TimeFormer: Capturing Temporal Relationships of Deformable 3D Gaussians for Robust Reconstruction
作者: DaDong Jiang, Zhihui Ke, Xiaobo Zhou, Zhi Hou, Xianghui Yang, Wenbo Hu, Tie Qiu, Chunchao Guo
分类: cs.CV
发布日期: 2024-11-18 (更新: 2025-10-06)
备注: ICCV 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出TimeFormer,通过时序Transformer建模动态3D高斯重建中的运动关系
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态场景重建 3D高斯溅射 Transformer 时序建模 运动估计 双流优化 知识蒸馏
📋 核心要点
- 现有动态3D高斯重建方法独立处理各时间戳,难以应对剧烈运动、复杂几何或反射表面。
- TimeFormer通过跨时序Transformer学习3D高斯的时序关系,隐式建模运动模式,提升重建效果。
- TimeFormer采用双流优化,训练时传递运动知识,推理时移除,保持渲染速度并提升重建质量。
📝 摘要(中文)
动态场景重建是3D视觉领域长期存在的挑战。现有方法通过额外的形变场扩展3D高斯溅射到动态场景,并应用显式约束(如运动光流)来指导形变。然而,它们独立地从各个时间戳学习运动变化,这使得重建复杂场景变得困难,尤其是在处理剧烈运动、极端形状几何体或反射表面时。为了解决上述问题,我们设计了一个名为TimeFormer的即插即用模块,使现有的可变形3D高斯重建方法能够从学习的角度隐式地建模运动模式。具体来说,TimeFormer包括一个跨时序Transformer编码器,它可以自适应地学习可变形3D高斯的时序关系。此外,我们提出了一种双流优化策略,在训练阶段将从TimeFormer学习到的运动知识转移到基础流。这允许我们在推理过程中移除TimeFormer,从而保持原始的渲染速度。在多视角和单目动态场景中的大量实验验证了TimeFormer带来的定性和定量改进。
🔬 方法详解
问题定义:现有动态场景重建方法,特别是基于可变形3D高斯的方法,在处理复杂运动时表现不佳。这些方法通常独立地分析每个时间戳的信息,缺乏对时间序列运动模式的理解,导致在剧烈运动、复杂几何形状或反射表面等情况下重建效果下降。现有方法依赖显式的运动约束(如光流),限制了其泛化能力和鲁棒性。
核心思路:TimeFormer的核心思路是利用Transformer架构来建模3D高斯的时序关系。通过学习不同时间点高斯参数之间的依赖性,TimeFormer能够隐式地捕捉运动模式,从而提高重建的准确性和鲁棒性。这种方法避免了对显式运动约束的依赖,使其能够更好地处理复杂的动态场景。
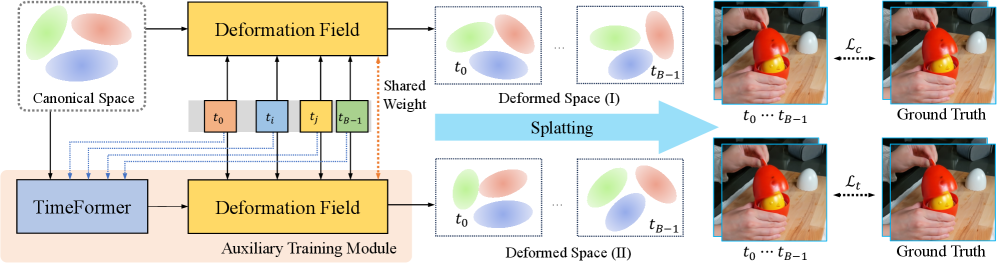
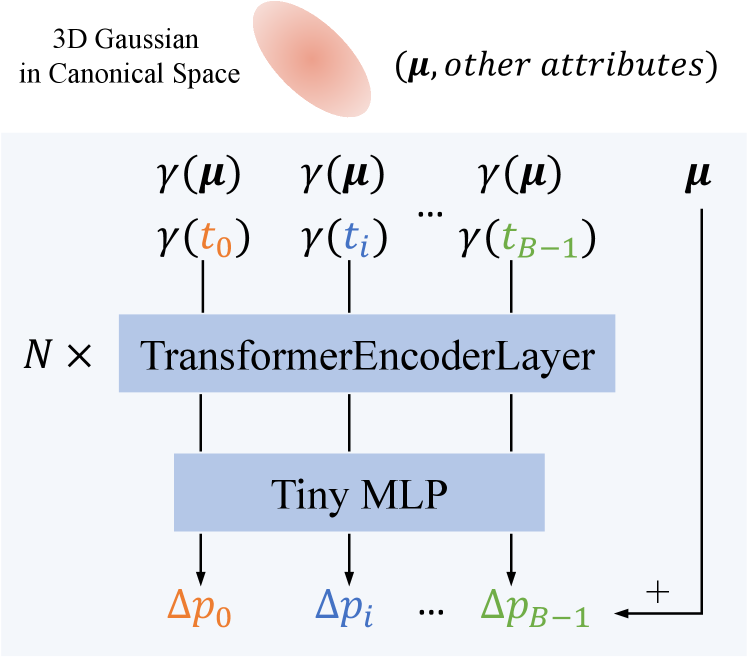
技术框架:TimeFormer是一个即插即用的模块,可以集成到现有的可变形3D高斯重建框架中。其主要组成部分是跨时序Transformer编码器,该编码器接收来自不同时间戳的3D高斯参数作为输入,并输出包含时序信息的特征表示。此外,论文提出了一种双流优化策略,包括一个基础流和一个TimeFormer流。在训练过程中,TimeFormer流学习到的运动知识被转移到基础流,从而提高基础流的性能。在推理过程中,TimeFormer模块可以被移除,以保持原始的渲染速度。
关键创新:TimeFormer的关键创新在于使用Transformer架构来隐式地建模3D高斯的时序关系。与现有方法相比,TimeFormer不需要显式的运动约束,而是通过学习数据中的潜在模式来提高重建的准确性和鲁棒性。此外,双流优化策略允许在训练过程中利用TimeFormer的优势,并在推理过程中保持渲染速度。
关键设计:TimeFormer中的Transformer编码器采用标准的多头注意力机制,用于学习不同时间戳高斯参数之间的依赖性。双流优化策略通过一个知识蒸馏损失函数来实现,该损失函数鼓励基础流的输出与TimeFormer流的输出尽可能接近。具体的损失函数形式和参数设置在论文中有详细描述。TimeFormer作为一个独立的模块,可以方便地集成到各种基于可变形3D高斯的动态场景重建方法中。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TimeFormer在多视角和单目动态场景中均取得了显著的性能提升。与现有方法相比,TimeFormer能够更准确地重建剧烈运动和复杂几何形状的场景。定量结果显示,TimeFormer在重建质量指标上取得了明显的改进,例如PSNR和SSIM等指标均有显著提升。此外,TimeFormer在推理过程中可以被移除,从而保持了原始的渲染速度。
🎯 应用场景
TimeFormer在动态场景重建领域具有广泛的应用前景,例如:虚拟现实/增强现实(VR/AR)、自动驾驶、机器人导航、运动捕捉和视频编辑等。通过提高动态场景重建的准确性和鲁棒性,TimeFormer可以为这些应用提供更真实、更可靠的3D环境感知能力,从而提升用户体验和系统性能。未来,该技术有望应用于更复杂的动态场景,例如人群场景和具有复杂光照效果的场景。
📄 摘要(原文)
Dynamic scene reconstruction is a long-term challenge in 3D vision. Recent methods extend 3D Gaussian Splatting to dynamic scenes via additional deformation fields and apply explicit constraints like motion flow to guide the deformation. However, they learn motion changes from individual timestamps independently, making it challenging to reconstruct complex scenes, particularly when dealing with violent movement, extreme-shaped geometries, or reflective surfaces. To address the above issue, we design a plug-and-play module called TimeFormer to enable existing deformable 3D Gaussians reconstruction methods with the ability to implicitly model motion patterns from a learning perspective. Specifically, TimeFormer includes a Cross-Temporal Transformer Encoder, which adaptively learns the temporal relationships of deformable 3D Gaussians. Furthermore, we propose a two-stream optimization strategy that transfers the motion knowledge learned from TimeFormer to the base stream during the training phase. This allows us to remove TimeFormer during inference, thereby preserving the original rendering speed. Extensive experiments in the multi-view and monocular dynamic scenes validate qualitative and quantitative improvement brought by TimeFormer. Project Page: https://patrickddj.github.io/TimeFormer/