RobustFormer: Noise-Robust Pre-training for images and videos
作者: Ashish Bastola, Nishant Luitel, Hao Wang, Danda Pani Paudel, Roshani Poudel, Abolfazl Razi
分类: cs.CV
发布日期: 2024-11-20 (更新: 2026-01-09)
备注: 13 pages
💡 一句话要点
RobustFormer:一种噪声鲁棒的图像和视频预训练方法,利用DWT提升Transformer在噪声环境下的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 噪声鲁棒性 离散小波变换 掩码自编码器 图像预训练 视频预训练 Transformer 多分辨率分析
📋 核心要点
- 现有Transformer模型对噪声敏感,易过拟合噪声,尤其在视觉任务中,像素级噪声干扰严重。
- RobustFormer利用DWT分解图像,将噪声隔离在高频部分,保留低频信息,实现噪声鲁棒的特征学习。
- 实验表明,RobustFormer在噪声数据集上显著提升分类准确率,同时降低了计算复杂度,且兼容视频输入。
📝 摘要(中文)
深度学习模型,如Transformer,在时间序列和视觉任务中取得了显著进展,但它们对噪声非常敏感,并且容易过度拟合噪声模式而非鲁棒特征。视觉Transformer尤其如此,因为它们依赖于容易被破坏的像素级细节。为了解决这个问题,本文利用离散小波变换(DWT)将图像分解为多分辨率层,将噪声主要隔离在高频域,同时保留重要的低频信息以进行鲁棒的特征学习。然而,传统的基于DWT的方法由于需要后续的逆离散小波变换(IDWT)步骤而存在计算效率低下的问题。本文提出了RobustFormer,一种新颖的框架,通过使用DWT进行高效下采样,无需昂贵的IDWT重建,并简化注意力机制以专注于噪声鲁棒的多尺度表示,从而实现图像和视频的噪声鲁棒掩码自编码器(MAE)预训练。据我们所知,RobustFormer是第一个完全兼容视频输入和MAE风格预训练的基于DWT的方法。在噪声图像和视频数据集上的大量实验表明,与基线相比,我们的方法在Imagenet-C的严重噪声条件下实现了高达8%的Top-1分类准确率提升,在Imagenet-P标准基准测试中实现了高达2.7%的提升,在严重自定义噪声扰动下的UCF-101上实现了高达13%的Top-1准确率提升,同时保持了清洁数据集上相似的准确率。我们还观察到,与VideoMAE基线相比,通过去除IDWT,计算复杂度降低了高达4.4%,而没有任何性能下降。
🔬 方法详解
问题定义:现有基于Transformer的图像和视频处理模型在噪声环境下表现不佳,容易受到噪声干扰而降低性能。特别是视觉Transformer,由于其对像素级细节的依赖,更容易受到噪声的影响。传统的去噪方法往往计算复杂度高,难以直接应用于大规模的预训练任务。
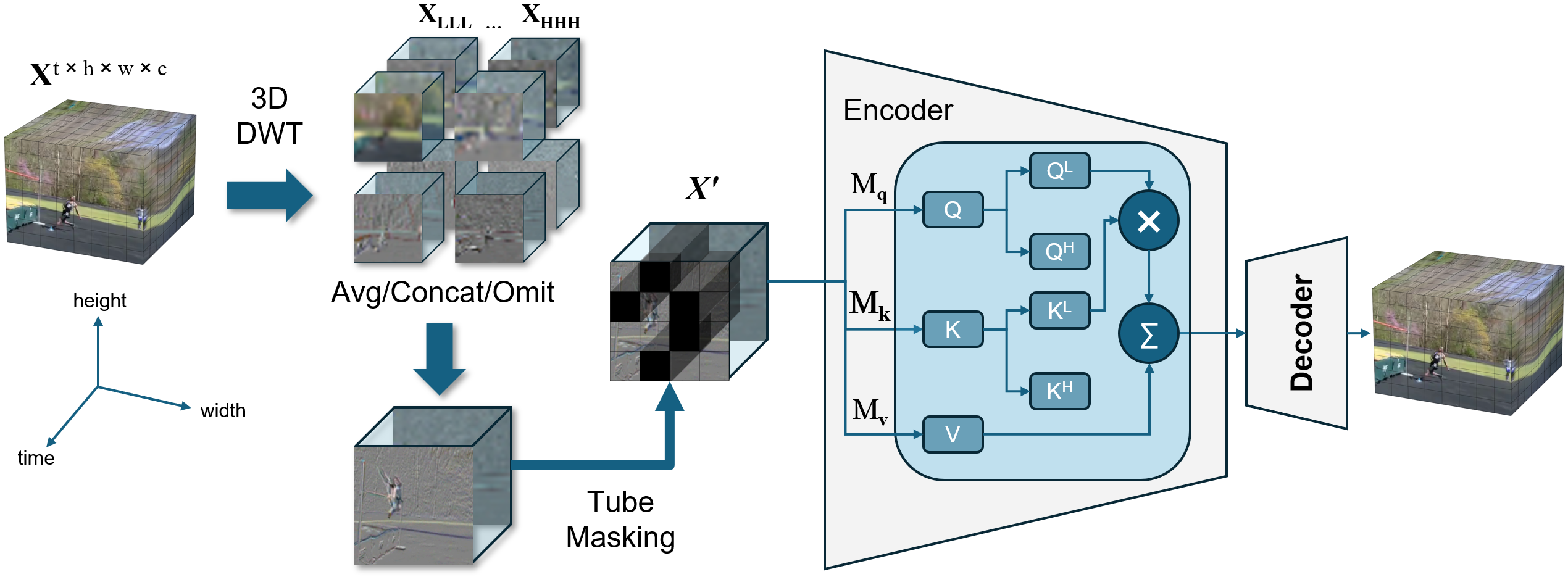
核心思路:RobustFormer的核心思路是利用离散小波变换(DWT)将图像或视频帧分解为多分辨率的子带,将噪声主要集中在高频子带中,而低频子带则包含图像或视频的主要结构信息。通过在低频子带上进行特征学习,可以有效地减少噪声的影响,提高模型的鲁棒性。同时,通过去除逆离散小波变换(IDWT)步骤,降低计算复杂度。
技术框架:RobustFormer的整体框架包括以下几个主要步骤:1) 输入图像或视频帧;2) 使用DWT进行多分辨率分解;3) 对低频子带进行掩码(Masked Autoencoder, MAE);4) 使用Transformer编码器对掩码后的低频子带进行编码;5) 使用Transformer解码器重建被掩码的部分;6) 计算重建损失,优化模型参数。该框架的关键在于使用DWT进行高效的下采样,并去除IDWT步骤,从而降低计算复杂度。
关键创新:RobustFormer的关键创新在于将DWT与MAE风格的预训练相结合,并针对视频数据进行了优化。与传统的DWT方法不同,RobustFormer不需要进行IDWT重建,从而显著降低了计算复杂度。此外,RobustFormer是第一个完全兼容视频输入和MAE风格预训练的基于DWT的方法。
关键设计:RobustFormer的关键设计包括:1) 使用Haar小波进行DWT分解;2) 对低频子带进行随机掩码,掩码比例为0.75;3) 使用标准的Transformer编码器和解码器;4) 使用均方误差(MSE)作为重建损失函数;5) 在大规模的图像和视频数据集上进行预训练,然后将预训练的模型迁移到下游任务中。
🖼️ 关键图片
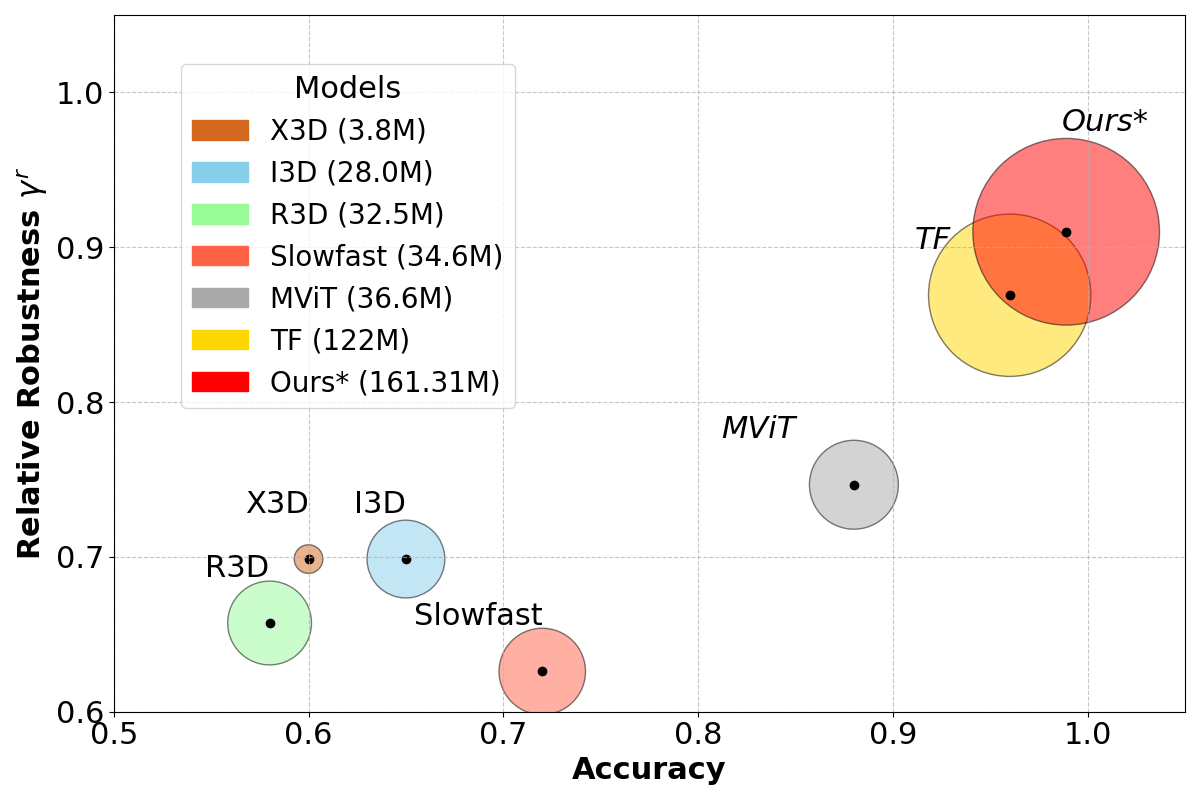

📊 实验亮点
RobustFormer在ImageNet-C数据集上,与基线相比,Top-1分类准确率提升高达8%。在ImageNet-P数据集上,Top-1准确率提升高达2.7%。在UCF-101数据集上,在严重自定义噪声扰动下,Top-1准确率提升高达13%。同时,与VideoMAE基线相比,计算复杂度降低了高达4.4%,而没有任何性能下降。这些结果表明,RobustFormer在噪声鲁棒性和计算效率方面都具有显著的优势。
🎯 应用场景
RobustFormer在噪声环境下的图像和视频处理中具有广泛的应用前景,例如在自动驾驶、医学影像分析、视频监控等领域。该方法可以提高模型在恶劣条件下的鲁棒性,从而提高系统的可靠性和安全性。此外,RobustFormer还可以应用于数据增强,通过对图像或视频添加噪声,然后使用RobustFormer进行去噪,从而生成更多样化的训练数据。
📄 摘要(原文)
While deep learning-based models like transformers, have revolutionized time-series and vision tasks, they remain highly susceptible to noise and often overfit on noisy patterns rather than robust features. This issue is exacerbated in vision transformers, which rely on pixel-level details that can easily be corrupt. To address this, we leverage the discrete wavelet transform (DWT) for its ability to decompose into multi-resolution layers, isolating noise primarily in the high frequency domain while preserving essential low-frequency information for resilient feature learning. Conventional DWT-based methods, however, struggle with computational inefficiencies due to the requirement for a subsequent inverse discrete wavelet transform (IDWT) step. In this work, we introduce RobustFormer, a novel framework that enables noise-robust masked autoencoder (MAE) pre-training for both images and videos by using DWT for efficient downsampling, eliminating the need for expensive IDWT reconstruction and simplifying the attention mechanism to focus on noise-resilient multi-scale representations. To our knowledge, RobustFormer is the first DWT-based method fully compatible with video inputs and MAE-style pre-training. Extensive experiments on noisy image and video datasets demonstrate that our approach achieves up to 8% increase in Top-1 classification accuracy under severe noise conditions in Imagenet-C and up to 2.7% in Imagenet-P standard benchmarks compared to the baseline and up to 13% higher Top-1 accuracy on UCF-101 under severe custom noise perturbations while maintaining similar accuracy scores for clean datasets. We also observe the reduction of computation complexity by up to 4.4% through IDWT removal compared to VideoMAE baseline without any performance drop.