Hints of Prompt: Enhancing Visual Representation for Multimodal LLMs in Autonomous Driving
作者: Hao Zhou, Zhanning Gao, Zhili Chen, Maosheng Ye, Qifeng Chen, Tongyi Cao, Honggang Qi
分类: cs.CV
发布日期: 2024-11-20 (更新: 2025-10-15)
💡 一句话要点
提出Hints of Prompt (HoP)框架,增强多模态LLM在自动驾驶场景中的视觉表征能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 多模态LLM 视觉表征 提示学习 场景理解
📋 核心要点
- 通用多模态LLM在自动驾驶场景中,尤其在复杂交互和长尾案例中,视觉表征能力不足,难以满足安全需求。
- HoP框架通过引入亲和、语义和问题三种提示,并进行融合,从而增强视觉表征,提升模型对驾驶场景的理解。
- 实验结果表明,HoP框架在关键指标上显著优于现有方法,证明了其在自动驾驶场景中的有效性。
📝 摘要(中文)
针对通用多模态LLM结合CLIP在动态自动驾驶环境中,难以准确表征驾驶场景,尤其是在复杂交互和长尾案例中的问题,本文提出了Hints of Prompt (HoP)框架。该框架引入了三个关键增强:亲和提示(Affinity hint)通过加强token间的连接来强调实例级别的结构;语义提示(Semantic hint)整合与驾驶相关的场景信息,例如车辆间的复杂交互和交通标志;问题提示(Question hint)将视觉特征与查询上下文对齐,聚焦于与问题相关的区域。这些提示通过提示融合模块进行融合,通过捕获与驾驶相关的表征来丰富视觉表征,确保更快地适应驾驶场景。大量实验证实了HoP框架的有效性,表明其在所有关键指标上均显著优于先前的state-of-the-art方法。
🔬 方法详解
问题定义:论文旨在解决通用多模态LLM在自动驾驶场景中,视觉表征能力不足的问题。现有方法,如直接使用CLIP,难以捕捉驾驶场景中复杂的交互关系和长尾案例,导致模型在理解和推理方面存在局限性。
核心思路:论文的核心思路是通过引入多种提示信息(Hints of Prompt)来增强视觉表征。这些提示信息分别从不同的角度补充了原始视觉特征的不足,包括实例结构、语义信息和问题相关性。通过融合这些提示信息,模型可以更全面、准确地理解驾驶场景。
技术框架:HoP框架主要包含三个关键模块:Affinity hint模块、Semantic hint模块和Question hint模块。Affinity hint模块通过加强token间的连接来强调实例级别的结构;Semantic hint模块整合与驾驶相关的场景信息;Question hint模块将视觉特征与查询上下文对齐。这三个模块的输出随后被送入Hint Fusion模块进行融合,最终得到增强的视觉表征。
关键创新:HoP框架的关键创新在于提出了三种不同类型的提示信息,并设计了相应的模块来提取和融合这些提示信息。与现有方法相比,HoP框架能够更有效地利用有限的领域数据,从而更快地适应驾驶场景。此外,Hint Fusion模块的设计也至关重要,它能够有效地将不同类型的提示信息融合在一起,从而得到更全面的视觉表征。
关键设计:具体的技术细节包括:Affinity hint模块可能使用了图神经网络或注意力机制来建模token间的关系;Semantic hint模块可能使用了预训练的语言模型或知识图谱来获取驾驶相关的语义信息;Question hint模块可能使用了交叉注意力机制来对齐视觉特征和查询上下文。Hint Fusion模块的具体实现方式未知,但可能使用了加权融合或注意力机制。
🖼️ 关键图片
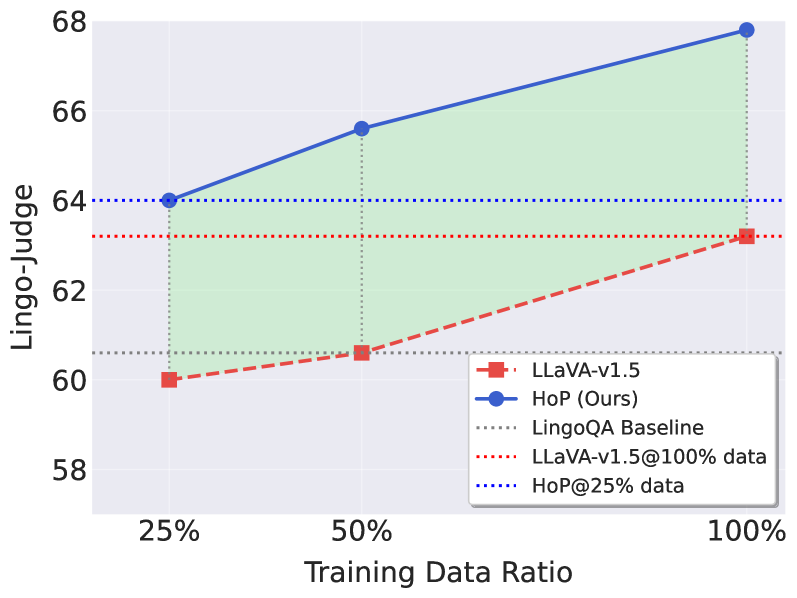


📊 实验亮点
论文通过大量实验验证了HoP框架的有效性,实验结果表明,HoP框架在所有关键指标上均显著优于先前的state-of-the-art方法。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了HoP框架在增强多模态LLM在自动驾驶场景中的视觉表征能力方面的优越性。
🎯 应用场景
该研究成果可应用于自动驾驶系统的感知模块,提升其对复杂驾驶场景的理解和推理能力,从而提高自动驾驶的安全性。此外,该方法也可以推广到其他需要细粒度视觉理解的场景,例如机器人导航、智能监控等。未来,该研究有望推动自动驾驶技术的进一步发展,加速其商业化落地。
📄 摘要(原文)
In light of the dynamic nature of autonomous driving environments and stringent safety requirements, general MLLMs combined with CLIP alone often struggle to accurately represent driving-specific scenarios, particularly in complex interactions and long-tail cases. To address this, we propose the Hints of Prompt (HoP) framework, which introduces three key enhancements: Affinity hint to emphasize instance-level structure by strengthening token-wise connections, Semantic hint to incorporate high-level information relevant to driving-specific cases, such as complex interactions among vehicles and traffic signs, and Question hint to align visual features with the query context, focusing on question-relevant regions. These hints are fused through a Hint Fusion module, enriching visual representations by capturing driving-related representations with limited domain data, ensuring faster adaptation to driving scenarios. Extensive experiments confirm the effectiveness of the HoP framework, showing that it significantly outperforms previous state-of-the-art methods in all key metrics.