LaVin-DiT: Large Vision Diffusion Transformer
作者: Zhaoqing Wang, Xiaobo Xia, Runnan Chen, Dongdong Yu, Changhu Wang, Mingming Gong, Tongliang Liu
分类: cs.CV
发布日期: 2024-11-18 (更新: 2025-03-06)
备注: 37 pages, 30 figures, 4 tables. Accepted by CVPR 2025
💡 一句话要点
提出LaVin-DiT,一种用于解决多种视觉任务的可扩展统一视觉扩散Transformer基础模型。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础模型 扩散Transformer 生成模型 多任务学习 上下文学习
📋 核心要点
- 现有大型视觉模型通常基于NLP架构,采用自回归方法,效率较低且破坏了视觉数据的空间关系。
- LaVin-DiT通过空间-时间VAE编码高维视觉数据到潜在空间,并使用联合扩散Transformer进行生成建模,实现多任务统一训练。
- LaVin-DiT模型参数从0.1B扩展到3.4B,在多种视觉任务上取得了最先进的性能,展示了良好的可扩展性。
📝 摘要(中文)
本文提出了大型视觉扩散Transformer(LaVin-DiT),这是一个可扩展且统一的基础模型,旨在生成式框架中解决20多种计算机视觉任务。与直接从自然语言处理架构改编而来的现有大型视觉模型不同,这些模型依赖于效率较低的自回归技术并破坏了视觉数据必不可少的空间关系,LaVin-DiT引入了关键创新来优化视觉任务的生成性能。首先,为了解决视觉数据的高维度问题,我们结合了空间-时间变分自编码器,将数据编码到连续潜在空间中。其次,对于生成建模,我们开发了一种联合扩散Transformer,可以逐步生成视觉输出。第三,对于统一的多任务训练,实现了上下文学习。输入-目标对充当任务上下文,引导扩散Transformer在潜在空间内将输出与特定任务对齐。在推理过程中,任务特定的上下文集和作为查询的测试数据允许LaVin-DiT在无需微调的情况下跨任务泛化。该模型在广泛的视觉数据集上进行训练,规模从0.1B扩展到3.4B参数,展示了巨大的可扩展性和在各种视觉任务中的最先进性能。这项工作为大型视觉基础模型引入了一种新途径,强调了扩散Transformer的巨大潜力。代码和模型均已开源。
🔬 方法详解
问题定义:论文旨在解决现有大型视觉模型在处理多种视觉任务时存在的效率和空间关系保持问题。现有方法通常基于NLP的自回归模型,计算成本高,并且在生成过程中难以维持视觉数据的空间一致性。此外,如何有效地进行多任务学习也是一个挑战。
核心思路:LaVin-DiT的核心思路是利用扩散Transformer进行生成式建模,并结合空间-时间变分自编码器(VAE)将高维视觉数据映射到低维潜在空间。通过在潜在空间中进行扩散过程,可以更有效地生成高质量的视觉输出,同时保留重要的空间信息。此外,采用上下文学习的方式实现多任务统一训练,避免了为每个任务单独微调模型的需要。
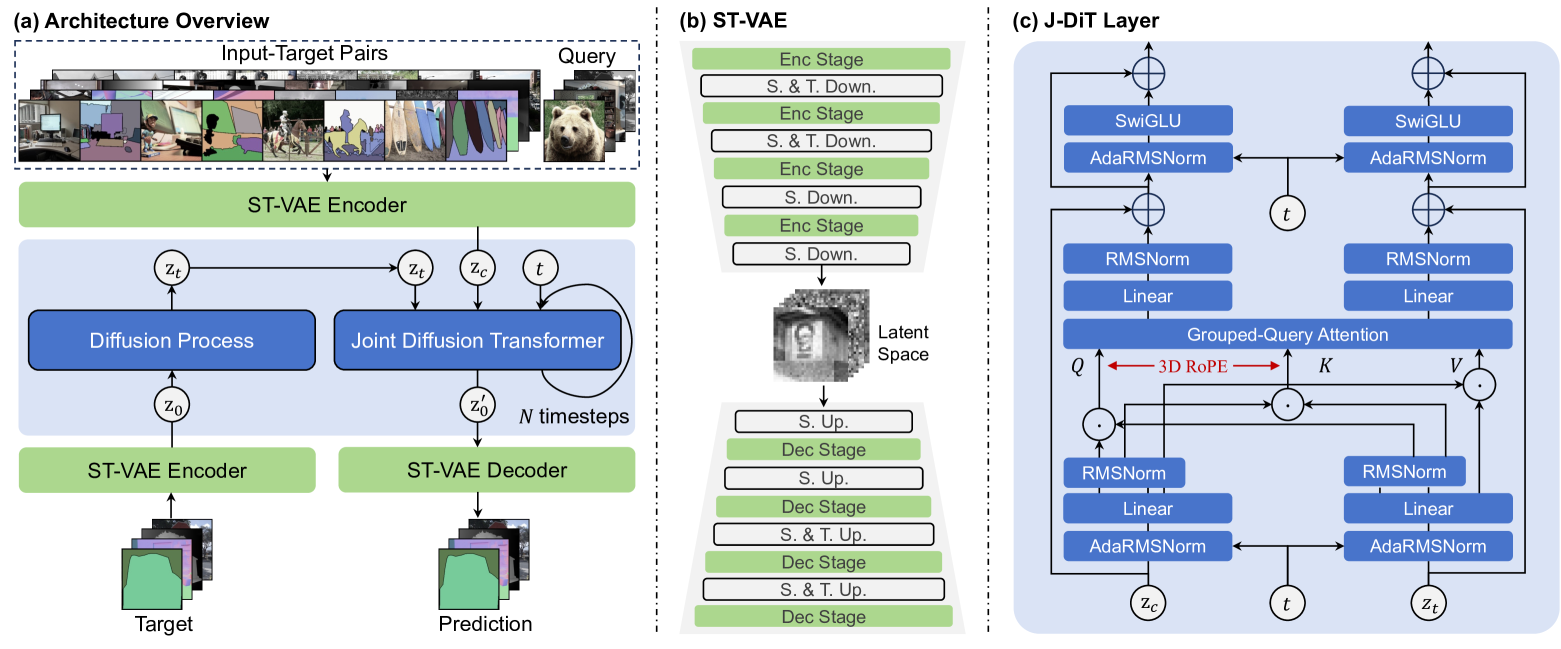
技术框架:LaVin-DiT的整体框架包括三个主要模块:空间-时间VAE、联合扩散Transformer和上下文学习模块。首先,VAE将输入图像编码到潜在空间。然后,扩散Transformer在潜在空间中逐步生成视觉输出。最后,上下文学习模块利用输入-目标对作为任务上下文,引导扩散Transformer生成与特定任务对齐的输出。在推理阶段,使用任务特定的上下文集和测试数据作为查询,实现跨任务泛化。
关键创新:LaVin-DiT的关键创新在于以下几点:1) 引入空间-时间VAE来处理高维视觉数据,降低计算复杂度并保留空间信息;2) 开发联合扩散Transformer进行生成建模,避免了自回归方法的局限性;3) 采用上下文学习实现多任务统一训练,提高了模型的泛化能力。与现有方法相比,LaVin-DiT在效率、空间关系保持和多任务学习方面都具有显著优势。
关键设计:空间-时间VAE的具体结构未知,但推测使用了卷积神经网络或Transformer结构进行编码和解码。联合扩散Transformer可能采用了U-Net结构或类似的架构,以逐步生成视觉输出。上下文学习模块的具体实现方式未知,但可能使用了注意力机制或类似的机制来提取任务上下文信息。损失函数可能包括VAE的重构损失、扩散模型的损失以及用于多任务学习的损失。
🖼️ 关键图片
📊 实验亮点
LaVin-DiT在多种视觉任务上取得了最先进的性能,例如图像生成、图像修复和图像分割。具体性能数据未知,但摘要强调了其在各种视觉任务中的卓越表现。模型规模从0.1B扩展到3.4B参数,展示了良好的可扩展性。通过上下文学习,LaVin-DiT能够无需微调即可泛化到新的任务,这表明其具有很强的泛化能力。
🎯 应用场景
LaVin-DiT作为一种通用的视觉基础模型,可以应用于图像生成、图像修复、图像分割、目标检测等多种计算机视觉任务。其潜在应用领域包括自动驾驶、医疗影像分析、智能安防、工业检测等。该研究的实际价值在于提供了一种高效且可扩展的视觉模型,可以降低开发成本并提高视觉任务的性能。未来,LaVin-DiT可以进一步扩展到处理视频数据,并与其他模态的数据进行融合,实现更强大的视觉智能。
📄 摘要(原文)
This paper presents the Large Vision Diffusion Transformer (LaVin-DiT), a scalable and unified foundation model designed to tackle over 20 computer vision tasks in a generative framework. Unlike existing large vision models directly adapted from natural language processing architectures, which rely on less efficient autoregressive techniques and disrupt spatial relationships essential for vision data, LaVin-DiT introduces key innovations to optimize generative performance for vision tasks. First, to address the high dimensionality of visual data, we incorporate a spatial-temporal variational autoencoder that encodes data into a continuous latent space. Second, for generative modeling, we develop a joint diffusion transformer that progressively produces vision outputs. Third, for unified multi-task training, in-context learning is implemented. Input-target pairs serve as task context, which guides the diffusion transformer to align outputs with specific tasks within the latent space. During inference, a task-specific context set and test data as queries allow LaVin-DiT to generalize across tasks without fine-tuning. Trained on extensive vision datasets, the model is scaled from 0.1B to 3.4B parameters, demonstrating substantial scalability and state-of-the-art performance across diverse vision tasks. This work introduces a novel pathway for large vision foundation models, underscoring the promising potential of diffusion transformers. The code and models are available.