Generative Timelines for Instructed Visual Assembly
作者: Alejandro Pardo, Jui-Hsien Wang, Bernard Ghanem, Josef Sivic, Bryan Russell, Fabian Caba Heilbron
分类: cs.CV, cs.HC, cs.MM
发布日期: 2024-11-19
💡 一句话要点
提出Timeline Assembler,通过自然语言指令生成式编辑视觉时间线
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉时间线编辑 自然语言指令 生成模型 多模态学习 视频组装 自动数据生成 指令式编辑
📋 核心要点
- 现有方法难以让非专业人士通过自然语言指令编辑视觉时间线,存在理解指令和编辑时间线的挑战。
- 提出Timeline Assembler,一个生成模型,通过多模态语言模型处理视觉内容和指令,生成编辑后的时间线。
- 通过自动生成数据集进行训练,并在图像和视频组装数据集上验证,显著优于GPT-4o等基线模型。
📝 摘要(中文)
本研究旨在通过自然语言指令操纵视觉时间线(例如视频),使非专业人士甚至残疾用户也能进行复杂的时间线编辑任务,称之为指令式视觉组装。该任务极具挑战性,因为它需要(i)识别输入时间线中的相关视觉内容,并在给定的输入(视频)集合中检索相关视觉内容,(ii)理解输入的自然语言指令,以及(iii)执行对输入视觉时间线的所需编辑以生成输出时间线。为了应对这些挑战,我们提出了时间线组装器(Timeline Assembler),这是一个经过训练以执行指令式视觉组装任务的生成模型。本研究的贡献有三方面。首先,我们开发了一个大型多模态语言模型,旨在处理视觉内容,紧凑地表示时间线并准确地解释时间线编辑指令。其次,我们引入了一种新颖的方法,用于自动生成视觉组装任务的数据集,从而无需人工标注数据即可高效地训练我们的模型。第三,我们通过创建两个用于图像和视频组装的新数据集来验证我们的方法,证明时间线组装器在各种受现实世界启发的场景中,在准确执行复杂组装指令方面,大大优于包括最近的GPT-4o在内的已建立的基线模型。
🔬 方法详解
问题定义:论文旨在解决通过自然语言指令编辑视觉时间线的问题,使得非专业用户也能完成复杂的视频编辑任务。现有方法的痛点在于难以理解自然语言指令的意图,并准确地在视觉内容中定位和组装所需片段。
核心思路:论文的核心思路是构建一个生成模型,该模型能够将视觉时间线和自然语言指令作为输入,并生成编辑后的时间线。这种生成式的方法允许模型学习从指令到编辑操作的映射关系,从而实现灵活且可控的编辑。
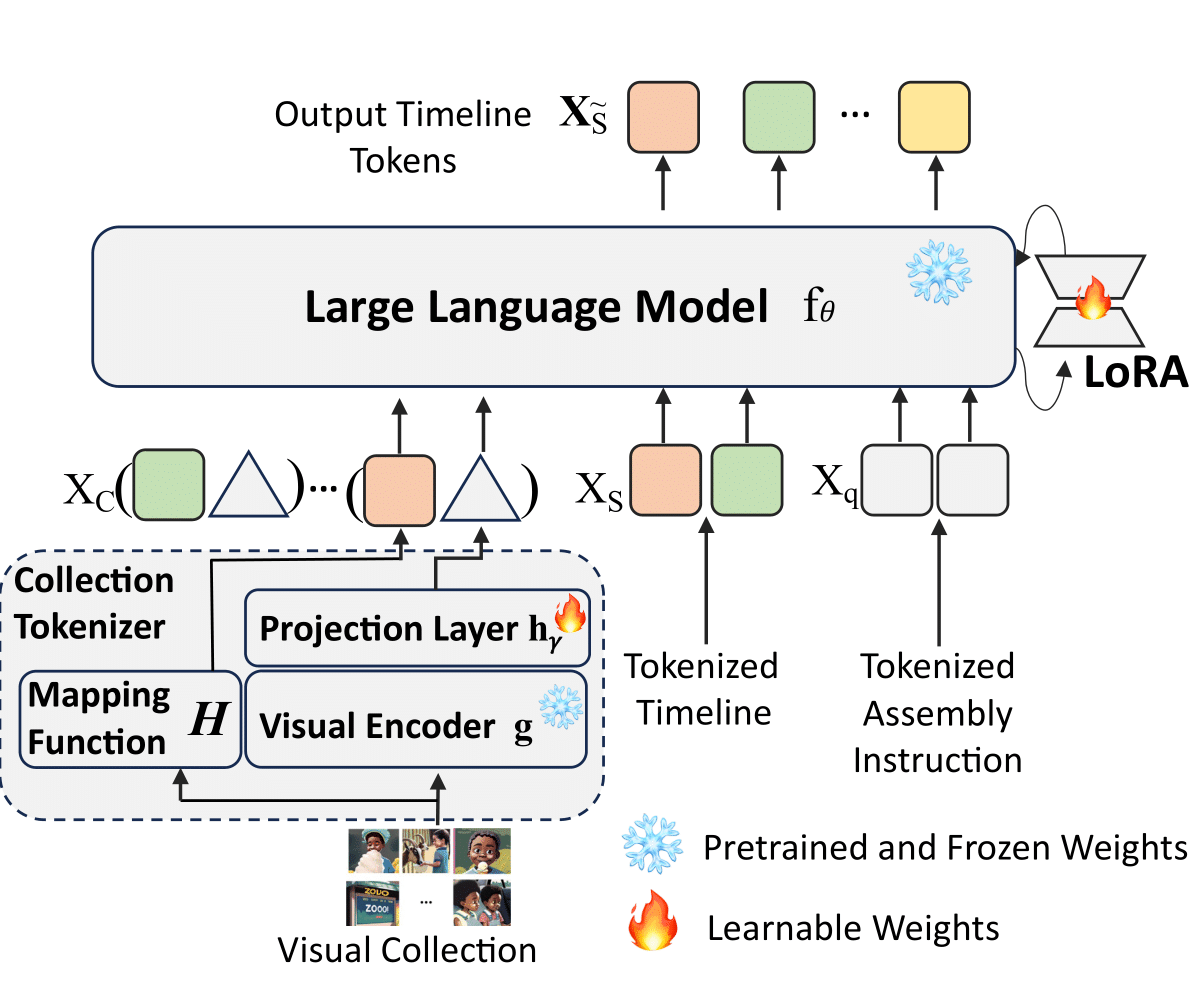
技术框架:Timeline Assembler的技术框架包含以下几个主要模块:1) 多模态语言模型:用于处理视觉内容和自然语言指令,提取特征并进行融合。2) 时间线表示模块:用于将视觉时间线压缩成紧凑的表示形式,以便于模型处理。3) 生成模块:基于多模态特征和时间线表示,生成编辑后的时间线。整个流程是端到端的,模型直接从原始视觉内容和指令生成最终结果。
关键创新:论文最重要的技术创新点在于提出了一种自动生成数据集的方法,用于训练视觉组装任务的模型。这种方法避免了人工标注的成本和限制,使得模型能够在大规模数据上进行训练,从而提高性能。此外,多模态语言模型的设计也考虑了视觉内容和语言指令的有效融合。
关键设计:论文的关键设计包括:1) 多模态语言模型的具体结构,例如Transformer架构的选择和参数设置。2) 时间线表示模块的压缩算法,例如使用关键帧提取或视频摘要技术。3) 生成模块的损失函数设计,例如使用生成对抗网络(GAN)或变分自编码器(VAE)等方法,以保证生成结果的质量和多样性。4) 自动生成数据集的具体策略,例如使用程序化生成或基于规则的方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Timeline Assembler在图像和视频组装任务上显著优于基线模型,包括GPT-4o。具体而言,在两个新数据集上,Timeline Assembler在准确执行复杂组装指令方面取得了显著的性能提升,证明了其在处理多模态输入和生成高质量视觉内容方面的有效性。
🎯 应用场景
该研究成果可应用于视频编辑软件,简化复杂编辑流程,降低使用门槛。潜在应用领域包括:教育视频制作、社交媒体内容创作、辅助残疾人士进行视频编辑等。未来可扩展到更复杂的视觉内容生成和编辑任务,例如虚拟现实场景构建。
📄 摘要(原文)
The objective of this work is to manipulate visual timelines (e.g. a video) through natural language instructions, making complex timeline editing tasks accessible to non-expert or potentially even disabled users. We call this task Instructed visual assembly. This task is challenging as it requires (i) identifying relevant visual content in the input timeline as well as retrieving relevant visual content in a given input (video) collection, (ii) understanding the input natural language instruction, and (iii) performing the desired edits of the input visual timeline to produce an output timeline. To address these challenges, we propose the Timeline Assembler, a generative model trained to perform instructed visual assembly tasks. The contributions of this work are three-fold. First, we develop a large multimodal language model, which is designed to process visual content, compactly represent timelines and accurately interpret timeline editing instructions. Second, we introduce a novel method for automatically generating datasets for visual assembly tasks, enabling efficient training of our model without the need for human-labeled data. Third, we validate our approach by creating two novel datasets for image and video assembly, demonstrating that the Timeline Assembler substantially outperforms established baseline models, including the recent GPT-4o, in accurately executing complex assembly instructions across various real-world inspired scenarios.