Panther: Illuminate the Sight of Multimodal LLMs with Instruction-Guided Visual Prompts
作者: Honglin Li, Yuting Gao, Chenglu Zhu, Jingdong Chen, Ming Yang, Lin Yang
分类: cs.CV
发布日期: 2024-11-21 (更新: 2024-11-22)
💡 一句话要点
Panther:利用指令引导的视觉提示增强多模态LLM的视觉感知能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 指令引导 视觉提示 视觉编码 信息过滤 弱视问题
📋 核心要点
- 现有MLLM在处理细粒度视觉信息和精确定位小物体方面存在不足,缺乏对文本指令的有效利用。
- Panther通过在视觉编码器早期融入指令信息,提取更相关的视觉表征,并使用Bridge模块过滤冗余信息。
- 实验表明,Panther在视觉中心任务上表现出色,验证了其有效性,并具有良好的通用性。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉感知能力上正迅速缩小与人类的差距,但仍然在关注细微图像细节或精确定位小物体等方面存在不足。常见的解决方案包括部署多个视觉编码器或处理原始高分辨率图像。然而,很少有研究关注利用文本指令来改善视觉表征,导致在一些以视觉为中心的任务中失去焦点,我们称之为“弱视”现象。本文提出了Panther,一个MLLM,它能紧密遵循用户指令并精确定位感兴趣的目标,如同黑豹般敏锐。具体来说,Panther包含三个组成部分:Panther-VE、Panther-Bridge和Panther-Decoder。Panther-VE在视觉编码器的早期阶段整合用户指令信息,从而提取最相关和最有用的视觉表征。Panther-Bridge模块具有强大的过滤能力,可显著减少冗余视觉信息,从而大幅节省训练成本。Panther-Decoder具有通用性,可以与任何decoder-only架构的LLM一起使用。实验结果,特别是在以视觉为中心的基准测试中,证明了Panther的有效性。
🔬 方法详解
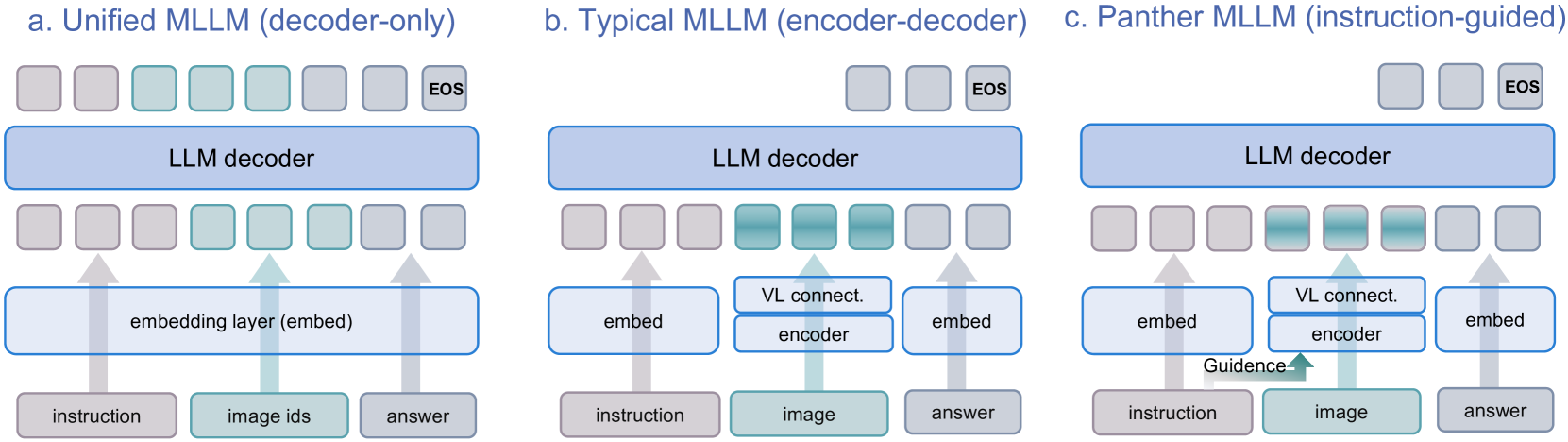
问题定义:现有的多模态大型语言模型在处理视觉任务时,尤其是在需要关注图像细节或精确定位小物体时,表现不佳。一个主要原因是视觉表征的提取没有充分利用文本指令的信息,导致模型在视觉任务中出现“弱视”现象,无法准确聚焦于与指令相关的视觉区域。
核心思路:Panther的核心思路是在视觉编码的早期阶段就融入文本指令的信息,从而引导视觉编码器提取与指令最相关的视觉特征。此外,通过一个Bridge模块来过滤掉冗余的视觉信息,减少计算负担,并提高模型的效率。
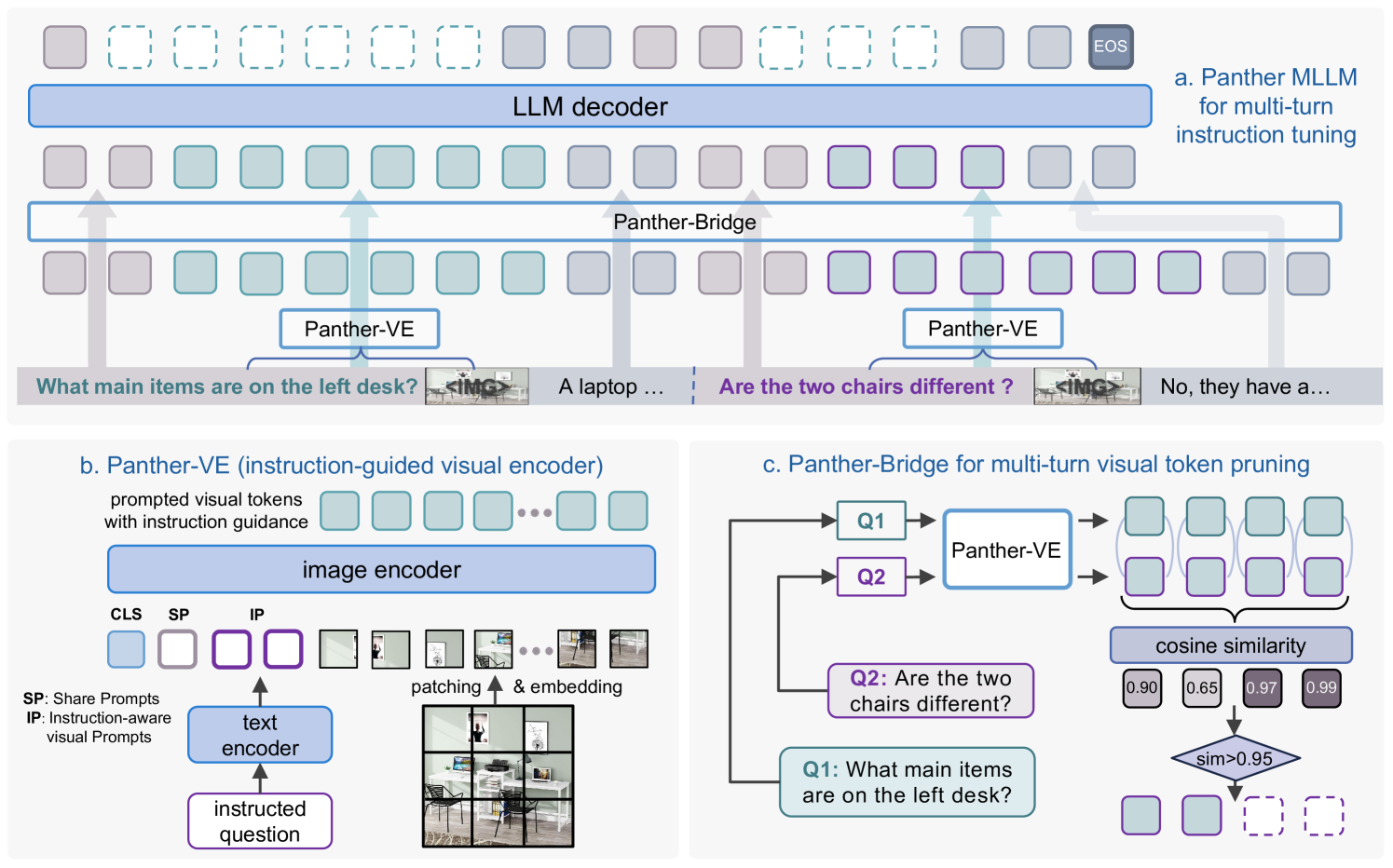
技术框架:Panther由三个主要模块组成:Panther-VE(视觉编码器)、Panther-Bridge和Panther-Decoder。Panther-VE负责将图像和文本指令编码成视觉特征;Panther-Bridge负责过滤冗余的视觉信息,提取关键特征;Panther-Decoder是一个通用的decoder-only LLM,用于生成最终的输出。整个流程是:首先,Panther-VE接收图像和文本指令,生成视觉特征;然后,Panther-Bridge对视觉特征进行过滤;最后,Panther-Decoder利用过滤后的视觉特征生成最终的文本输出。
关键创新:Panther的关键创新在于将文本指令信息融入到视觉编码的早期阶段。传统方法通常是在视觉编码之后才将文本信息与视觉特征进行融合,而Panther通过在视觉编码阶段就引入指令信息,可以更有效地引导视觉编码器提取与指令相关的特征,从而提高模型在视觉任务中的表现。
关键设计:Panther-VE的具体实现细节未知,但其核心思想是在视觉编码的早期阶段,通过某种方式(例如,注意力机制)将文本指令信息融入到视觉特征的提取过程中。Panther-Bridge的具体实现细节也未知,但其目标是过滤掉冗余的视觉信息,可能采用某种自注意力机制或卷积神经网络来实现。Panther-Decoder可以使用任何decoder-only架构的LLM,例如GPT系列的模型。
🖼️ 关键图片

📊 实验亮点
论文在多个视觉中心基准测试中验证了Panther的有效性,但具体的性能数据和提升幅度未知。Panther的设计具有通用性,可以与不同的decoder-only LLM结合使用,这使得Panther具有很强的灵活性和可扩展性。Panther-Bridge模块可以有效减少冗余视觉信息,从而降低训练成本,提高模型效率。
🎯 应用场景
Panther具有广泛的应用前景,例如在智能问答、图像描述、视觉定位、机器人导航等领域。通过更准确地理解用户指令并聚焦于图像中的关键区域,Panther可以提升这些应用的用户体验和性能。未来,Panther可以进一步扩展到更多模态,例如音频和视频,从而实现更强大的多模态理解能力。
📄 摘要(原文)
Multimodal large language models (MLLMs) are closing the gap to human visual perception capability rapidly, while, still lag behind on attending to subtle images details or locating small objects precisely, etc. Common schemes to tackle these issues include deploying multiple vision encoders or operating on original high-resolution images. Few studies have concentrated on taking the textual instruction into improving visual representation, resulting in losing focus in some vision-centric tasks, a phenomenon we herein termed as Amblyopia. In this work, we introduce Panther, a MLLM that closely adheres to user instruction and locates targets of interests precisely, with the finesse of a black panther. Specifically, Panther comprises three integral components: Panther-VE, Panther-Bridge, and Panther-Decoder. Panther-VE integrates user instruction information at the early stages of the vision encoder, thereby extracting the most relevant and useful visual representations. The Panther-Bridge module, equipped with powerful filtering capabilities, significantly reduces redundant visual information, leading to a substantial savings in training costs. The Panther-Decoder is versatile and can be employed with any decoder-only architecture of LLMs without discrimination. Experimental results, particularly on vision-centric benchmarks, have demonstrated the effectiveness of Panther.