VAGUE: Visual Contexts Clarify Ambiguous Expressions
作者: Heejeong Nam, Jinwoo Ahn, Keummin Ka, Jiwan Chung, Youngjae Yu
分类: cs.CV, cs.CL
发布日期: 2024-11-21 (更新: 2025-08-25)
备注: ICCV 2025, 32 pages
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VAGUE:利用视觉上下文消除歧义性表达,提升多模态推理能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 意图消歧 视觉上下文 歧义性表达 基准数据集 人机交互 视觉常识推理
📋 核心要点
- 现有AI系统在理解人类交流中的歧义性表达时,缺乏有效整合视觉上下文进行推理的能力。
- VAGUE基准通过提供歧义性文本表达和视觉上下文,旨在评估和提升AI系统在多模态意图消歧方面的能力。
- 实验结果表明,现有模型在VAGUE基准上表现不佳,表明模型在视觉推理和意图理解方面存在显著差距。
📝 摘要(中文)
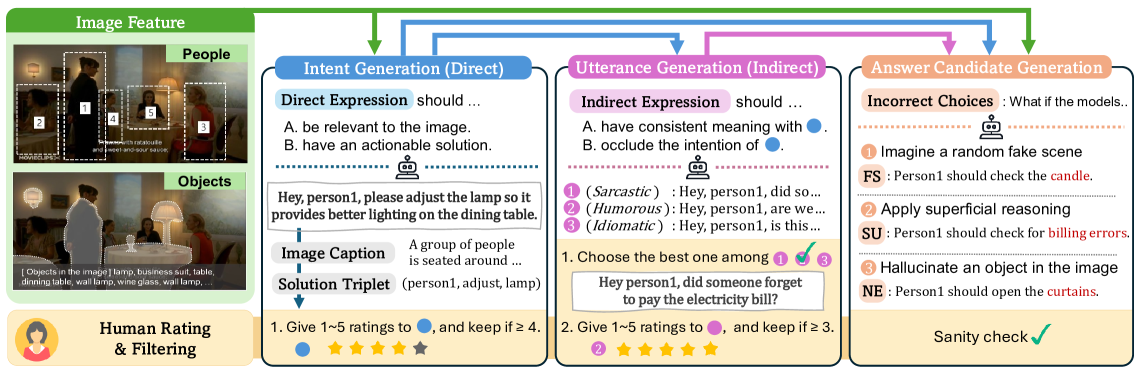
人类交流常依赖视觉线索来消除歧义。虽然人类可以直观地整合这些线索,但AI系统在进行复杂的多模态推理时面临挑战。本文提出了VAGUE,一个用于评估多模态AI系统整合视觉上下文以进行意图消歧的基准。VAGUE包含1.6K个歧义性文本表达,每个表达都配有一张图像和多个选项,只有结合视觉上下文才能确定正确答案。该数据集涵盖了精心设计的复杂场景(Visual Commonsense Reasoning)和自然的个人场景(Ego4D),确保了多样性。实验表明,现有的多模态AI模型难以推断说话者的真实意图。虽然引入更多视觉线索可以持续提高性能,但总体准确率远低于人类水平,突显了多模态推理方面的一个关键差距。对失败案例的分析表明,当前的模型无法区分真实意图和视觉场景中的表面相关性,表明它们感知图像但不能有效地进行推理。
🔬 方法详解
问题定义:论文旨在解决多模态AI系统在理解歧义性文本表达时,无法有效利用视觉上下文进行意图消歧的问题。现有方法通常难以区分真实意图和视觉场景中的表面相关性,导致推理错误。
核心思路:论文的核心思路是构建一个包含歧义性文本表达和对应视觉上下文的数据集,并利用该数据集评估和提升多模态AI系统在意图消歧方面的能力。通过提供丰富的视觉信息,促使模型学习如何将视觉线索与文本信息相结合,从而更准确地理解说话者的真实意图。
技术框架:VAGUE数据集包含1.6K个歧义性文本表达,每个表达都配有一张图像和多个选项。数据集涵盖了Visual Commonsense Reasoning和Ego4D两种场景,以保证多样性。研究人员可以使用该数据集训练和评估各种多模态AI模型,例如基于Transformer的模型。
关键创新:该论文的关键创新在于构建了一个专门用于评估多模态意图消歧能力的基准数据集VAGUE。该数据集的特点是包含歧义性文本表达和丰富的视觉上下文,能够有效测试模型在复杂场景下的推理能力。
关键设计:VAGUE数据集的设计考虑了歧义性文本表达的多样性和视觉上下文的相关性。数据集中的图像来自不同的场景,包括精心设计的复杂场景和自然的个人场景。选项的设计也经过精心考虑,以确保只有结合视觉上下文才能确定正确答案。此外,论文还分析了现有模型在VAGUE数据集上的失败案例,为未来的研究提供了方向。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有模型在VAGUE数据集上的表现远低于人类水平,突显了多模态推理方面的差距。引入更多视觉线索可以提高模型性能,但总体准确率仍然有限。对失败案例的分析表明,模型难以区分真实意图和视觉场景中的表面相关性。这些结果表明,需要进一步研究更有效的多模态推理方法。
🎯 应用场景
该研究成果可应用于智能对话系统、人机交互、机器人导航等领域。通过提升AI系统对歧义性表达的理解能力,可以改善用户体验,提高系统的可靠性和智能化水平。未来,该研究有望推动多模态人工智能技术的发展,促进更自然、更智能的人机交互。
📄 摘要(原文)
Human communication often relies on visual cues to resolve ambiguity. While humans can intuitively integrate these cues, AI systems often find it challenging to engage in sophisticated multimodal reasoning. We introduce VAGUE, a benchmark evaluating multimodal AI systems' ability to integrate visual context for intent disambiguation. VAGUE consists of 1.6K ambiguous textual expressions, each paired with an image and multiple-choice interpretations, where the correct answer is only apparent with visual context. The dataset spans both staged, complex (Visual Commonsense Reasoning) and natural, personal (Ego4D) scenes, ensuring diversity. Our experiments reveal that existing multimodal AI models struggle to infer the speaker's true intent. While performance consistently improves from the introduction of more visual cues, the overall accuracy remains far below human performance, highlighting a critical gap in multimodal reasoning. Analysis of failure cases demonstrates that current models fail to distinguish true intent from superficial correlations in the visual scene, indicating that they perceive images but do not effectively reason with them. We release our code and data at https://hazel-heejeong-nam.github.io/vague/.