Large Multi-modal Models Can Interpret Features in Large Multi-modal Models
作者: Kaichen Zhang, Yifei Shen, Bo Li, Ziwei Liu
分类: cs.CV, cs.CL
发布日期: 2024-11-22 (更新: 2025-09-18)
💡 一句话要点
提出LMM特征解析框架,利用LMM自身能力理解其内部表征,提升模型可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型多模态模型 可解释性 稀疏自编码器 特征解耦 自动解释
📋 核心要点
- 大型多模态模型内部表征的理解是一个挑战,缺乏有效的方法来解析其复杂的神经活动。
- 论文提出利用稀疏自编码器解耦表征,并设计自动解释框架,借助LMM自身能力理解其内部特征。
- 实验表明,该框架能够有效识别和解释LMM的内部语义特征,并可用于指导模型行为和分析模型错误。
📝 摘要(中文)
本文旨在解决如何理解大型多模态模型(LMMs)内部神经表征的问题,并提出了一种通用的框架来识别和解释LMMs中的语义信息。该框架首先应用稀疏自编码器(SAE)将表征解耦为人类可理解的特征。然后,提出一个自动解释框架,利用LMM本身来解释SAE学习到的开放语义特征。通过使用LLaVA-OV-72B模型分析LLaVA-NeXT-8B模型,证明这些特征可以有效地引导模型的行为。研究结果有助于更深入地理解LMMs在特定任务(包括情商测试)中表现出色的原因,并阐明其错误的本质以及潜在的纠正策略。这些发现为LMMs的内部机制提供了新的见解,并揭示了其与人脑认知过程的相似之处。
🔬 方法详解
问题定义:现有大型多模态模型(LMMs)取得了显著进展,但我们对这些模型的内部工作机制知之甚少。理解LMMs的内部神经表征是一个重要的挑战,因为这些表征通常是高维、非线性的,难以直接解释。现有的方法缺乏有效手段来剖析LMMs的内部特征,从而限制了我们对模型行为的理解和控制。
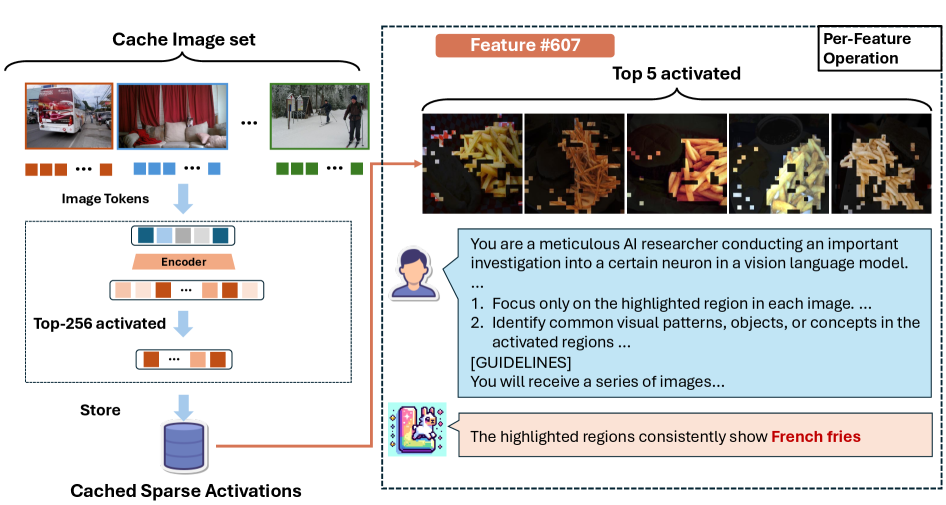
核心思路:本文的核心思路是利用LMM自身的能力来理解其内部表征。具体来说,首先使用稀疏自编码器(SAE)将LMM的内部表征解耦为一组稀疏的、更易于理解的特征。然后,设计一个自动解释框架,利用另一个LMM(或同一个LMM)来解释这些稀疏特征的语义含义。这种方法类似于人类通过观察和推理来理解复杂系统的工作原理。
技术框架:该框架包含两个主要阶段:特征解耦和特征解释。在特征解耦阶段,使用SAE对LMM的内部表征进行降维和稀疏化,得到一组开放语义特征。在特征解释阶段,将这些特征输入到另一个LMM中,并要求该LMM生成对这些特征的自然语言描述。整个流程可以看作是:LMM内部表征 -> SAE -> 开放语义特征 -> LMM解释器 -> 自然语言描述。
关键创新:该论文的关键创新在于提出了一种利用LMM自身能力来解释其内部表征的自动框架。与传统的可视化或探针方法不同,该方法不需要人工干预,并且可以处理高维、复杂的表征。此外,通过使用SAE进行特征解耦,可以得到一组稀疏的、更易于理解的特征,从而更容易进行解释。
关键设计:SAE的稀疏性约束是一个关键设计,它鼓励模型学习到一组稀疏的、具有独立语义的特征。在特征解释阶段,可以使用不同的LMM作为解释器,例如,可以使用一个更大的LMM来解释一个较小的LMM的内部特征。损失函数的设计需要保证SAE能够有效地解耦表征,并且LMM解释器能够生成准确的自然语言描述。具体的参数设置和网络结构需要根据具体的LMM和任务进行调整。
🖼️ 关键图片


📊 实验亮点
该论文使用LLaVA-OV-72B模型分析LLaVA-NeXT-8B模型,证明了该框架能够有效地识别和解释LMM的内部语义特征。实验结果表明,这些特征可以有效地引导模型的行为,并且可以用于分析模型在情商测试等任务中的表现。此外,该研究还揭示了LMM在特定任务中犯错的原因,并提出了潜在的纠正策略。
🎯 应用场景
该研究成果可应用于提升LMM的可解释性和可控性,例如,可以利用该框架诊断LMM的错误原因,并设计相应的纠正策略。此外,该框架还可以用于开发更安全、更可靠的LMM,例如,可以利用该框架识别LMM中的偏见或恶意特征,并采取措施进行缓解。该研究还有助于我们更深入地理解人工智能的内部机制,并为开发更智能、更人性化的AI系统提供新的思路。
📄 摘要(原文)
Recent advances in Large Multimodal Models (LMMs) lead to significant breakthroughs in both academia and industry. One question that arises is how we, as humans, can understand their internal neural representations. This paper takes an initial step towards addressing this question by presenting a versatile framework to identify and interpret the semantics within LMMs. Specifically, 1) we first apply a Sparse Autoencoder(SAE) to disentangle the representations into human understandable features. 2) We then present an automatic interpretation framework to interpreted the open-semantic features learned in SAE by the LMMs themselves. We employ this framework to analyze the LLaVA-NeXT-8B model using the LLaVA-OV-72B model, demonstrating that these features can effectively steer the model's behavior. Our results contribute to a deeper understanding of why LMMs excel in specific tasks, including EQ tests, and illuminate the nature of their mistakes along with potential strategies for their rectification. These findings offer new insights into the internal mechanisms of LMMs and suggest parallels with the cognitive processes of the human brain.