LLaVA-MR: Large Language-and-Vision Assistant for Video Moment Retrieval
作者: Weiheng Lu, Jian Li, An Yu, Ming-Ching Chang, Shengpeng Ji, Min Xia
分类: cs.CV
发布日期: 2024-11-21
💡 一句话要点
提出LLaVA-MR,利用多模态大语言模型解决视频片段检索难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频片段检索 多模态大语言模型 长视频理解 时空特征提取 信息帧选择 动态令牌压缩 视觉推理
📋 核心要点
- 现有MLLM在长视频处理和精确片段检索方面存在挑战,主要受限于上下文长度和帧提取的粗糙性。
- LLaVA-MR通过密集帧和时间编码、信息帧选择和动态令牌压缩等技术,提升了片段检索的准确性和效率。
- 实验结果表明,LLaVA-MR在多个基准数据集上超越了现有方法,显著提升了片段检索的性能。
📝 摘要(中文)
多模态大语言模型(MLLMs)被广泛应用于视觉感知、理解和推理。然而,由于LLMs有限的上下文长度和粗糙的帧提取方式,长视频处理和精确的片段检索仍然具有挑战性。我们提出了用于片段检索的大型语言-视觉助手(LLaVA-MR),它能够利用MLLMs在视频中实现精确的片段检索和上下文定位。LLaVA-MR结合了用于时空特征提取的密集帧和时间编码(DFTE)、用于捕获简明视觉和运动模式的信息帧选择(IFS)以及用于管理LLM上下文限制的动态令牌压缩(DTC)。在Charades-STA和QVHighlights等基准数据集上的评估表明,LLaVA-MR优于11种最先进的方法,在QVHighlights数据集上,R1@0.5指标提高了1.82%,mAP@0.5指标提高了1.29%。我们的实现将在接收后开源。
🔬 方法详解
问题定义:论文旨在解决视频片段检索任务中,现有方法无法有效处理长视频和精确检索片段的问题。现有方法通常受限于MLLM的上下文长度,难以捕捉视频中的关键信息,并且粗糙的帧提取方式导致信息丢失,影响检索精度。
核心思路:论文的核心思路是结合密集帧提取、信息帧选择和动态令牌压缩,充分利用视频的时空信息,并在有限的上下文长度内保留关键帧信息,从而提升片段检索的准确性。通过这种方式,模型能够更好地理解视频内容,并精确地定位到目标片段。
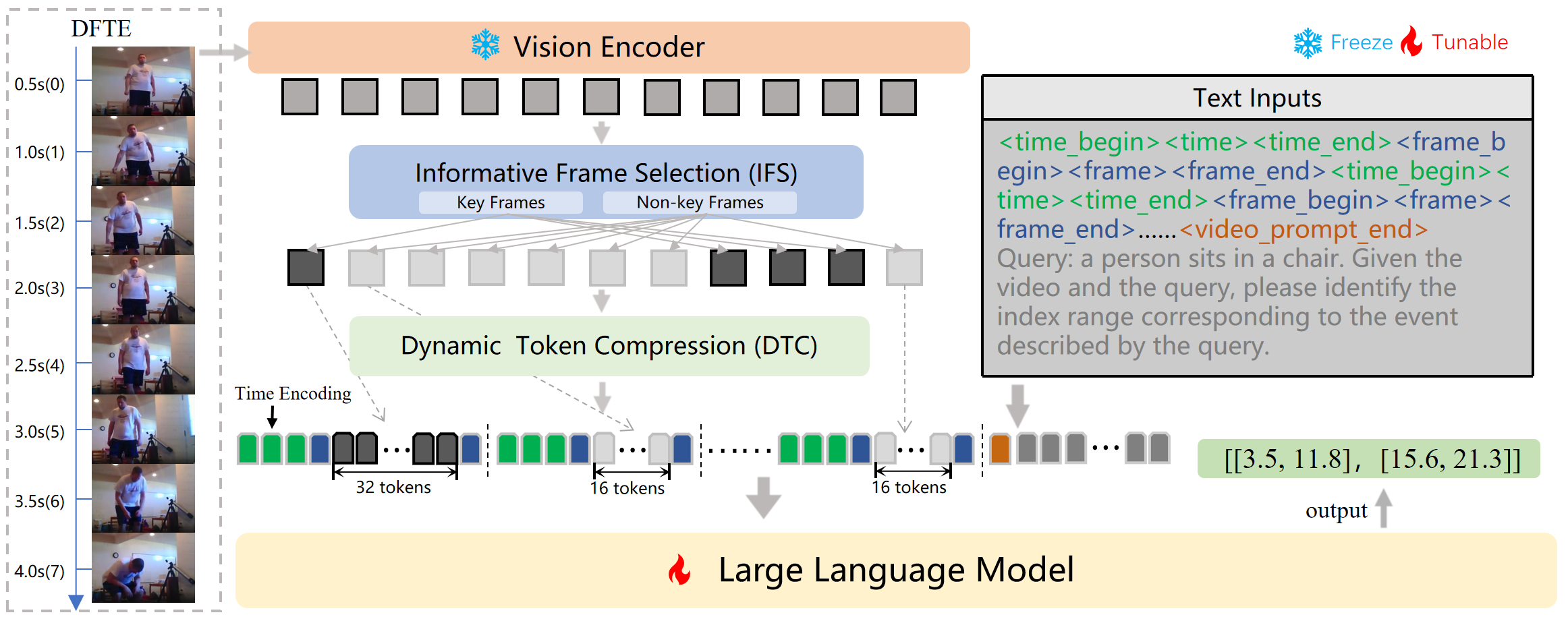
技术框架:LLaVA-MR的整体框架包含三个主要模块:1) 密集帧和时间编码(DFTE),用于提取视频的时空特征;2) 信息帧选择(IFS),用于选择包含关键视觉和运动模式的帧;3) 动态令牌压缩(DTC),用于在LLM的上下文限制下管理和压缩令牌。整个流程首先通过DFTE提取特征,然后通过IFS选择关键帧,最后通过DTC压缩令牌并输入MLLM进行片段检索。
关键创新:该论文的关键创新在于结合了密集帧提取、信息帧选择和动态令牌压缩,有效地解决了长视频片段检索中的上下文长度限制和信息丢失问题。与现有方法相比,LLaVA-MR能够更全面地捕捉视频信息,并在有限的上下文长度内保留关键信息,从而显著提升检索精度。
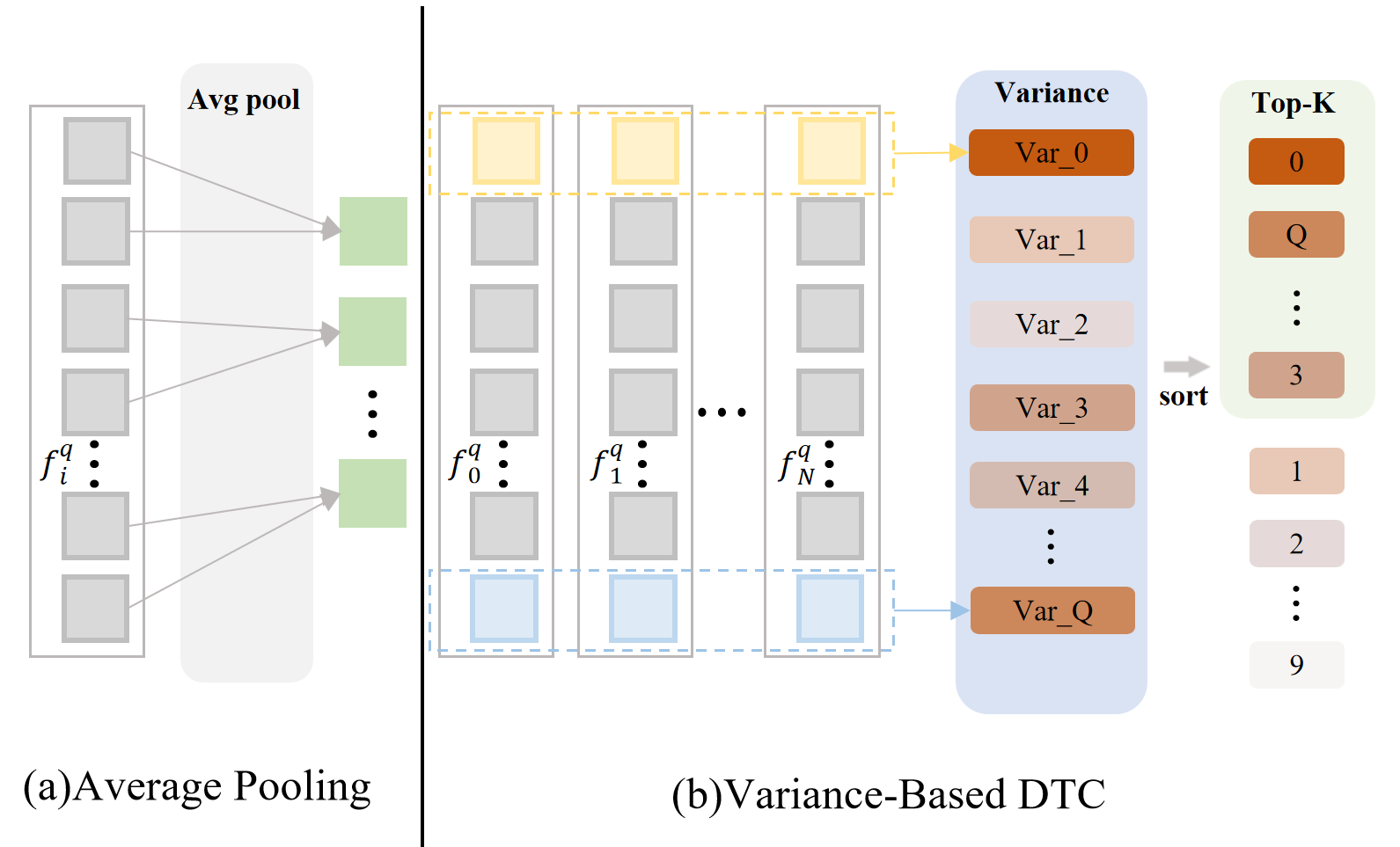
关键设计:在DFTE中,采用了密集帧提取策略,并结合时间编码来保留时间信息。IFS模块通过某种策略(论文中未明确说明具体策略,标记为未知)选择包含关键视觉和运动模式的帧。DTC模块则采用动态令牌压缩算法,根据帧的重要性自适应地压缩令牌数量,以适应LLM的上下文长度限制。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
LLaVA-MR在Charades-STA和QVHighlights等基准数据集上进行了评估,实验结果表明,LLaVA-MR优于11种最先进的方法。在QVHighlights数据集上,R1@0.5指标提高了1.82%,mAP@0.5指标提高了1.29%,证明了该方法的有效性和优越性。
🎯 应用场景
LLaVA-MR在视频内容理解、智能监控、视频编辑、教育视频检索等领域具有广泛的应用前景。该研究可以提升视频检索的准确性和效率,帮助用户快速定位到感兴趣的视频片段,具有重要的实际应用价值和商业潜力。未来,该技术有望应用于更复杂的视频分析任务,例如视频摘要生成、视频问答等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) are widely used for visual perception, understanding, and reasoning. However, long video processing and precise moment retrieval remain challenging due to LLMs' limited context size and coarse frame extraction. We propose the Large Language-and-Vision Assistant for Moment Retrieval (LLaVA-MR), which enables accurate moment retrieval and contextual grounding in videos using MLLMs. LLaVA-MR combines Dense Frame and Time Encoding (DFTE) for spatial-temporal feature extraction, Informative Frame Selection (IFS) for capturing brief visual and motion patterns, and Dynamic Token Compression (DTC) to manage LLM context limitations. Evaluations on benchmarks like Charades-STA and QVHighlights demonstrate that LLaVA-MR outperforms 11 state-of-the-art methods, achieving an improvement of 1.82% in R1@0.5 and 1.29% in mAP@0.5 on the QVHighlights dataset. Our implementation will be open-sourced upon acceptance.