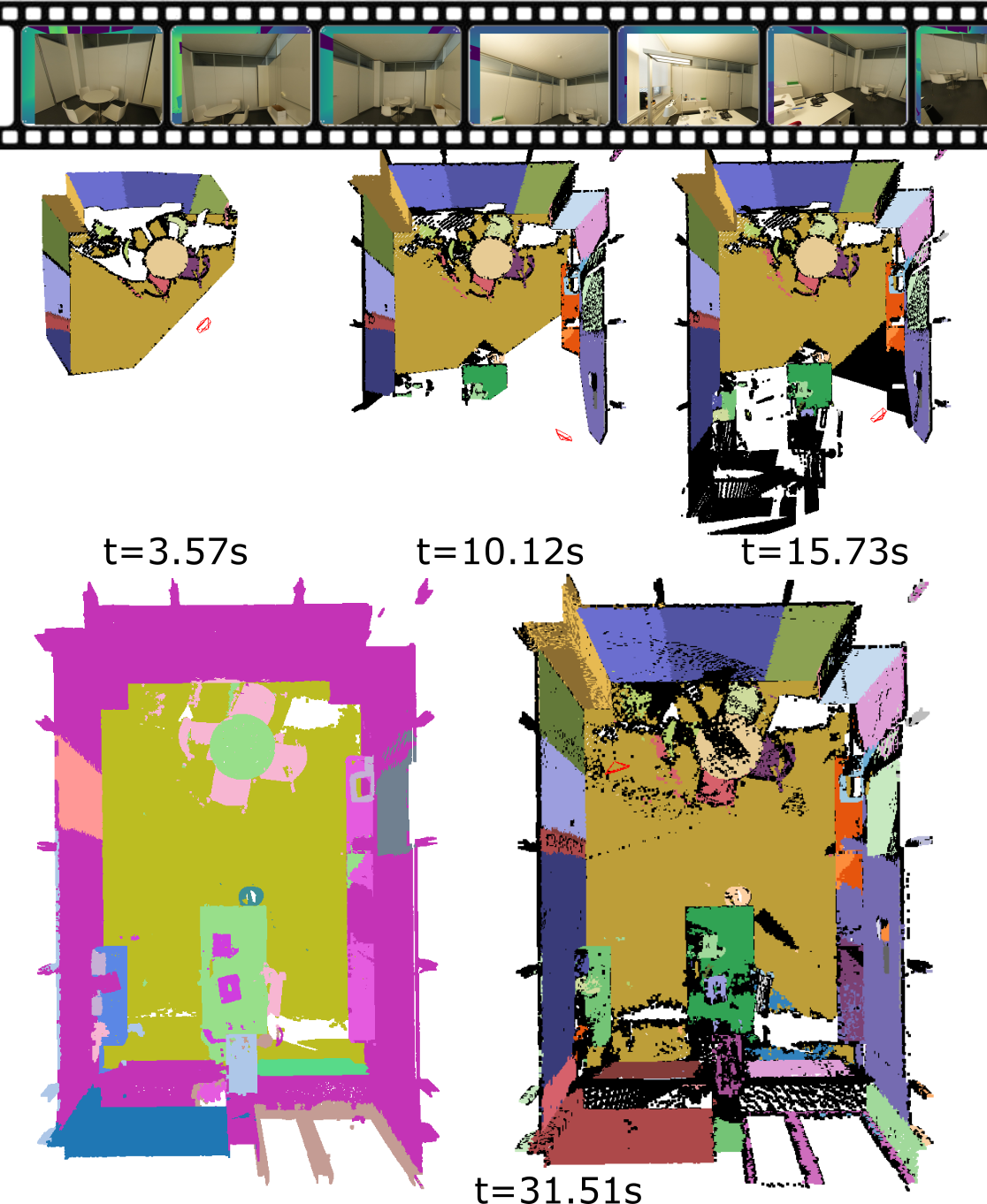
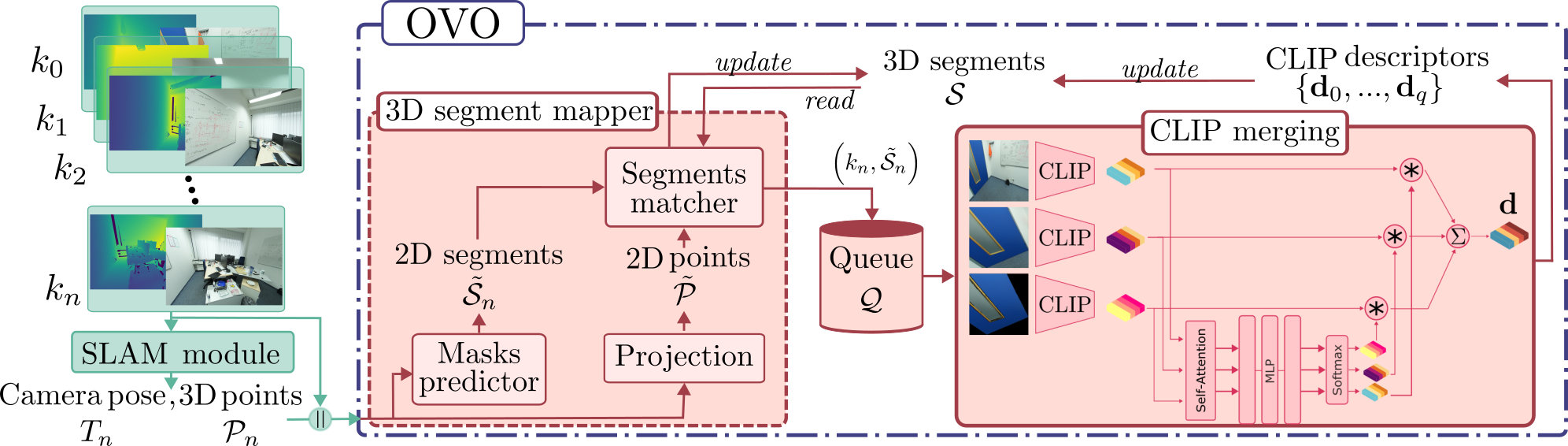

📊 实验亮点
实验结果表明,OVO方法在分割性能上优于现有的离线和在线方法。此外,OVO成功集成到Gaussian-SLAM和ORB-SLAM2中,实现了具有回环检测的端到端开放词汇在线3D地图构建。具体的性能数据和提升幅度未知,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于机器人导航、增强现实、自动驾驶等领域。例如,机器人可以在未知环境中自主探索,并识别和理解各种物体,从而更好地完成任务。在增强现实中,可以实现对真实场景的语义理解,并进行更加智能的交互。自动驾驶系统可以利用该技术识别道路上的各种物体,提高驾驶安全性。
📄 摘要(原文)
This paper presents an Open-Vocabulary Online 3D semantic mapping pipeline, that we denote by its acronym OVO. Given a sequence of posed RGB-D frames, we detect and track 3D segments, which we describe using CLIP vectors. These are computed from the viewpoints where they are observed by a novel CLIP merging method. Notably, our OVO has a significantly lower computational and memory footprint than offline baselines, while also showing better segmentation metrics than offline and online ones. Along with superior segmentation performance, we also show experimental results of our mapping contributions integrated with two different full SLAM backbones (Gaussian-SLAM and ORB-SLAM2), being the first ones using a neural network to merge CLIP descriptors and demonstrating end-to-end open-vocabulary online 3D mapping with loop closure.