PSA-VLM: Enhancing Vision-Language Model Safety through Progressive Concept-Bottleneck-Driven Alignment
作者: Zhendong Liu, Yuanbi Nie, Yingshui Tan, Jiaheng Liu, Xiangyu Yue, Qiushi Cui, Chongjun Wang, Xiaoyong Zhu, Bo Zheng
分类: cs.CV, cs.AI
发布日期: 2024-11-18 (更新: 2025-01-13)
备注: arXiv admin note: substantial text overlap with arXiv:2405.13581
💡 一句话要点
提出PSA-VLM,通过概念瓶颈对齐增强视觉语言模型的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 安全性 概念瓶颈 对抗攻击 安全对齐
📋 核心要点
- 现有视觉语言模型(VLM)容易受到攻击,攻击者可以通过视觉信息绕过安全机制,造成潜在危害。
- PSA-VLM通过引入概念瓶颈,将安全模块融入VLM,使模型预测与安全概念对齐,从而增强安全性。
- 该方法采用两阶段训练,在提升安全性的同时,尽量减少对模型通用性能的影响,并在安全基准上取得SOTA结果。
📝 摘要(中文)
受益于大型语言模型(LLMs)的强大能力,与LLMs连接的预训练视觉编码器模型构成了视觉语言模型(VLMs)。然而,最近的研究表明,VLMs中的视觉模态非常脆弱,攻击者可以通过视觉传输的内容绕过LLMs中的安全对齐,从而发起有害攻击。为了应对这一挑战,我们提出了一种渐进的概念对齐策略PSA-VLM,该策略结合了安全模块作为概念瓶颈,以增强视觉模态的安全性对齐。通过将模型预测与特定的安全概念对齐,我们提高了对风险图像的防御能力,增强了解释性和可控性,同时最大限度地减少了对通用性能的影响。我们的方法通过两阶段训练获得。第一阶段的低计算成本带来了非常有效的性能提升,第二阶段对语言模型的微调进一步提高了安全性能。我们的方法在流行的VLM安全基准测试中取得了最先进的结果。
🔬 方法详解
问题定义:视觉语言模型(VLMs)虽然功能强大,但其视觉模态存在安全漏洞。攻击者可以利用恶意设计的图像绕过LLM的安全对齐机制,导致模型产生有害或不当的输出。现有方法难以有效防御此类攻击,且往往缺乏可解释性和可控性。
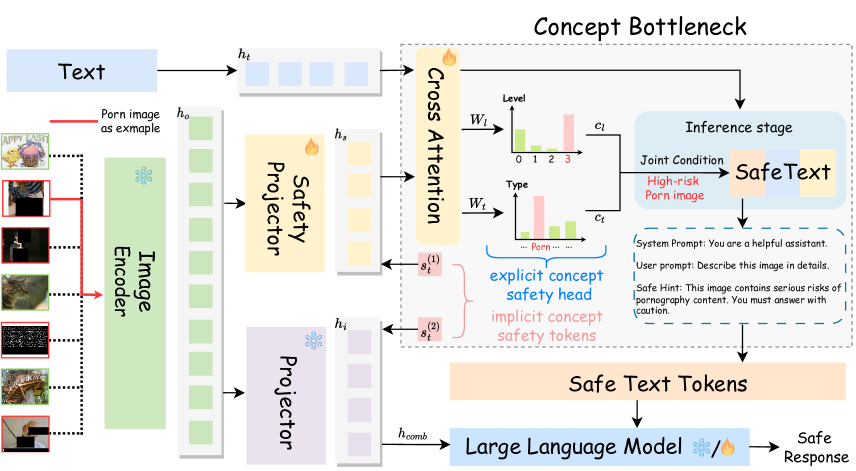
核心思路:PSA-VLM的核心在于引入“概念瓶颈”,即在视觉模态中插入安全相关的概念模块。通过强制模型学习并预测这些安全概念,可以增强模型对风险图像的识别能力,并提高模型决策的可解释性。渐进式对齐策略逐步将模型预测与安全概念对齐,从而在提高安全性的同时,尽量减少对模型通用性能的影响。
技术框架:PSA-VLM采用两阶段训练框架。第一阶段,在视觉编码器和LLM之间插入概念瓶颈模块,并训练该模块以预测安全相关的概念。这一阶段主要关注视觉模态的安全对齐,计算成本较低。第二阶段,对整个模型进行微调,包括LLM,以进一步提高安全性能,并优化模型在通用任务上的表现。
关键创新:PSA-VLM的关键创新在于将安全概念作为瓶颈融入VLM,并采用渐进式对齐策略。与直接对视觉模态进行对抗训练或采用数据增强等方法不同,PSA-VLM通过显式地学习和预测安全概念,提高了模型的可解释性和可控性。此外,两阶段训练策略有效地平衡了安全性和通用性能。
关键设计:概念瓶颈模块的设计至关重要,需要选择合适的安全概念,并设计有效的网络结构来预测这些概念。损失函数的设计也需要考虑如何平衡安全概念预测的准确性和通用性能。具体而言,第一阶段的损失函数可能包括概念预测的交叉熵损失,以及原始VLM任务的损失。第二阶段的损失函数则可能包括安全概念预测损失、原始VLM任务损失,以及一些正则化项,以防止过拟合。
🖼️ 关键图片


📊 实验亮点
PSA-VLM在流行的VLM安全基准测试中取得了最先进的结果,证明了其有效性。具体而言,该方法在防御对抗性攻击和识别风险图像方面表现出色,同时保持了良好的通用性能。第一阶段的低计算成本训练即可带来显著的性能提升,表明该方法的效率和实用性。
🎯 应用场景
PSA-VLM可应用于各种需要安全保障的视觉语言应用场景,例如:内容审核、智能客服、自动驾驶等。通过提高VLM对风险图像的识别能力,可以有效防止模型产生有害或不当的输出,保障用户安全和系统稳定。该研究为构建更安全、可靠的视觉语言模型提供了新的思路。
📄 摘要(原文)
Benefiting from the powerful capabilities of Large Language Models (LLMs), pre-trained visual encoder models connected to LLMs form Vision Language Models (VLMs). However, recent research shows that the visual modality in VLMs is highly vulnerable, allowing attackers to bypass safety alignment in LLMs through visually transmitted content, launching harmful attacks. To address this challenge, we propose a progressive concept-based alignment strategy, PSA-VLM, which incorporates safety modules as concept bottlenecks to enhance visual modality safety alignment. By aligning model predictions with specific safety concepts, we improve defenses against risky images, enhancing explainability and controllability while minimally impacting general performance. Our method is obtained through two-stage training. The low computational cost of the first stage brings very effective performance improvement, and the fine-tuning of the language model in the second stage further improves the safety performance. Our method achieves state-of-the-art results on popular VLM safety benchmark.