Med-2E3: A 2D-Enhanced 3D Medical Multimodal Large Language Model
作者: Yiming Shi, Xun Zhu, Kaiwen Wang, Ying Hu, Chenyi Guo, Miao Li, Ji Wu
分类: cs.CV
发布日期: 2024-11-19 (更新: 2025-10-21)
🔗 代码/项目: GITHUB
💡 一句话要点
Med-2E3:一种2D增强的3D医学多模态大语言模型,提升3D医学图像分析性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像分析 多模态大语言模型 3D图像处理 2D图像处理 注意力机制 深度学习 医学影像
📋 核心要点
- 传统3D医学图像分析模型泛化性不足,难以应对多样临床场景,限制了其应用。
- Med-2E3通过双3D-2D编码器架构,同时利用3D空间结构和2D平面信息,更贴合医生诊断习惯。
- 实验表明,提出的文本引导切片间评分模块(TG-IS)能有效提升模型性能,优于现有SOTA模型。
📝 摘要(中文)
3D医学图像分析对现代医疗至关重要,但传统任务特定模型因在不同临床场景中的泛化能力有限而不足。多模态大语言模型(MLLM)为这些挑战提供了一个有希望的解决方案。然而,现有的MLLM在充分利用3D医学图像中丰富的分层信息方面存在局限性。受临床实践的启发,放射科医生既关注3D空间结构又关注2D平面内容,我们提出了Med-2E3,一种集成了双3D-2D编码器架构的3D医学MLLM。为了有效地聚合2D特征,我们设计了一个文本引导的切片间(TG-IS)评分模块,该模块基于切片内容和任务指令对每个2D切片的注意力进行评分。据我们所知,Med-2E3是第一个集成3D和2D特征用于3D医学图像分析的MLLM。在大型开源3D医学多模态数据集上的实验表明,TG-IS表现出任务特定的注意力分布,并且显著优于当前最先进的模型。代码可在https://github.com/MSIIP/Med-2E3 获取。
🔬 方法详解
问题定义:现有3D医学图像分析模型难以充分利用3D图像中蕴含的丰富分层信息,泛化能力不足,无法很好地适应各种临床场景。传统方法通常是任务特定的,需要针对不同的疾病或模态进行专门设计,成本高昂且效率低下。
核心思路:受到放射科医生在临床实践中同时关注3D空间结构和2D平面内容的启发,论文的核心思路是构建一个能够同时处理3D和2D信息的MLLM。通过融合3D全局信息和2D局部细节,模型可以更全面地理解医学图像,从而提高分析的准确性和泛化性。
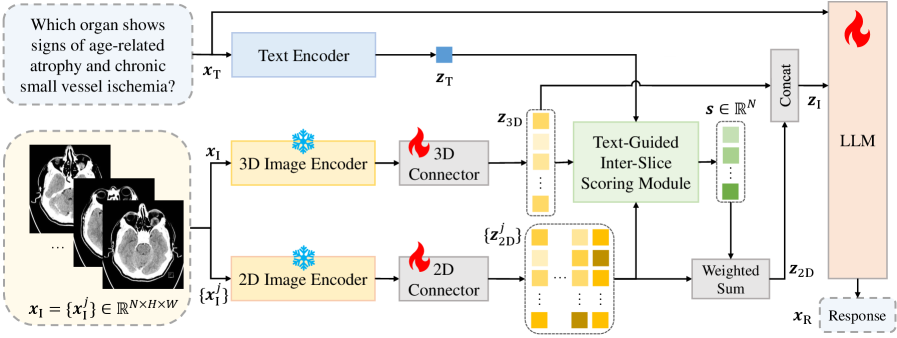
技术框架:Med-2E3采用双编码器架构,包括一个3D编码器和一个2D编码器。3D编码器用于提取图像的全局空间特征,2D编码器用于提取每个切片的局部细节特征。为了有效融合2D特征,引入了文本引导的切片间(TG-IS)评分模块。该模块根据切片内容和任务指令,为每个2D切片分配一个注意力权重,从而实现对重要切片的重点关注。最终,融合后的特征被输入到大语言模型中,用于完成各种医学图像分析任务。
关键创新:Med-2E3的关键创新在于同时利用3D和2D信息进行医学图像分析,并提出了文本引导的切片间评分模块(TG-IS)。这是第一个将3D和2D特征集成到MLLM中用于3D医学图像分析的工作。TG-IS模块能够根据任务需求动态调整对不同切片的关注度,从而提高模型的性能。
关键设计:TG-IS模块的设计是关键。它首先将文本指令编码成向量表示,然后使用该向量与每个2D切片的特征向量进行交互,计算出一个注意力分数。这个分数反映了该切片与当前任务的相关性。具体来说,可以使用点积注意力机制或更复杂的注意力机制来计算注意力分数。最终,将所有切片的特征向量按照注意力分数进行加权平均,得到一个融合后的2D特征表示。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Med-2E3在多个3D医学多模态数据集上取得了显著的性能提升。TG-IS模块能够学习到任务特定的注意力分布,并显著优于当前最先进的模型。具体性能数据在论文中给出,证明了该方法的有效性。
🎯 应用场景
Med-2E3具有广泛的应用前景,可用于辅助医生进行疾病诊断、病灶检测、手术规划等。通过结合3D空间信息和2D细节信息,模型能够提供更全面、准确的图像分析结果,从而提高诊断效率和准确性。未来,该模型有望应用于远程医疗、智能影像分析等领域,为医疗行业带来革命性的变革。
📄 摘要(原文)
3D medical image analysis is essential for modern healthcare, yet traditional task-specific models are inadequate due to limited generalizability across diverse clinical scenarios. Multimodal large language models (MLLMs) offer a promising solution to these challenges. However, existing MLLMs have limitations in fully leveraging the rich, hierarchical information embedded in 3D medical images. Inspired by clinical practice, where radiologists focus on both 3D spatial structure and 2D planar content, we propose Med-2E3, a 3D medical MLLM that integrates a dual 3D-2D encoder architecture. To aggregate 2D features effectively, we design a Text-Guided Inter-Slice (TG-IS) scoring module, which scores the attention of each 2D slice based on slice contents and task instructions. To the best of our knowledge, Med-2E3 is the first MLLM to integrate both 3D and 2D features for 3D medical image analysis. Experiments on large-scale, open-source 3D medical multimodal datasets demonstrate that TG-IS exhibits task-specific attention distribution and significantly outperforms current state-of-the-art models. The code is available at: https://github.com/MSIIP/Med-2E3