FLAME: Frozen Large Language Models Enable Data-Efficient Language-Image Pre-training
作者: Anjia Cao, Xing Wei, Zhiheng Ma
分类: cs.CV
发布日期: 2024-11-18 (更新: 2025-04-26)
🔗 代码/项目: GITHUB
💡 一句话要点
FLAME:利用冻结的大型语言模型实现数据高效的语言-图像预训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言-图像预训练 大型语言模型 提示蒸馏 解耦注意力 长文本处理 多语言 对比学习
📋 核心要点
- 现有语言-图像预训练方法在处理长文本和利用文本编码器的泛化能力方面存在局限性。
- FLAME通过冻结大型语言模型作为文本编码器,并结合提示蒸馏和解耦注意力机制来解决上述问题。
- 实验表明,FLAME在多个数据集上显著优于现有方法,尤其是在长文本和多语言场景下。
📝 摘要(中文)
语言-图像预训练面临着特定格式数据有限和文本编码器容量受限的重大挑战。虽然现有方法试图通过数据增强和架构修改来解决这些问题,但它们仍然难以处理长文本输入,并且传统CLIP文本编码器的固有局限性导致次优的下游泛化性能。本文提出了FLAME(Frozen Large lAnguage Models Enable data-efficient language-image pre-training),它利用冻结的大型语言模型作为文本编码器,自然地处理长文本输入并展示出令人印象深刻的多语言泛化能力。FLAME包含两个关键组件:1) 一种多方面的提示蒸馏技术,用于从长标题中提取多样化的语义表示,从而更好地与图像的多方面性质对齐;2) 一种解耦的注意力机制,辅以离线嵌入策略,以确保高效的计算。大量的实验评估表明FLAME具有卓越的性能。在CC3M上训练时,FLAME在ImageNet top-1准确率上超过了先前的最先进水平4.9%。在YFCC15M上,FLAME在36种语言的平均图像到文本的recall@1上超过了经过WIT-400M训练的CLIP 44.4%,并且在Urban-1k上的长上下文检索的文本到图像的recall@1上超过了34.6%。
🔬 方法详解
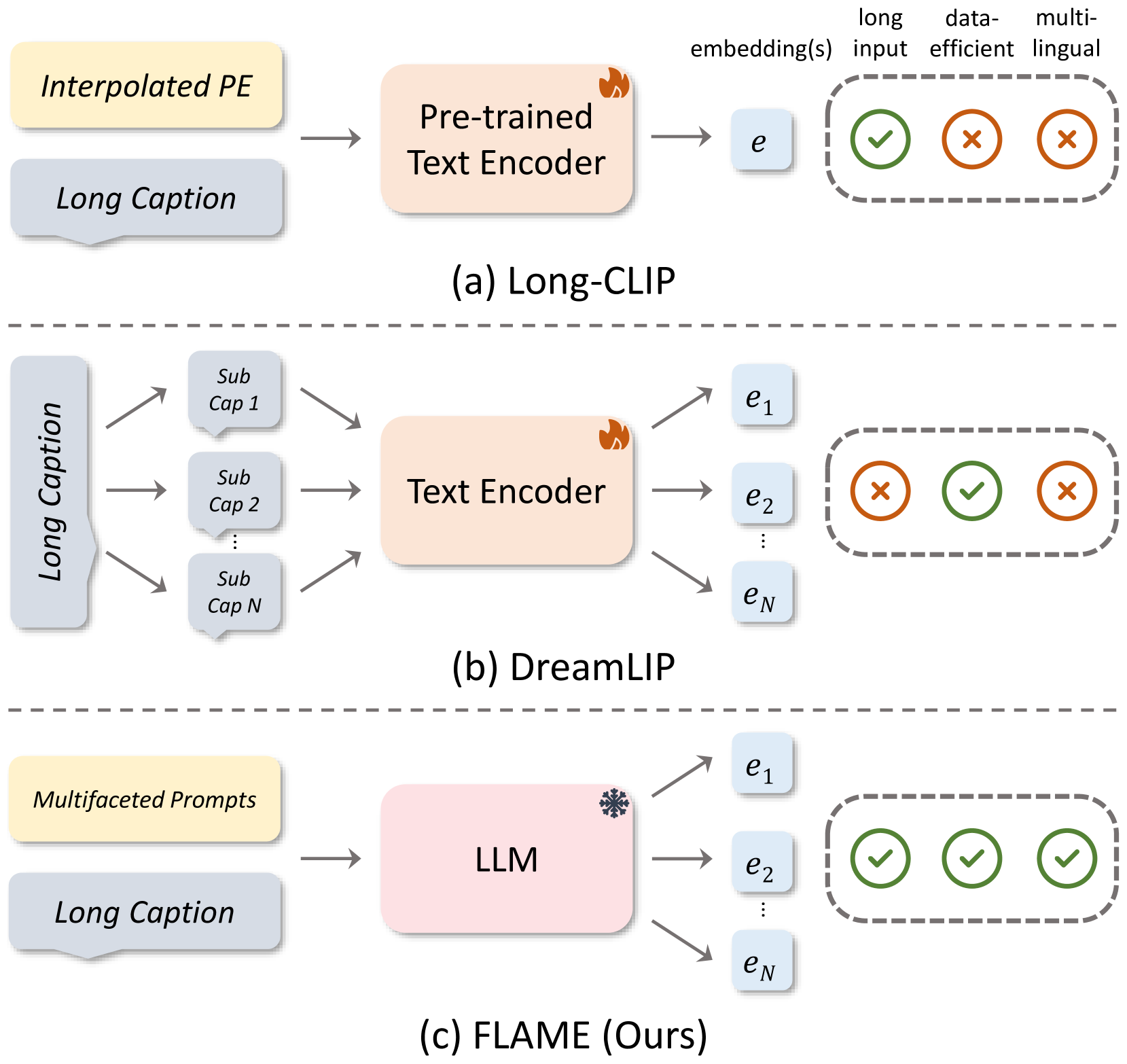
问题定义:现有语言-图像预训练方法难以有效处理长文本输入,并且传统CLIP文本编码器的泛化能力有限,导致下游任务性能受限。现有方法通常采用数据增强和架构修改,但效果不佳。
核心思路:FLAME的核心思路是利用预训练好的大型语言模型(LLM)作为文本编码器,并将其参数冻结,从而利用LLM强大的语言理解和生成能力。通过提示蒸馏,从长文本标题中提取更丰富的语义信息,并设计解耦注意力机制以提高计算效率。
技术框架:FLAME包含两个主要模块:1) 多方面提示蒸馏模块,用于从长文本标题中提取多样化的语义表示;2) 解耦注意力机制模块,辅以离线嵌入策略,用于高效计算图像和文本之间的相似度。整体流程是:首先使用提示蒸馏模块处理文本,然后使用解耦注意力机制计算图像和文本的相似度,最后使用对比学习目标进行训练。
关键创新:FLAME的关键创新在于:1) 利用冻结的LLM作为文本编码器,充分利用了LLM的强大能力;2) 提出了多方面提示蒸馏技术,能够从长文本标题中提取更丰富的语义信息;3) 设计了解耦注意力机制,提高了计算效率。与现有方法不同,FLAME没有对LLM进行微调,而是通过提示蒸馏和解耦注意力机制来适应语言-图像预训练任务。
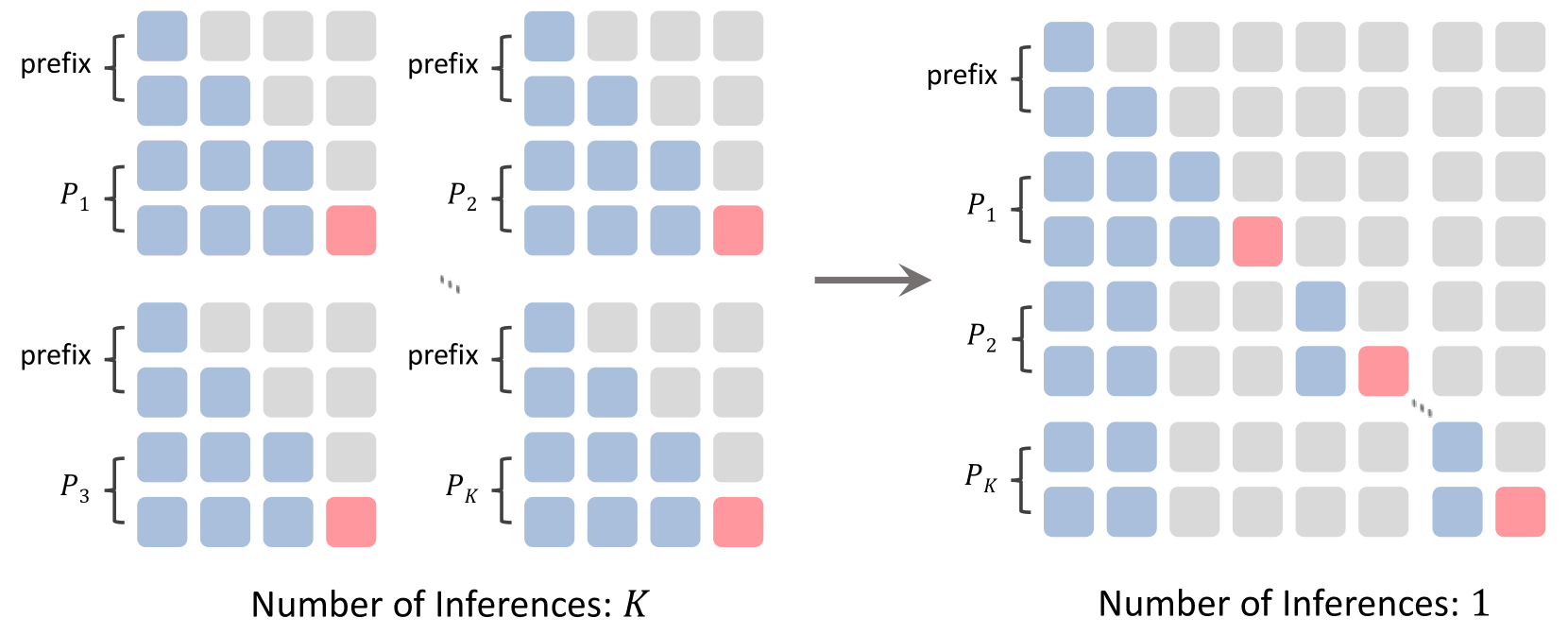
关键设计:多方面提示蒸馏模块使用多个不同的提示语来引导LLM生成不同的文本表示,然后将这些表示组合起来,形成最终的文本表示。解耦注意力机制将注意力计算分解为两个步骤:首先计算图像和文本的局部特征之间的注意力,然后计算全局特征之间的注意力。离线嵌入策略预先计算图像和文本的嵌入向量,从而减少在线计算量。
🖼️ 关键图片

📊 实验亮点
FLAME在CC3M数据集上训练后,在ImageNet top-1准确率上超过了之前的SOTA方法4.9%。在YFCC15M数据集上,FLAME在36种语言的平均图像到文本的recall@1上超过了经过WIT-400M训练的CLIP 44.4%,并且在Urban-1k数据集上的长上下文检索的文本到图像的recall@1上超过了34.6%。这些结果表明FLAME在数据效率和泛化能力方面具有显著优势。
🎯 应用场景
FLAME可应用于各种需要理解长文本描述的图像相关任务,例如图像检索、图像描述生成、视觉问答等。该研究的实际价值在于提高了语言-图像预训练的效率和性能,尤其是在长文本和多语言场景下。未来,FLAME可以进一步扩展到其他多模态任务,例如视频理解和语音识别。
📄 摘要(原文)
Language-image pre-training faces significant challenges due to limited data in specific formats and the constrained capacities of text encoders. While prevailing methods attempt to address these issues through data augmentation and architecture modifications, they continue to struggle with processing long-form text inputs, and the inherent limitations of traditional CLIP text encoders lead to suboptimal downstream generalization. In this paper, we propose FLAME (Frozen Large lAnguage Models Enable data-efficient language-image pre-training) that leverages frozen large language models as text encoders, naturally processing long text inputs and demonstrating impressive multilingual generalization. FLAME comprises two key components: 1) a multifaceted prompt distillation technique for extracting diverse semantic representations from long captions, which better aligns with the multifaceted nature of images, and 2) a facet-decoupled attention mechanism, complemented by an offline embedding strategy, to ensure efficient computation. Extensive empirical evaluations demonstrate FLAME's superior performance. When trained on CC3M, FLAME surpasses the previous state-of-the-art by 4.9% in ImageNet top-1 accuracy. On YFCC15M, FLAME surpasses the WIT-400M-trained CLIP by 44.4\% in average image-to-text recall@1 across 36 languages, and by 34.6% in text-to-image recall@1 for long-context retrieval on Urban-1k. Code is available at https://github.com/MIV-XJTU/FLAME.