VisGraphVar: A Benchmark Generator for Assessing Variability in Graph Analysis Using Large Vision-Language Models
作者: Camilo Chacón Sartori, Christian Blum, Filippo Bistaffa
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-11-22
💡 一句话要点
VisGraphVar:用于评估大型视觉语言模型在图分析中变异性的基准生成器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 图分析 基准生成器 视觉变异性 鲁棒性评估
📋 核心要点
- 现有LVLMs在处理具有风格变异的视觉图分析任务时存在局限性,尤其是在节点标签、布局和视觉缺陷方面。
- VisGraphVar通过生成包含多种任务类型和视觉变异的图图像,系统地评估LVLMs在图分析任务中的性能。
- 实验表明,视觉属性的变化和视觉缺陷的引入会显著影响LVLMs的性能,强调了全面评估的重要性。
📝 摘要(中文)
大型视觉语言模型(LVLMs)的快速发展展现了巨大的潜力。这些模型越来越能够处理抽象的视觉任务。几何结构,特别是图,由于其固有的灵活性和复杂性,是评估这些模型预测能力的绝佳基准。虽然人类观察者可以很容易地识别细微的视觉细节并进行准确的分析,但我们的研究表明,最先进的LVLMs在特定的视觉图场景中表现出一致的局限性,尤其是在面对风格变化时。为了应对这些挑战,我们引入了VisGraphVar(视觉图变异性),这是一个可定制的基准生成器,能够为七个不同的任务类别(检测、分类、分割、模式识别、链接预测、推理、匹配)生成图图像,旨在系统地评估各个LVLM的优势和局限性。我们使用VisGraphVar生成了990张图图像,并评估了六个LVLM,采用了两种不同的提示策略,即零样本和思维链。研究结果表明,图像视觉属性(例如,节点标签和布局)的变化以及有意包含的视觉缺陷(例如,重叠节点)会显著影响模型性能。这项研究强调了在图相关任务中进行全面评估的重要性,而不仅仅是推理。VisGraphVar提供了宝贵的见解,可以指导开发更可靠和鲁棒的系统,从而能够执行高级视觉图分析。
🔬 方法详解
问题定义:论文旨在解决现有大型视觉语言模型(LVLMs)在处理视觉图分析任务时,对视觉变异性的鲁棒性不足的问题。现有的LVLMs在面对节点标签、布局变化以及视觉缺陷(如节点重叠)时,性能会显著下降,这限制了它们在实际应用中的可靠性。
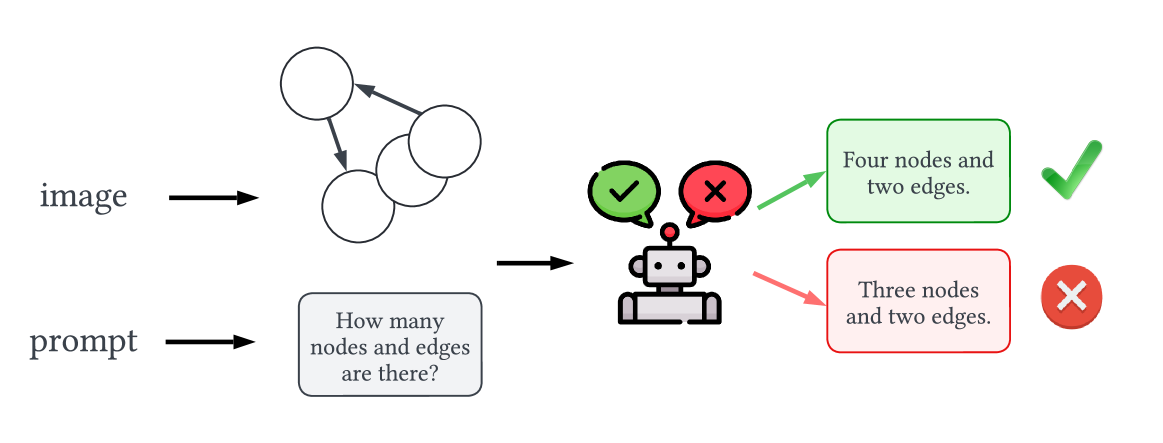
核心思路:论文的核心思路是构建一个可定制的基准生成器VisGraphVar,用于生成具有不同视觉变异性的图图像。通过系统地评估LVLMs在这些图像上的性能,可以深入了解它们的优势和局限性,从而指导开发更鲁棒的视觉图分析系统。
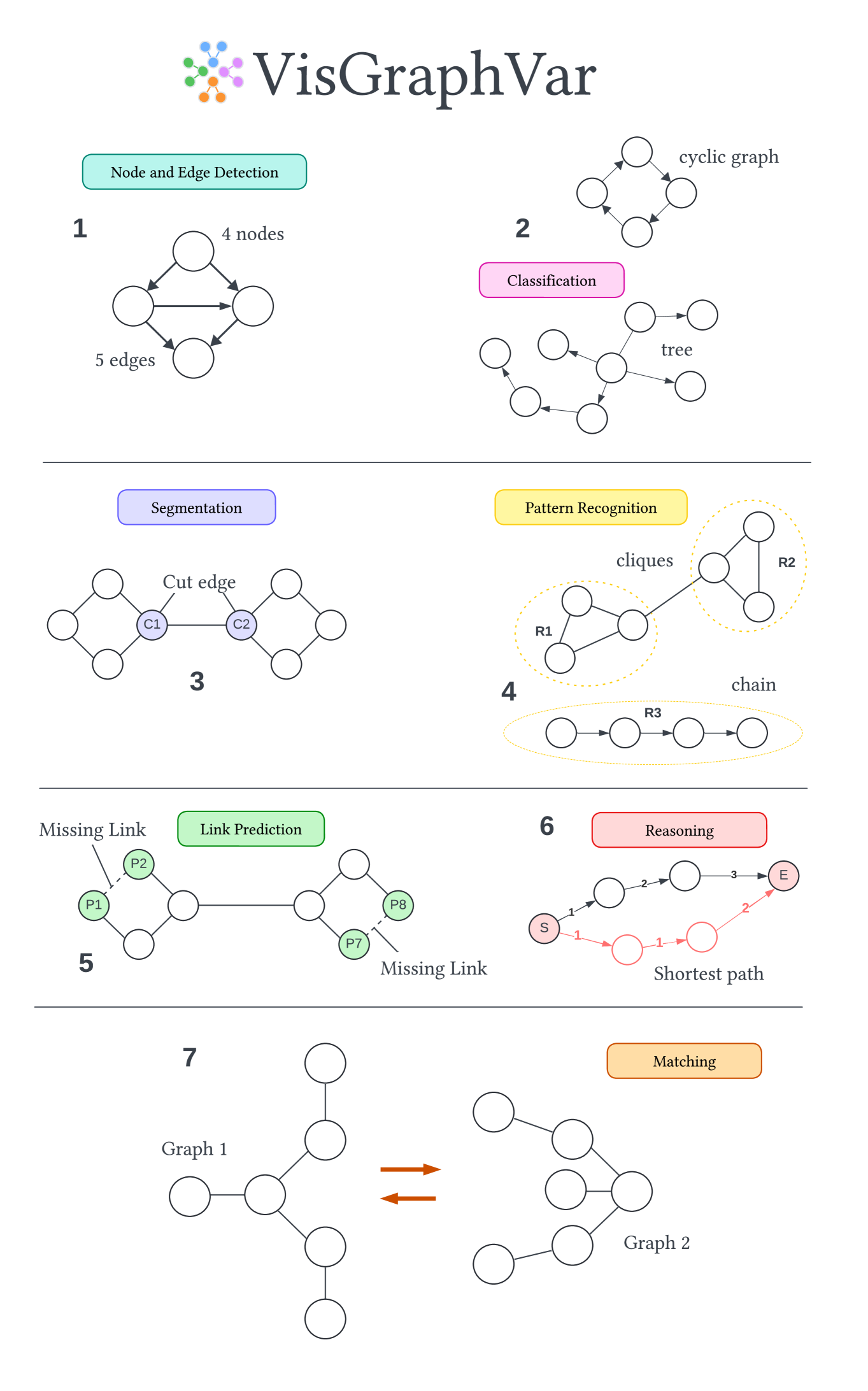
技术框架:VisGraphVar的整体框架包含以下几个主要模块:1) 任务类型选择模块:支持七种不同的图分析任务,包括检测、分类、分割、模式识别、链接预测、推理和匹配。2) 图图像生成模块:根据选定的任务类型和视觉变异参数,生成相应的图图像。3) 评估模块:使用生成的图图像评估LVLMs的性能,并分析不同视觉变异对性能的影响。4) 提示策略模块:支持零样本和思维链两种提示策略。
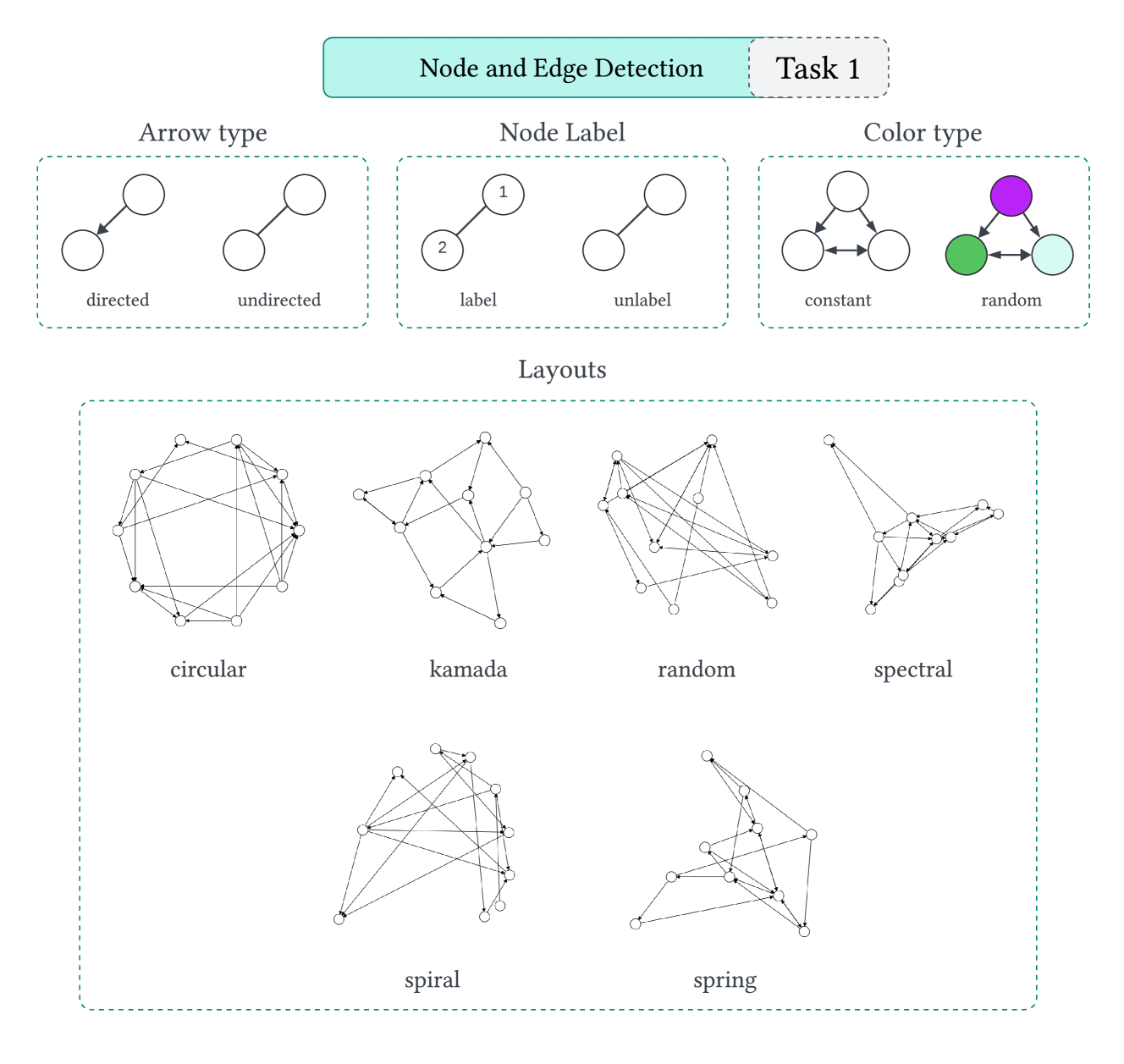
关键创新:VisGraphVar的关键创新在于其可定制的视觉变异性生成能力。它可以系统地控制节点标签、布局、节点重叠等视觉属性,从而生成具有不同难度的图图像。这使得研究人员可以更精确地评估LVLMs对不同类型视觉变异的鲁棒性。与现有方法相比,VisGraphVar不仅关注推理能力,还关注LVLMs在其他图相关任务中的表现。
关键设计:VisGraphVar的关键设计包括:1) 七种不同的图分析任务类型,覆盖了广泛的应用场景。2) 可定制的视觉变异参数,允许研究人员控制节点标签、布局、节点重叠等视觉属性。3) 两种不同的提示策略(零样本和思维链),用于评估LVLMs在不同提示方式下的性能。4) 生成了包含990张图图像的数据集,用于评估六个LVLMs。
🖼️ 关键图片
📊 实验亮点
实验结果表明,图像的视觉属性变化(如节点标签和布局)以及视觉缺陷(如节点重叠)会显著影响LVLMs的性能。例如,在某些任务中,引入视觉变异后,模型的准确率下降了10%-20%。该研究还发现,不同的提示策略(零样本和思维链)对模型性能有不同的影响,表明需要根据具体任务选择合适的提示策略。
🎯 应用场景
该研究成果可应用于开发更可靠和鲁棒的视觉图分析系统,例如在智能交通、社交网络分析、生物信息学等领域。通过提高LVLMs对视觉变异性的鲁棒性,可以使其在更复杂的实际场景中发挥作用,例如自动驾驶中的交通标志识别、社交网络中的异常行为检测等。
📄 摘要(原文)
The fast advancement of Large Vision-Language Models (LVLMs) has shown immense potential. These models are increasingly capable of tackling abstract visual tasks. Geometric structures, particularly graphs with their inherent flexibility and complexity, serve as an excellent benchmark for evaluating these models' predictive capabilities. While human observers can readily identify subtle visual details and perform accurate analyses, our investigation reveals that state-of-the-art LVLMs exhibit consistent limitations in specific visual graph scenarios, especially when confronted with stylistic variations. In response to these challenges, we introduce VisGraphVar (Visual Graph Variability), a customizable benchmark generator able to produce graph images for seven distinct task categories (detection, classification, segmentation, pattern recognition, link prediction, reasoning, matching), designed to systematically evaluate the strengths and limitations of individual LVLMs. We use VisGraphVar to produce 990 graph images and evaluate six LVLMs, employing two distinct prompting strategies, namely zero-shot and chain-of-thought. The findings demonstrate that variations in visual attributes of images (e.g., node labeling and layout) and the deliberate inclusion of visual imperfections, such as overlapping nodes, significantly affect model performance. This research emphasizes the importance of a comprehensive evaluation across graph-related tasks, extending beyond reasoning alone. VisGraphVar offers valuable insights to guide the development of more reliable and robust systems capable of performing advanced visual graph analysis.