GaussianPretrain: A Simple Unified 3D Gaussian Representation for Visual Pre-training in Autonomous Driving
作者: Shaoqing Xu, Fang Li, Shengyin Jiang, Ziying Song, Li Liu, Zhi-xin Yang
分类: cs.CV
发布日期: 2024-11-19
备注: 10 pages, 5 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出GaussianPretrain,通过统一3D高斯表示实现自动驾驶视觉预训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自动驾驶 视觉预训练 3D高斯表示 自监督学习 场景理解
📋 核心要点
- 现有自动驾驶视觉预训练方法通常侧重于学习几何信息,忽略纹理或将两者分离,阻碍了全面的场景理解。
- GaussianPretrain将3D高斯锚点视为体素化的LiDAR点,统一整合几何和纹理信息,从而实现对场景的整体理解。
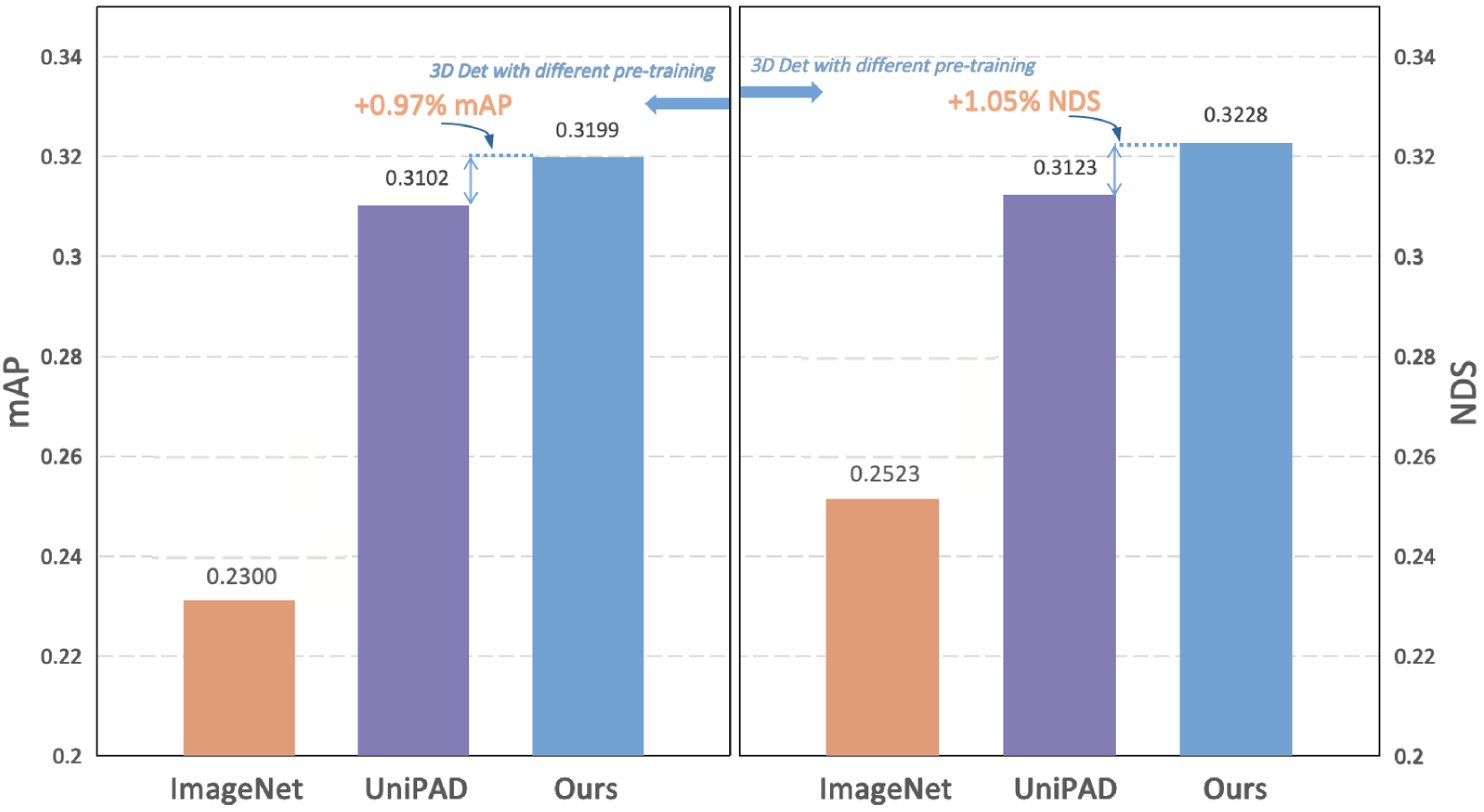
- 实验表明,GaussianPretrain在3D目标检测、HD地图构建和Occupancy预测等任务上取得了显著的性能提升。
📝 摘要(中文)
本文提出GaussianPretrain,一种新颖的预训练范式,通过统一整合几何和纹理表示,实现对场景的整体理解。该方法将3D高斯锚点概念化为体素化的LiDAR点,从而加深对场景的理解,并通过详细的空间结构和纹理来增强预训练性能。实验表明,GaussianPretrain在多个3D感知任务中表现出显著的性能提升,例如在3D目标检测中NDS提高了7.05%,在HD地图构建中mAP提高了1.9%,在Occupancy预测中提高了0.8%。此外,GaussianPretrain比基于NeRF的方法UniPAD快40.6%,且仅使用70%的GPU内存。这些显著的提升突显了GaussianPretrain的理论创新和强大的实际潜力,促进了自动驾驶视觉预训练的发展。
🔬 方法详解
问题定义:现有自动驾驶视觉预训练方法难以同时有效学习场景的几何结构和纹理信息,导致场景理解不全面,限制了下游任务的性能。现有方法要么侧重于几何信息,要么将几何和纹理信息分开处理,无法充分利用两者之间的关联性。
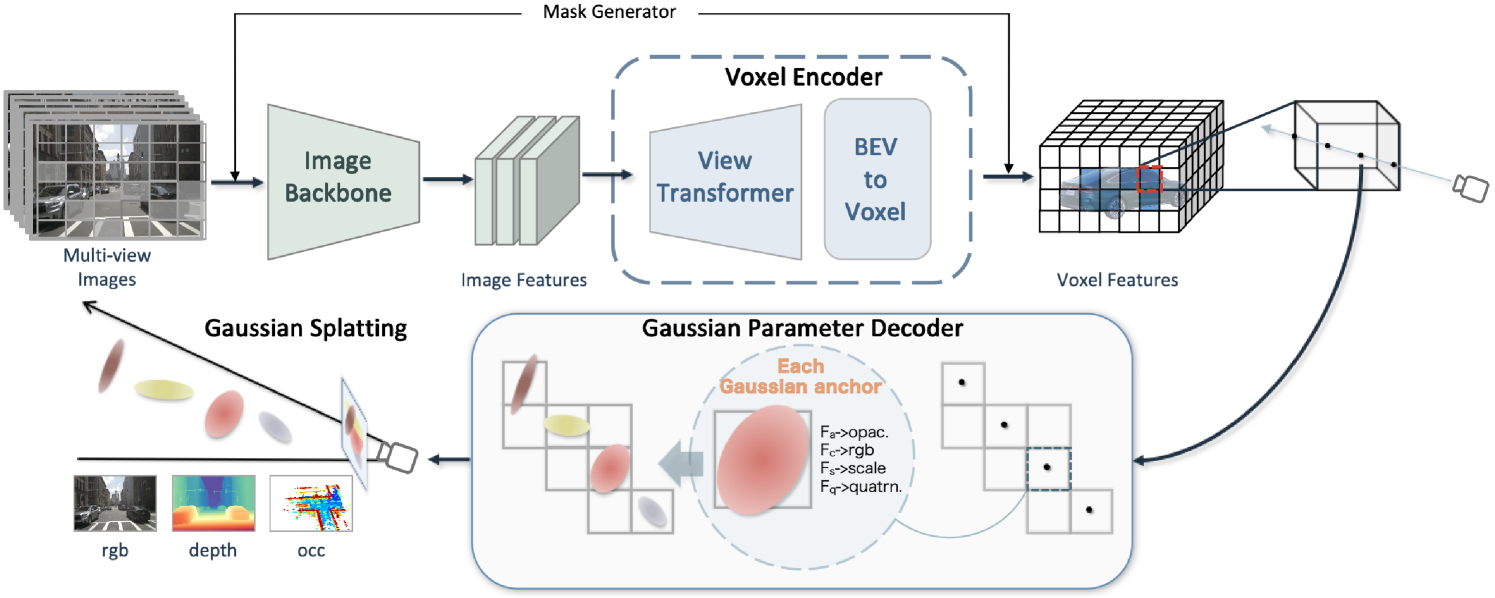
核心思路:GaussianPretrain的核心思路是将场景表示为3D高斯分布的集合,每个高斯分布同时包含几何信息(位置、形状)和纹理信息(颜色、不透明度)。通过将3D高斯锚点概念化为体素化的LiDAR点,可以有效地学习场景的几何结构和纹理信息,并建立两者之间的联系。这种统一的表示方式能够更全面地理解场景,从而提升预训练效果。
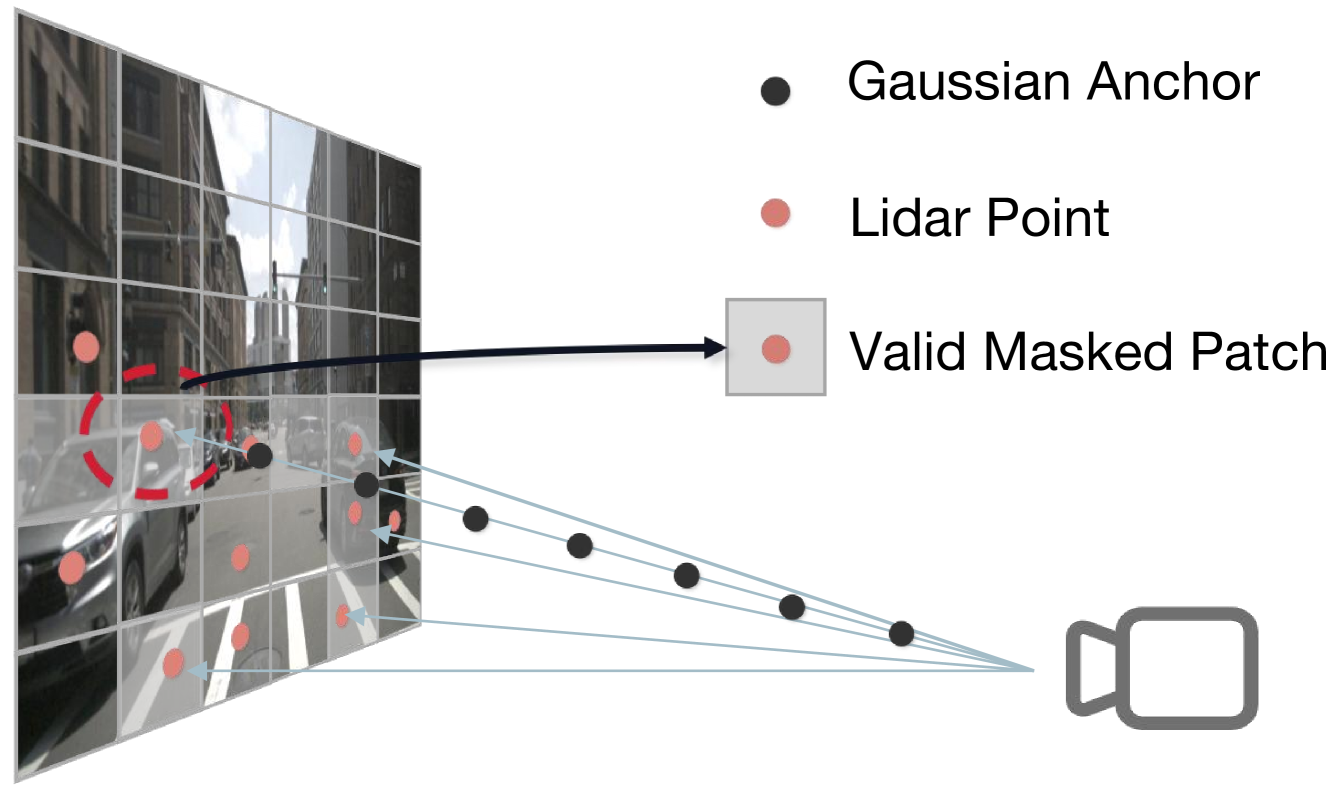
技术框架:GaussianPretrain的整体框架包括以下几个主要模块:1) 3D高斯表示:将场景表示为3D高斯分布的集合。2) 特征提取:使用神经网络提取每个高斯分布的特征,包括几何特征和纹理特征。3) 预训练任务:设计自监督预训练任务,例如掩码高斯建模(Masked Gaussian Modeling),迫使模型学习场景的结构和纹理信息。4) 微调:将预训练模型应用于下游3D感知任务,并进行微调。
关键创新:GaussianPretrain的关键创新在于使用统一的3D高斯表示来建模场景的几何结构和纹理信息。与现有方法相比,GaussianPretrain能够更全面地理解场景,并有效地学习几何和纹理信息之间的关联性。此外,将3D高斯锚点概念化为体素化的LiDAR点,使得模型能够更好地利用LiDAR数据进行预训练。
关键设计:GaussianPretrain的关键设计包括:1) 3D高斯分布的参数化方式,例如使用协方差矩阵来表示高斯分布的形状。2) 特征提取网络的结构,例如使用Transformer或MLP来提取高斯分布的特征。3) 预训练任务的设计,例如使用掩码高斯建模来迫使模型学习场景的结构和纹理信息。4) 损失函数的设计,例如使用KL散度来衡量重建高斯分布与原始高斯分布之间的差异。
🖼️ 关键图片
📊 实验亮点
GaussianPretrain在多个3D感知任务中表现出显著的性能提升。在3D目标检测任务中,GaussianPretrain使NDS提高了7.05%。在HD地图构建任务中,mAP提高了1.9%。在Occupancy预测任务中,提高了0.8%。此外,GaussianPretrain比基于NeRF的方法UniPAD快40.6%,且仅使用70%的GPU内存。这些结果表明,GaussianPretrain是一种高效且有效的自动驾驶视觉预训练方法。
🎯 应用场景
GaussianPretrain可广泛应用于自动驾驶领域的各种3D感知任务,例如3D目标检测、语义分割、HD地图构建和Occupancy预测等。通过提升预训练模型的性能,可以显著提高这些任务的准确性和鲁棒性,从而推动自动驾驶技术的发展。此外,该方法还可以应用于其他需要理解场景几何结构和纹理信息的领域,例如机器人导航、虚拟现实和增强现实等。
📄 摘要(原文)
Self-supervised learning has made substantial strides in image processing, while visual pre-training for autonomous driving is still in its infancy. Existing methods often focus on learning geometric scene information while neglecting texture or treating both aspects separately, hindering comprehensive scene understanding. In this context, we are excited to introduce GaussianPretrain, a novel pre-training paradigm that achieves a holistic understanding of the scene by uniformly integrating geometric and texture representations. Conceptualizing 3D Gaussian anchors as volumetric LiDAR points, our method learns a deepened understanding of scenes to enhance pre-training performance with detailed spatial structure and texture, achieving that 40.6% faster than NeRF-based method UniPAD with 70% GPU memory only. We demonstrate the effectiveness of GaussianPretrain across multiple 3D perception tasks, showing significant performance improvements, such as a 7.05% increase in NDS for 3D object detection, boosts mAP by 1.9% in HD map construction and 0.8% improvement on Occupancy prediction. These significant gains highlight GaussianPretrain's theoretical innovation and strong practical potential, promoting visual pre-training development for autonomous driving. Source code will be available at https://github.com/Public-BOTs/GaussianPretrain