DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
作者: Tianhe Ren, Yihao Chen, Qing Jiang, Zhaoyang Zeng, Yuda Xiong, Wenlong Liu, Zhengyu Ma, Junyi Shen, Yuan Gao, Xiaoke Jiang, Xingyu Chen, Zhuheng Song, Yuhong Zhang, Hongjie Huang, Han Gao, Shilong Liu, Hao Zhang, Feng Li, Kent Yu, Lei Zhang
分类: cs.CV
发布日期: 2024-11-21 (更新: 2025-05-15)
备注: Technical Report
💡 一句话要点
DINO-X:用于开放世界目标检测与理解的统一视觉模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放世界目标检测 长尾目标检测 Transformer Grounding 多任务学习 零样本学习 目标提示
📋 核心要点
- 现有开放世界目标检测方法在处理长尾分布的目标时性能不佳,且通常需要用户提供额外的提示信息。
- DINO-X通过扩展输入选项,支持文本、视觉和自定义提示,并开发通用目标提示,实现无提示的开放世界目标检测。
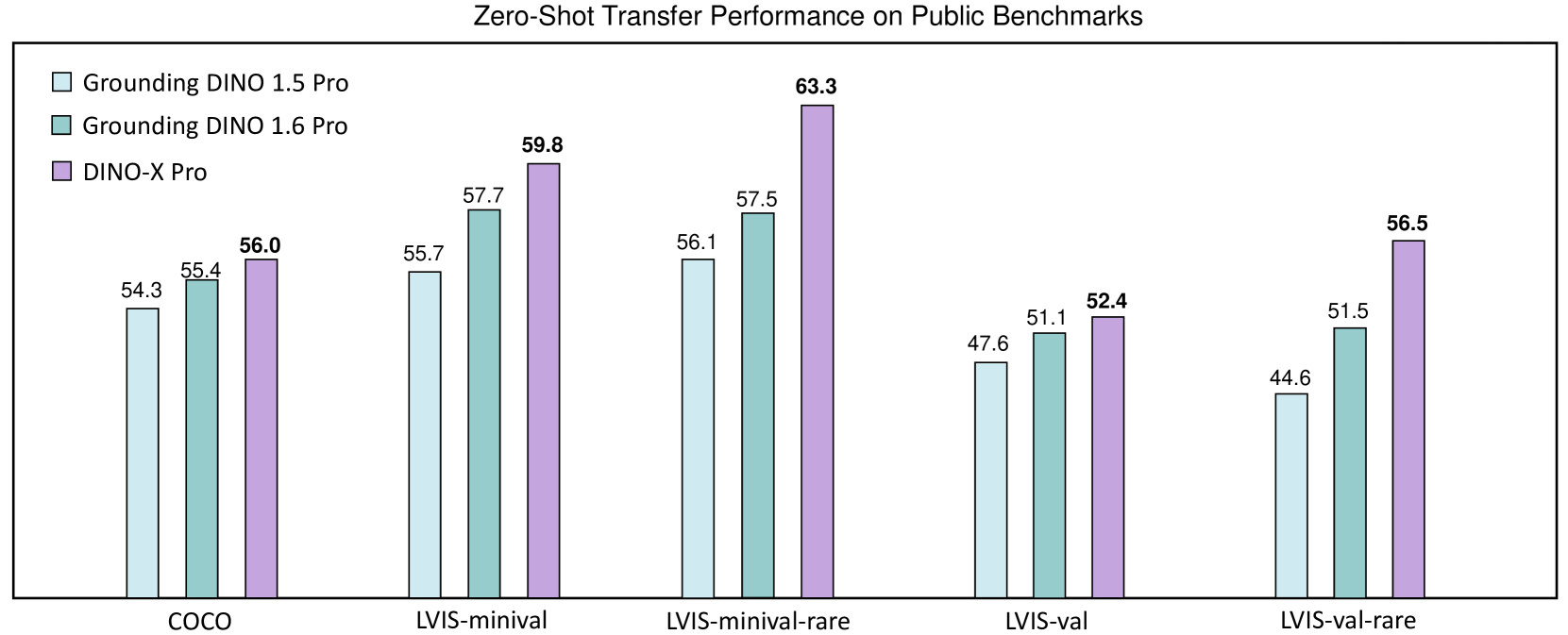
- DINO-X Pro在LVIS-minival和LVIS-val罕见类别上分别取得63.3 AP和56.5 AP,显著提升了长尾目标的识别能力。
📝 摘要(中文)
本文介绍了DINO-X,这是IDEA研究院开发的一个统一的、以目标为中心的视觉模型,它具有目前最佳的开放世界目标检测性能。DINO-X采用了与Grounding DINO 1.5相同的基于Transformer的编码器-解码器架构,以追求用于开放世界目标理解的目标级表示。为了简化长尾目标检测,DINO-X扩展了其输入选项,以支持文本提示、视觉提示和自定义提示。借助这种灵活的提示选项,我们开发了一种通用的目标提示,以支持无提示的开放世界检测,从而可以在不需要用户提供任何提示的情况下检测图像中的任何内容。为了增强模型的核心 grounding 能力,我们构建了一个包含超过 1 亿个高质量 grounding 样本的大规模数据集,称为 Grounding-100M,以提高模型的开放词汇检测性能。在这种大规模 grounding 数据集上进行预训练可以产生基础的目标级表示,这使得 DINO-X 能够集成多个感知头,以同时支持多个目标感知和理解任务,包括检测、分割、姿态估计、目标描述、基于目标的问答等。实验结果表明了 DINO-X 的卓越性能。具体来说,DINO-X Pro 模型在 COCO、LVIS-minival 和 LVIS-val 零样本目标检测基准测试中分别实现了 56.0 AP、59.8 AP 和 52.4 AP。值得注意的是,它在 LVIS-minival 和 LVIS-val 基准测试的罕见类别上分别获得了 63.3 AP 和 56.5 AP,比之前的 SOTA 性能提高了 5.8 AP 和 5.0 AP。这一结果突显了其在识别长尾目标方面的显著提升。
🔬 方法详解
问题定义:开放世界目标检测旨在检测图像中任何类别的物体,但现有方法在处理长尾分布的数据集时,对罕见类别的检测精度较低。此外,许多方法依赖于用户提供的文本或视觉提示,限制了其在实际应用中的灵活性。
核心思路:DINO-X的核心在于构建一个通用的、以目标为中心的视觉模型,该模型能够通过学习大规模的 grounding 数据,获得强大的目标表示能力。通过灵活的提示机制,模型可以适应不同的输入形式,并实现无提示的开放世界目标检测。
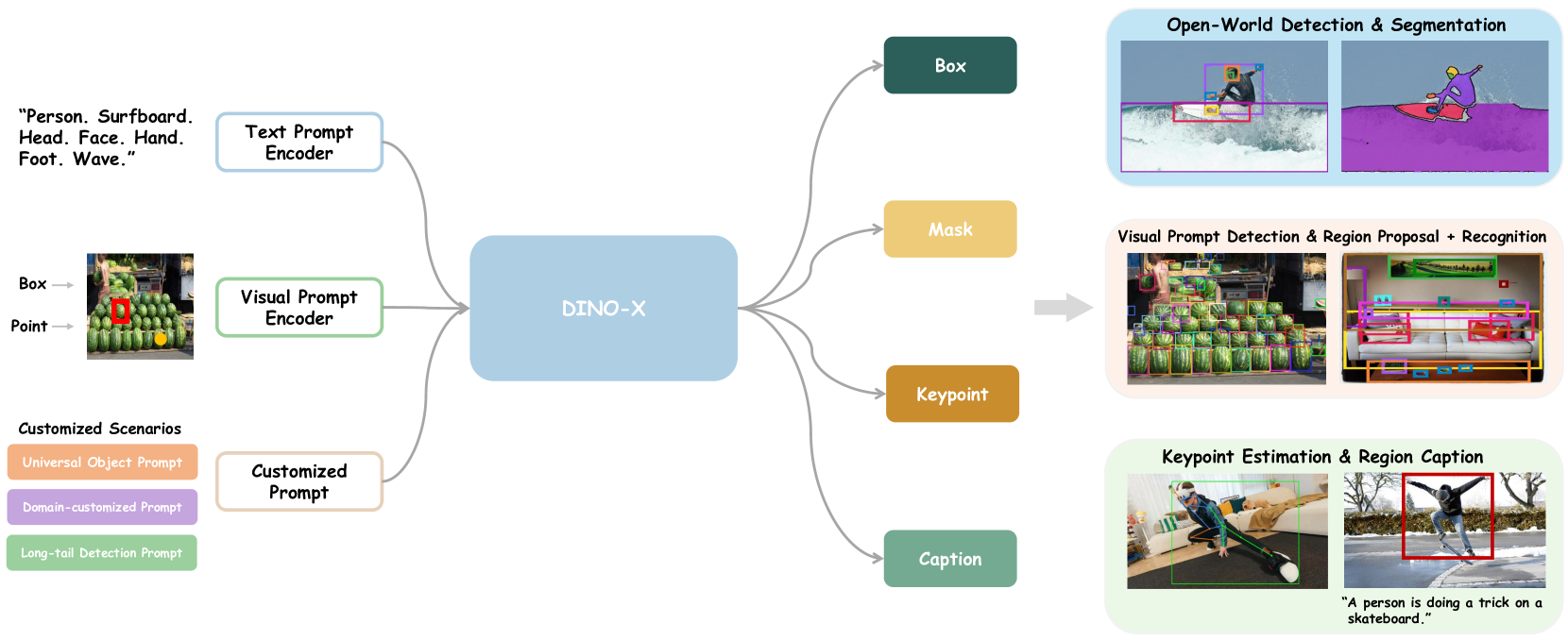
技术框架:DINO-X采用Transformer-based的编码器-解码器架构,与Grounding DINO 1.5类似。编码器负责提取图像特征,解码器则利用目标提示和图像特征进行目标检测。模型还集成了多个感知头,以支持检测、分割、姿态估计等多种任务。
关键创新:DINO-X的关键创新在于:1) 提出了通用的目标提示,实现了无提示的开放世界目标检测;2) 构建了大规模的Grounding-100M数据集,显著提升了模型的 grounding 能力和开放词汇检测性能;3) 通过集成多个感知头,实现了多任务学习,提高了模型的通用性。
关键设计:DINO-X的关键设计包括:1) 使用Transformer作为核心架构,以捕捉目标之间的关系;2) 设计了灵活的提示机制,支持文本、视觉和自定义提示;3) 构建了大规模的Grounding-100M数据集,用于预训练模型;4) 集成了多个感知头,以支持多任务学习。
🖼️ 关键图片

📊 实验亮点
DINO-X Pro模型在COCO数据集上实现了56.0 AP,在LVIS-minival和LVIS-val零样本目标检测基准测试中分别实现了59.8 AP和52.4 AP。尤其值得注意的是,在LVIS-minival和LVIS-val的罕见类别上,DINO-X Pro分别取得了63.3 AP和56.5 AP,相比之前的SOTA性能分别提升了5.8 AP和5.0 AP,显著提高了长尾目标的识别能力。
🎯 应用场景
DINO-X在智能安防、自动驾驶、机器人导航、图像搜索等领域具有广泛的应用前景。它可以用于检测和识别各种场景中的物体,例如行人、车辆、交通标志等,从而实现更智能化的监控、导航和交互。此外,DINO-X的多任务学习能力使其能够同时进行目标检测、分割和姿态估计,进一步提升了其在实际应用中的价值。
📄 摘要(原文)
In this paper, we introduce DINO-X, which is a unified object-centric vision model developed by IDEA Research with the best open-world object detection performance to date. DINO-X employs the same Transformer-based encoder-decoder architecture as Grounding DINO 1.5 to pursue an object-level representation for open-world object understanding. To make long-tailed object detection easy, DINO-X extends its input options to support text prompt, visual prompt, and customized prompt. With such flexible prompt options, we develop a universal object prompt to support prompt-free open-world detection, making it possible to detect anything in an image without requiring users to provide any prompt. To enhance the model's core grounding capability, we have constructed a large-scale dataset with over 100 million high-quality grounding samples, referred to as Grounding-100M, for advancing the model's open-vocabulary detection performance. Pre-training on such a large-scale grounding dataset leads to a foundational object-level representation, which enables DINO-X to integrate multiple perception heads to simultaneously support multiple object perception and understanding tasks, including detection, segmentation, pose estimation, object captioning, object-based QA, etc. Experimental results demonstrate the superior performance of DINO-X. Specifically, the DINO-X Pro model achieves 56.0 AP, 59.8 AP, and 52.4 AP on the COCO, LVIS-minival, and LVIS-val zero-shot object detection benchmarks, respectively. Notably, it scores 63.3 AP and 56.5 AP on the rare classes of LVIS-minival and LVIS-val benchmarks, improving the previous SOTA performance by 5.8 AP and 5.0 AP. Such a result underscores its significantly improved capacity for recognizing long-tailed objects.