Multimodal Autoregressive Pre-training of Large Vision Encoders
作者: Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, Sai Aitharaju, Victor Guilherme Turrisi da Costa, Louis Béthune, Zhe Gan, Alexander T Toshev, Marcin Eichner, Moin Nabi, Yinfei Yang, Joshua M. Susskind, Alaaeldin El-Nouby
分类: cs.CV, cs.LG
发布日期: 2024-11-21
备注: https://github.com/apple/ml-aim
💡 一句话要点
提出AIMV2:一种基于多模态自回归预训练的大规模视觉编码器,显著提升下游任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 自回归预训练 视觉编码器 图像文本联合建模 Transformer 大规模预训练
📋 核心要点
- 现有视觉模型预训练方法在多模态理解和泛化能力上存在不足,难以同时兼顾图像和文本信息。
- 提出AIMV2,通过多模态自回归预训练框架,联合建模图像块和文本token,提升视觉编码器的多模态理解能力。
- 实验表明,AIMV2在ImageNet-1k上达到89.5%的准确率,并在多模态图像理解任务中优于CLIP等对比学习模型。
📝 摘要(中文)
本文提出了一种用于大规模视觉编码器预训练的新方法。基于视觉模型自回归预训练的最新进展,我们将此框架扩展到多模态设置,即图像和文本。在本文中,我们提出了AIMV2,这是一系列通用视觉编码器,其特点是预训练过程简单、可扩展,并在各种下游任务中表现出色。这通过将视觉编码器与多模态解码器配对来实现,该解码器自回归地生成原始图像块和文本token。我们的编码器不仅在多模态评估中表现出色,而且在定位、grounding和分类等视觉基准测试中也表现出色。值得注意的是,我们的AIMV2-3B编码器在ImageNet-1k上实现了89.5%的冻结trunk准确率。此外,AIMV2在各种设置下的多模态图像理解方面始终优于最先进的对比模型(例如,CLIP,SigLIP)。
🔬 方法详解
问题定义:现有视觉编码器的预训练方法,如对比学习,在多模态理解和泛化能力上存在局限性。它们通常需要大量的图像-文本对,并且可能无法充分利用图像和文本之间的复杂关系。此外,如何设计一个能够同时处理图像和文本信息的通用视觉编码器仍然是一个挑战。
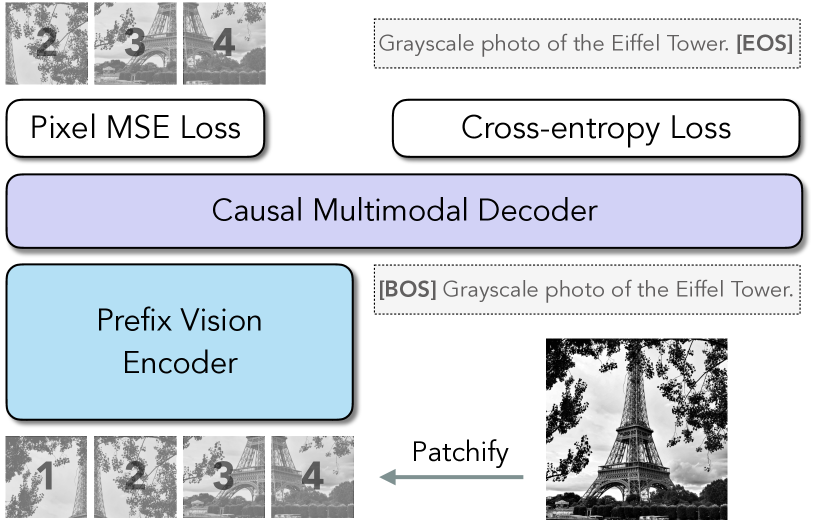
核心思路:本文的核心思路是利用多模态自回归预训练来学习图像和文本的联合表示。通过将视觉编码器与一个多模态解码器配对,该解码器能够自回归地生成原始图像块和文本token,从而迫使编码器学习到更丰富的、与上下文相关的特征表示。这种方法能够更好地捕捉图像和文本之间的依赖关系,并提高编码器的泛化能力。
技术框架:AIMV2的整体框架包括一个视觉编码器和一个多模态解码器。视觉编码器负责将输入图像转换为特征向量,多模态解码器则利用这些特征向量自回归地生成图像块和文本token。预训练阶段,模型通过最小化生成图像块和文本token的损失函数来学习参数。在下游任务中,可以直接使用预训练好的视觉编码器,或者进行微调。
关键创新:AIMV2的关键创新在于将自回归预训练扩展到多模态设置。与传统的对比学习方法不同,AIMV2不需要显式的图像-文本对,而是通过自回归生成的方式来学习图像和文本之间的关系。这种方法能够更好地捕捉图像和文本之间的复杂依赖关系,并提高模型的泛化能力。
关键设计:AIMV2的关键设计包括:1) 使用Transformer作为视觉编码器和多模态解码器的基本架构;2) 使用图像块作为视觉token,并将其与文本token一起输入到解码器中;3) 使用交叉熵损失函数来训练解码器生成图像块和文本token;4) 通过缩放模型大小(例如,AIMV2-3B)来提高性能。
🖼️ 关键图片
📊 实验亮点
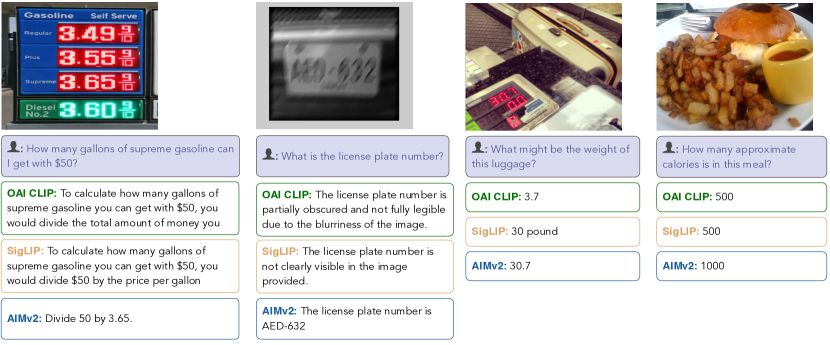
AIMV2-3B在ImageNet-1k上实现了89.5%的冻结trunk准确率,显著优于其他预训练模型。在多模态图像理解任务中,AIMV2在各种设置下始终优于最先进的对比模型(例如,CLIP,SigLIP)。这些结果表明,AIMV2在视觉和多模态任务中都具有强大的性能。
🎯 应用场景
AIMV2具有广泛的应用前景,包括图像分类、目标检测、图像描述、视觉问答等。其强大的多模态理解能力使其能够应用于智能客服、自动驾驶、机器人等领域,为机器赋予更强的感知和推理能力。未来,该方法有望进一步扩展到视频、语音等多模态数据的处理,实现更通用的人工智能系统。
📄 摘要(原文)
We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.