MGNiceNet: Unified Monocular Geometric Scene Understanding
作者: Markus Schön, Michael Buchholz, Klaus Dietmayer
分类: cs.CV
发布日期: 2024-11-18 (更新: 2025-03-10)
期刊: Proceedings of the Asian Conference on Computer Vision (ACCV), 2024, pp. 1502-1519
DOI: 10.1007/978-981-96-0966-6_20
🔗 代码/项目: GITHUB
💡 一句话要点
MGNiceNet:面向自动驾驶的统一单目几何场景理解框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目视觉 几何场景理解 全景分割 自监督深度估计 自动驾驶 实时性 深度学习
📋 核心要点
- 现有单目几何场景理解方法难以兼顾实时性和精度,尤其是在自动驾驶等对实时性要求高的场景。
- MGNiceNet通过统一的框架,将全景分割和自监督深度估计紧密结合,利用全景信息辅助深度估计。
- 实验表明,MGNiceNet在Cityscapes和KITTI数据集上取得了优异的实时性能,缩小了与高计算复杂度方法的差距。
📝 摘要(中文)
本文提出MGNiceNet,一种统一的单目几何场景理解方法,集成了全景分割和自监督深度估计,专注于自动驾驶领域的实时应用。MGNiceNet基于先进的实时全景分割方法RT-K-Net,并扩展其架构以同时处理全景分割和自监督单目深度估计。为此,我们引入了一个紧耦合的自监督深度估计预测器,该预测器显式地利用来自全景路径的信息进行深度预测。此外,我们还引入了一种全景引导的运动掩码方法,以改进深度估计,而无需依赖视频全景分割标注。我们在两个流行的自动驾驶数据集Cityscapes和KITTI上评估了我们的方法。我们的模型与其他实时方法相比,显示出最先进的结果,并缩小了与计算量更大的方法之间的差距。源代码和训练好的模型可在https://github.com/markusschoen/MGNiceNet获取。
🔬 方法详解
问题定义:单目几何场景理解旨在从单张图像中同时获得场景的全景分割和深度信息。现有方法通常是独立地进行全景分割和深度估计,或者计算复杂度过高,难以满足自动驾驶等实时性要求高的场景需求。现有方法的痛点在于难以在精度和效率之间取得平衡。
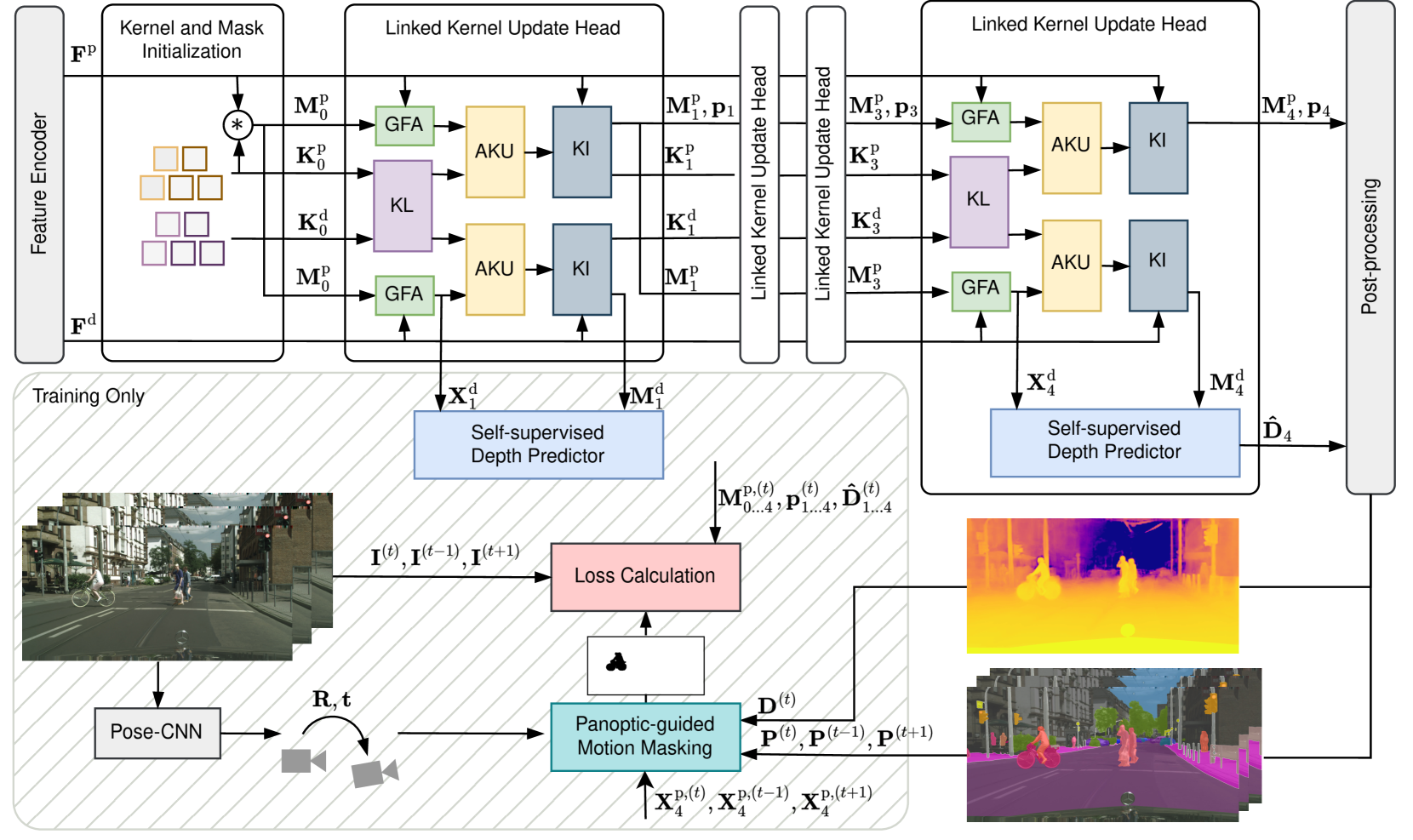
核心思路:MGNiceNet的核心思路是将全景分割和自监督深度估计紧密耦合,利用全景分割的结果来指导深度估计,从而提高深度估计的精度和鲁棒性。这种紧耦合的设计允许模型共享特征,并利用场景的语义信息来约束深度估计。
技术框架:MGNiceNet基于RT-K-Net架构,并对其进行了扩展。整体框架包含两个主要分支:全景分割分支和深度估计分支。全景分割分支负责预测图像的全景分割结果,深度估计分支负责预测图像的深度图。两个分支共享一部分特征提取网络,并通过一个紧耦合的模块进行信息交互。该框架还包含一个全景引导的运动掩码模块,用于过滤掉运动物体对深度估计的影响。
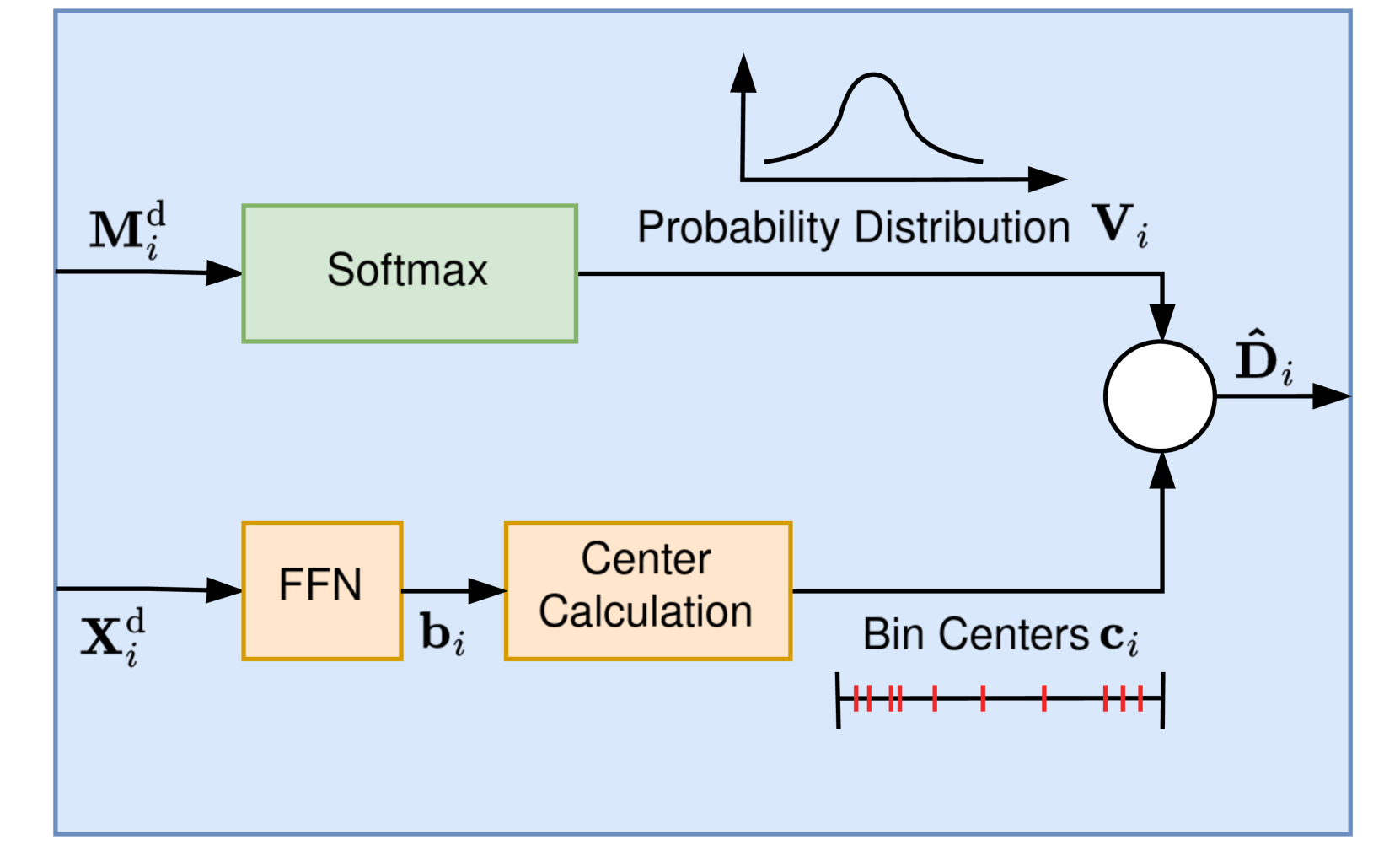
关键创新:MGNiceNet的关键创新在于:1) 提出了一个紧耦合的自监督深度估计预测器,该预测器显式地利用来自全景路径的信息进行深度预测;2) 引入了一种全景引导的运动掩码方法,以改进深度估计,而无需依赖视频全景分割标注。这种紧耦合和全景引导的设计使得MGNiceNet能够在实时性要求高的场景下实现高精度的单目几何场景理解。
关键设计:MGNiceNet的关键设计包括:1) 深度估计分支的损失函数采用了自监督深度估计常用的光度一致性损失和深度平滑损失;2) 全景引导的运动掩码模块利用全景分割的结果来识别图像中的运动物体,并将其从深度估计的损失计算中排除;3) 网络结构的设计充分考虑了实时性,采用了轻量级的卷积神经网络和高效的计算操作。
🖼️ 关键图片

📊 实验亮点
MGNiceNet在Cityscapes和KITTI数据集上取得了优异的性能。在Cityscapes数据集上,MGNiceNet在保持实时性的前提下,深度估计的精度接近甚至超过了一些计算复杂度更高的离线方法。在KITTI数据集上,MGNiceNet也取得了具有竞争力的结果,证明了其在不同场景下的泛化能力。与RT-K-Net相比,MGNiceNet在深度估计方面取得了显著的提升。
🎯 应用场景
MGNiceNet在自动驾驶领域具有广泛的应用前景,例如环境感知、路径规划和决策控制。它可以帮助自动驾驶车辆更好地理解周围环境,从而提高行驶的安全性和可靠性。此外,该方法还可以应用于机器人导航、增强现实等领域,为这些应用提供更准确和实时的场景理解能力。
📄 摘要(原文)
Monocular geometric scene understanding combines panoptic segmentation and self-supervised depth estimation, focusing on real-time application in autonomous vehicles. We introduce MGNiceNet, a unified approach that uses a linked kernel formulation for panoptic segmentation and self-supervised depth estimation. MGNiceNet is based on the state-of-the-art real-time panoptic segmentation method RT-K-Net and extends the architecture to cover both panoptic segmentation and self-supervised monocular depth estimation. To this end, we introduce a tightly coupled self-supervised depth estimation predictor that explicitly uses information from the panoptic path for depth prediction. Furthermore, we introduce a panoptic-guided motion masking method to improve depth estimation without relying on video panoptic segmentation annotations. We evaluate our method on two popular autonomous driving datasets, Cityscapes and KITTI. Our model shows state-of-the-art results compared to other real-time methods and closes the gap to computationally more demanding methods. Source code and trained models are available at https://github.com/markusschoen/MGNiceNet.