DGTR: Distributed Gaussian Turbo-Reconstruction for Sparse-View Vast Scenes
作者: Hao Li, Yuanyuan Gao, Haosong Peng, Chenming Wu, Weicai Ye, Yufeng Zhan, Chen Zhao, Dingwen Zhang, Jingdong Wang, Junwei Han
分类: cs.CV
发布日期: 2024-11-19 (更新: 2024-11-20)
备注: Code will released on our [https://3d-aigc.github.io/DGTR]
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出DGTR:用于稀疏视图大场景的高效分布式高斯重建方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 新视角合成 高斯重建 分布式计算 无人机航拍 场景重建
📋 核心要点
- 现有新视角合成方法依赖于密集的图像输入和长时间的训练,难以应用于计算资源受限的大场景重建。
- DGTR采用分布式架构,将场景分割成小区域,利用无人机独立处理,并使用高斯模型预测高质量基元。
- 实验表明,DGTR在大幅缩短训练时间的同时,实现了高质量的大规模场景重建和新视角合成。
📝 摘要(中文)
本文提出了一种名为DGTR的分布式框架,用于高效地进行稀疏视图大场景的高斯重建。该方法将场景划分为多个区域,由配备稀疏图像输入的无人机独立处理。利用前馈高斯模型预测高质量的高斯基元,然后使用全局对齐算法确保几何一致性。为了进一步增强训练,还引入了合成视图和深度先验。基于蒸馏的模型聚合机制实现了高效的重建。该方法在显著减少训练时间的同时,实现了高质量的大规模场景重建和新视角合成,在速度和可扩展性方面均优于现有方法。在广阔的航拍场景中验证了该框架的有效性,并在几分钟内获得了高质量的结果。
🔬 方法详解
问题定义:现有新视角合成方法在大场景重建中面临挑战,主要体现在两个方面:一是需要密集的图像输入,二是训练时间过长,这使得它们难以应用于计算资源有限的场景,例如无人机集群协同重建大场景。此外,少样本学习方法在大场景中重建质量往往较差。
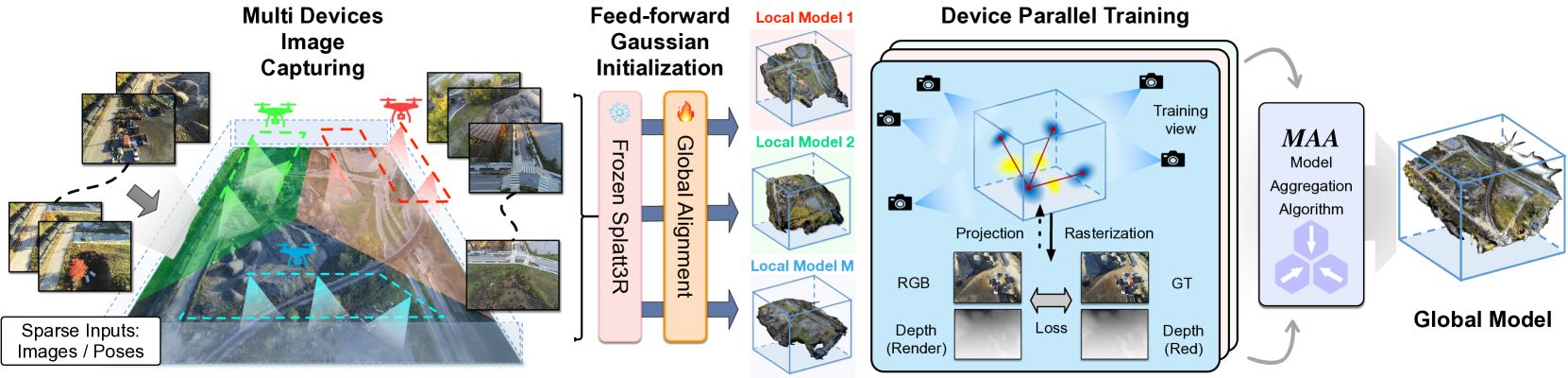
核心思路:DGTR的核心思路是将大场景分割成多个小区域,每个区域由独立的无人机进行处理,从而实现分布式的重建。每个无人机利用稀疏的图像输入,通过前馈高斯模型预测高质量的高斯基元。通过全局对齐算法保证各个区域之间的几何一致性,并利用合成视图和深度先验来增强训练。最后,采用基于蒸馏的模型聚合机制,将各个无人机学习到的模型进行融合,实现高效的重建。
技术框架:DGTR的整体框架包括以下几个主要模块:1) 场景分割模块:将大场景分割成多个小区域。2) 局部重建模块:每个无人机独立处理一个区域,利用稀疏的图像输入,通过前馈高斯模型预测高质量的高斯基元。3) 全局对齐模块:对各个区域的重建结果进行全局对齐,保证几何一致性。4) 模型聚合模块:采用基于蒸馏的模型聚合机制,将各个无人机学习到的模型进行融合。5) 渲染模块:利用高斯基元进行新视角合成。
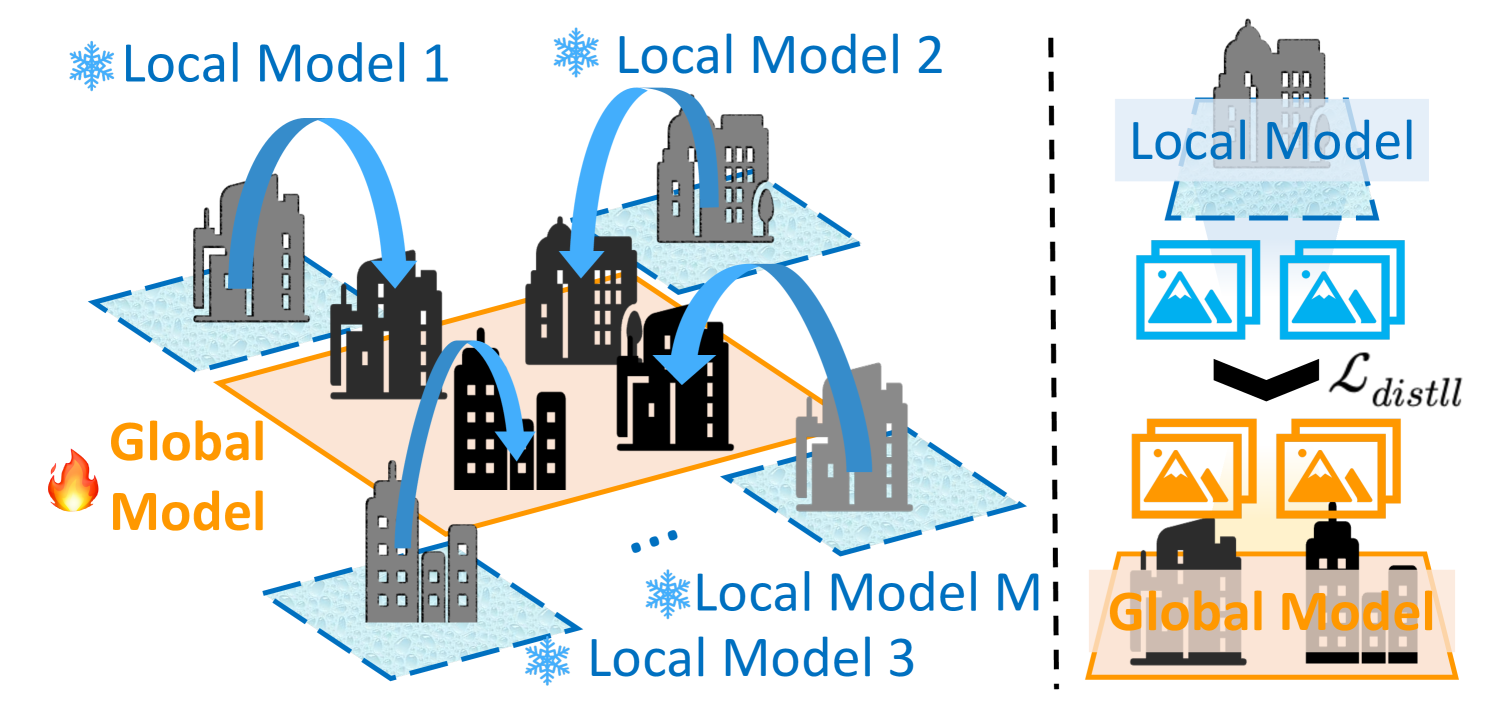
关键创新:DGTR的关键创新在于以下几个方面:1) 分布式架构:将大场景重建任务分解成多个独立的子任务,由多个无人机并行处理,从而提高了重建效率和可扩展性。2) 前馈高斯模型:利用前馈网络直接预测高斯基元,避免了传统方法中复杂的优化过程。3) 基于蒸馏的模型聚合:将各个无人机学习到的模型进行融合,提高了重建质量和泛化能力。
关键设计:在局部重建模块中,采用了基于高斯分布的场景表示方法,使用3D高斯基元来表示场景的几何和外观信息。损失函数包括图像重建损失、深度一致性损失和正则化损失。在模型聚合模块中,采用了基于知识蒸馏的方法,将各个无人机学习到的模型作为教师模型,训练一个全局的学生模型。学生模型的目标是模仿教师模型的输出,从而将各个教师模型的知识进行融合。
🖼️ 关键图片

📊 实验亮点
DGTR在广阔的航拍场景中进行了实验验证,结果表明,该方法可以在几分钟内实现高质量的大规模场景重建和新视角合成,在速度和可扩展性方面均优于现有方法。具体而言,DGTR在重建质量上与现有方法相当,但训练时间缩短了几个数量级。例如,在某个场景中,DGTR可以在10分钟内完成重建,而现有方法需要数小时。
🎯 应用场景
DGTR在无人机航拍场景重建、城市建模、虚拟现实等领域具有广泛的应用前景。该方法可以用于快速构建大规模场景的三维模型,为城市规划、环境监测、灾害救援等提供支持。此外,DGTR还可以应用于虚拟现实和增强现实等领域,为用户提供更加逼真的沉浸式体验。
📄 摘要(原文)
Novel-view synthesis (NVS) approaches play a critical role in vast scene reconstruction. However, these methods rely heavily on dense image inputs and prolonged training times, making them unsuitable where computational resources are limited. Additionally, few-shot methods often struggle with poor reconstruction quality in vast environments. This paper presents DGTR, a novel distributed framework for efficient Gaussian reconstruction for sparse-view vast scenes. Our approach divides the scene into regions, processed independently by drones with sparse image inputs. Using a feed-forward Gaussian model, we predict high-quality Gaussian primitives, followed by a global alignment algorithm to ensure geometric consistency. Synthetic views and depth priors are incorporated to further enhance training, while a distillation-based model aggregation mechanism enables efficient reconstruction. Our method achieves high-quality large-scale scene reconstruction and novel-view synthesis in significantly reduced training times, outperforming existing approaches in both speed and scalability. We demonstrate the effectiveness of our framework on vast aerial scenes, achieving high-quality results within minutes. Code will released on our [https://3d-aigc.github.io/DGTR].