MEGL: Multimodal Explanation-Guided Learning
作者: Yifei Zhang, Tianxu Jiang, Bo Pan, Jingyu Wang, Guangji Bai, Liang Zhao
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-11-20
💡 一句话要点
提出MEGL:一种多模态解释引导学习框架,提升图像分类模型的可解释性和性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 可解释AI 图像分类 视觉解释 文本解释 解释引导学习 显著性图 文本 grounding
📋 核心要点
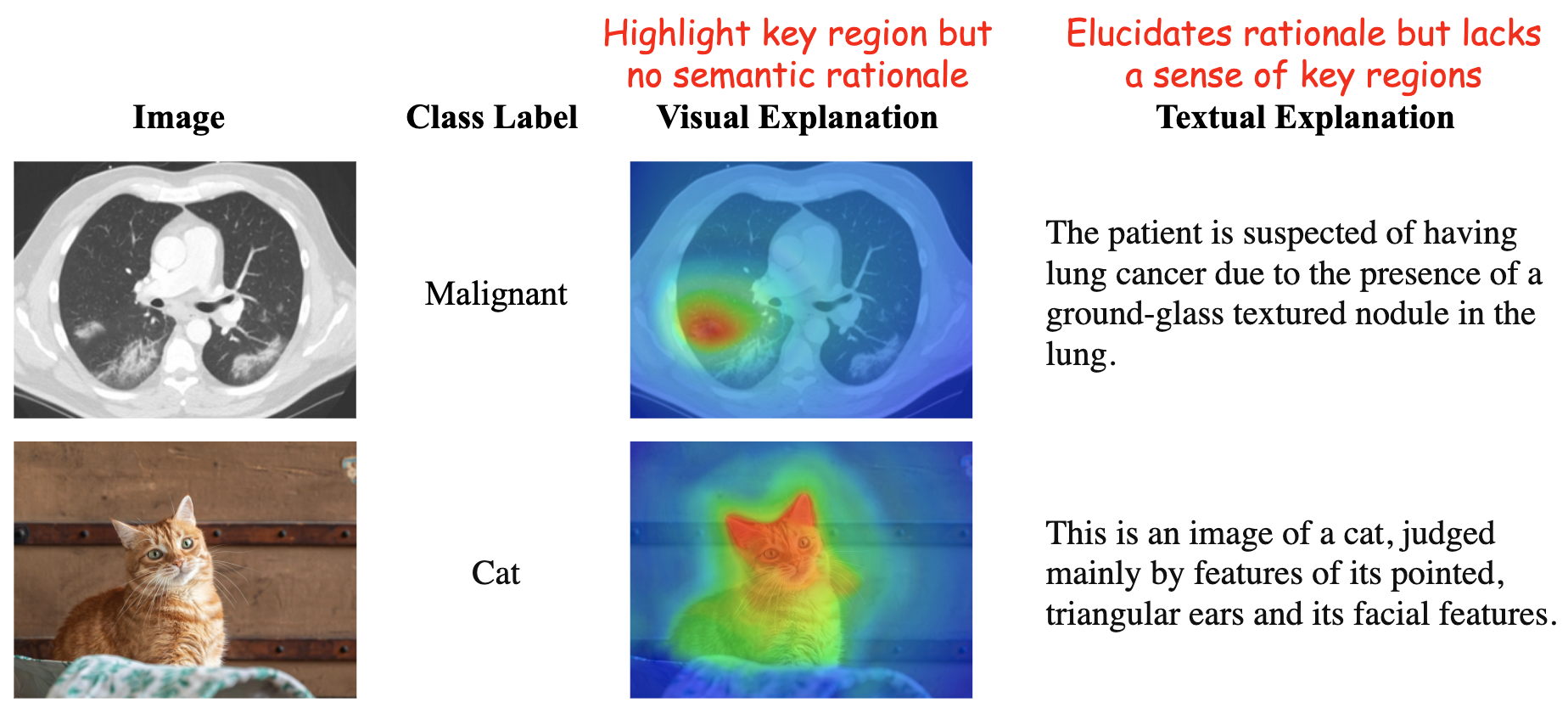
- 传统可解释AI方法依赖单一模态解释,视觉解释缺乏推理,文本解释缺乏空间定位,且两者可能不一致或不完整。
- MEGL框架利用视觉和文本解释,通过显著性驱动的文本grounding和视觉解释的文本监督,实现空间定位和上下文丰富的解释。
- 在Object-ME和Action-ME数据集上的实验表明,MEGL在预测准确性和解释质量方面优于现有方法。
📝 摘要(中文)
为了解决人工智能模型决策过程的“黑盒”问题,尤其是在图像分类任务中,本文提出了一种新颖的多模态解释引导学习(MEGL)框架。该框架利用视觉和文本解释来增强模型的可解释性并提高分类性能。我们提出了显著性驱动的文本 grounding(SDTG)方法,将视觉解释中的空间信息整合到文本理由中,提供空间定位和上下文丰富的解释。此外,我们引入了视觉解释的文本监督,即使在缺少ground truth视觉标注的情况下,也能使视觉解释与文本理由对齐。视觉解释分布一致性损失通过将生成的视觉解释与数据集级别的模式对齐,进一步加强了视觉连贯性,使模型能够有效地从不完整的多模态监督中学习。我们在两个新的数据集Object-ME和Action-ME上验证了MEGL,实验结果表明,MEGL在预测准确性和视觉和文本领域的解释质量方面均优于以前的方法。
🔬 方法详解
问题定义:现有可解释AI方法(XAI)在图像分类任务中存在局限性。视觉解释(如显著性图)虽然能突出关键区域,但缺乏推理依据;文本解释虽然提供上下文,但缺乏空间定位。此外,视觉和文本解释之间可能存在不一致性,导致模型学习到的解释不准确或不完整。因此,如何有效融合视觉和文本解释,提升模型的可解释性和分类性能,是一个亟待解决的问题。
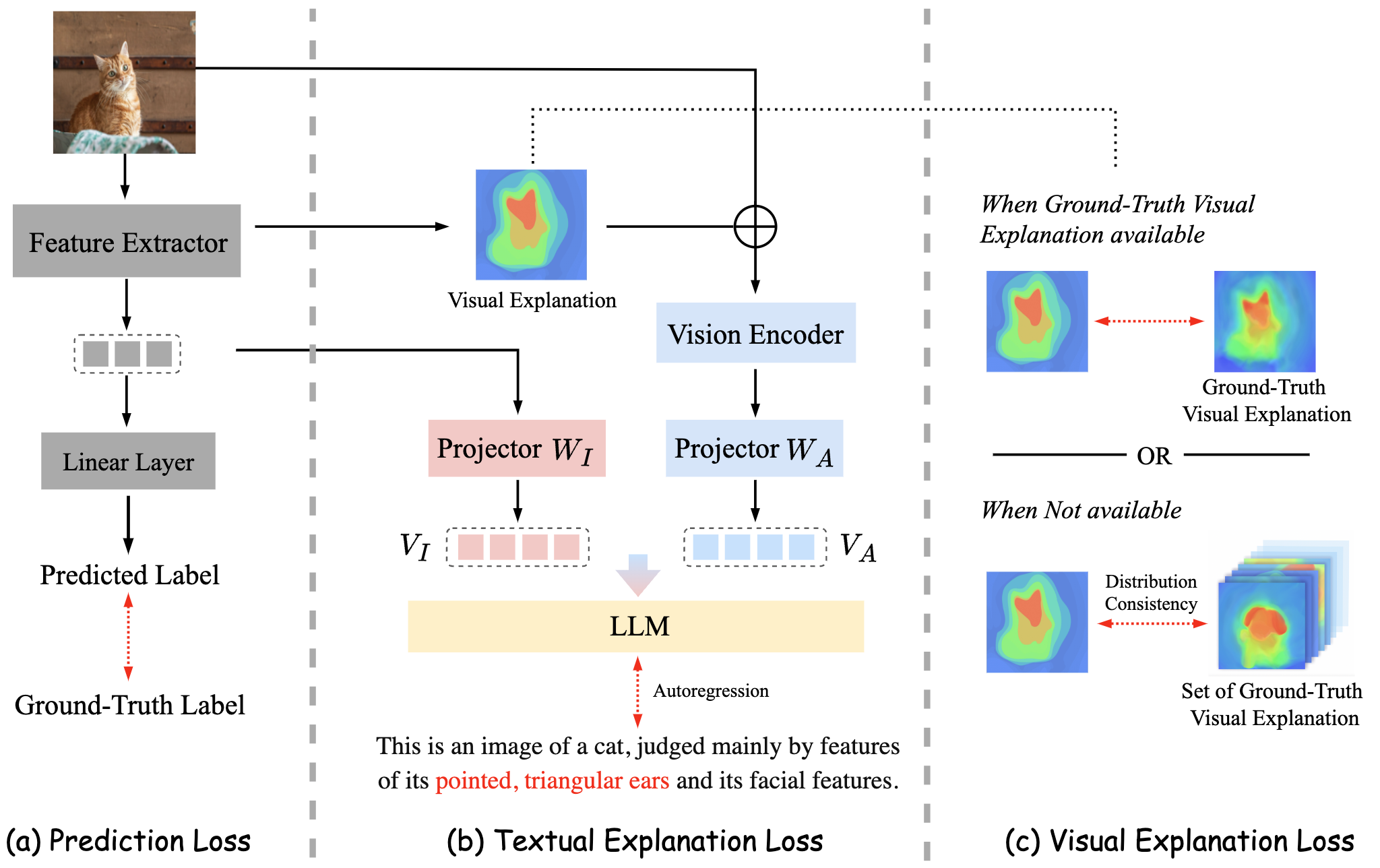
核心思路:MEGL的核心思路是利用多模态解释相互补充,克服单模态解释的局限性。通过将视觉解释的空间信息融入文本解释,实现空间定位的文本理由;同时,利用文本解释监督视觉解释,即使在缺少ground truth的情况下,也能保证视觉解释的准确性。此外,通过视觉解释分布一致性损失,保证生成视觉解释的全局一致性。
技术框架:MEGL框架主要包含三个模块:Saliency-Driven Textual Grounding (SDTG)、Textual Supervision on Visual Explanations和Visual Explanation Distribution Consistency loss。SDTG模块将视觉显著性图的空间信息融入文本解释中,生成空间定位的文本理由。Textual Supervision on Visual Explanations模块利用文本解释监督视觉解释的生成,即使在缺少ground truth视觉标注的情况下,也能保证视觉解释的准确性。Visual Explanation Distribution Consistency loss模块通过对齐生成的视觉解释与数据集级别的模式,加强视觉解释的全局一致性。整体流程是,输入图像经过分类模型得到预测结果,同时生成视觉解释和文本解释,然后通过上述三个模块进行融合和优化,最终提升模型的可解释性和分类性能。
关键创新:MEGL的关键创新在于多模态解释的融合方式。传统的XAI方法通常独立处理视觉和文本解释,而MEGL通过SDTG和Textual Supervision on Visual Explanations,实现了视觉和文本解释的深度融合,使得两种模态的解释能够相互促进,共同提升模型的可解释性和性能。此外,Visual Explanation Distribution Consistency loss的引入,保证了生成视觉解释的全局一致性,进一步提升了模型的可解释性。
关键设计:SDTG模块的具体实现方式未知,论文中没有详细描述。Textual Supervision on Visual Explanations模块可能使用了对比学习或相似性度量等方法,使得生成的视觉解释与文本解释在语义空间中对齐。Visual Explanation Distribution Consistency loss的具体形式未知,但其目标是使得生成的视觉解释的分布与数据集级别的视觉解释分布尽可能接近。这些模块的具体参数设置和网络结构需要在论文的后续版本或代码中进一步确认。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MEGL在Object-ME和Action-ME两个数据集上均取得了显著的性能提升。在预测准确性方面,MEGL优于现有的图像分类模型。在解释质量方面,MEGL生成的视觉和文本解释更加准确和一致,能够更好地反映模型的决策过程。具体的性能数据和提升幅度需要在论文中进一步查看。
🎯 应用场景
MEGL框架可应用于医疗诊断、自动驾驶、金融风控等需要高可解释性的图像分类任务中。例如,在医疗诊断中,MEGL可以提供疾病诊断的视觉和文本解释,帮助医生更好地理解模型的决策过程,从而提高诊断的准确性和可靠性。在自动驾驶中,MEGL可以解释车辆的驾驶行为,提高驾驶安全性和用户信任度。该研究有助于提升AI系统的透明度和可信度,促进AI技术在各个领域的广泛应用。
📄 摘要(原文)
Explaining the decision-making processes of Artificial Intelligence (AI) models is crucial for addressing their "black box" nature, particularly in tasks like image classification. Traditional eXplainable AI (XAI) methods typically rely on unimodal explanations, either visual or textual, each with inherent limitations. Visual explanations highlight key regions but often lack rationale, while textual explanations provide context without spatial grounding. Further, both explanation types can be inconsistent or incomplete, limiting their reliability. To address these challenges, we propose a novel Multimodal Explanation-Guided Learning (MEGL) framework that leverages both visual and textual explanations to enhance model interpretability and improve classification performance. Our Saliency-Driven Textual Grounding (SDTG) approach integrates spatial information from visual explanations into textual rationales, providing spatially grounded and contextually rich explanations. Additionally, we introduce Textual Supervision on Visual Explanations to align visual explanations with textual rationales, even in cases where ground truth visual annotations are missing. A Visual Explanation Distribution Consistency loss further reinforces visual coherence by aligning the generated visual explanations with dataset-level patterns, enabling the model to effectively learn from incomplete multimodal supervision. We validate MEGL on two new datasets, Object-ME and Action-ME, for image classification with multimodal explanations. Experimental results demonstrate that MEGL outperforms previous approaches in prediction accuracy and explanation quality across both visual and textual domains. Our code will be made available upon the acceptance of the paper.