MAIRA-Seg: Enhancing Radiology Report Generation with Segmentation-Aware Multimodal Large Language Models
作者: Harshita Sharma, Valentina Salvatelli, Shaury Srivastav, Kenza Bouzid, Shruthi Bannur, Daniel C. Castro, Maximilian Ilse, Sam Bond-Taylor, Mercy Prasanna Ranjit, Fabian Falck, Fernando Pérez-García, Anton Schwaighofer, Hannah Richardson, Maria Teodora Wetscherek, Stephanie L. Hyland, Javier Alvarez-Valle
分类: cs.CV, cs.CL
发布日期: 2024-11-18
备注: Accepted as Proceedings Paper at ML4H 2024
💡 一句话要点
MAIRA-Seg:利用分割感知多模态大语言模型提升放射报告生成质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射报告生成 多模态大语言模型 语义分割 胸部X光片 医学影像 深度学习
📋 核心要点
- 现有放射报告生成模型缺乏对图像细粒度信息的有效利用,限制了报告的准确性和临床价值。
- MAIRA-Seg通过整合语义分割掩码,使模型能够关注图像中的特定结构,从而提升报告生成的质量。
- 实验结果表明,MAIRA-Seg在MIMIC-CXR数据集上优于非分割基线,证明了分割信息对报告生成的积极作用。
📝 摘要(中文)
本文研究了通过分割掩码整合像素级信息,是否能够提升多模态大语言模型(MLLM)在放射报告生成中对图像的细粒度理解能力,尤其是在胸部X光片(CXR)方面。我们提出了MAIRA-Seg,一个分割感知的MLLM框架,旨在利用语义分割掩码和CXR图像来生成放射报告。我们训练了专家分割模型,以获取CXR中放射结构对应的伪标签掩码。随后,在MAIRA(一个CXR报告生成专用模型)的架构基础上,我们集成了一个可训练的分割token提取器,该提取器利用这些掩码伪标签,并采用掩码感知的提示来生成放射报告草稿。在公开的MIMIC-CXR数据集上的实验表明,MAIRA-Seg优于非分割基线模型。我们还研究了MAIRA的集合标记提示方法,发现MAIRA-Seg始终表现出可比或更优越的性能。结果证实,使用分割掩码可以增强MLLM的细致推理能力,从而可能有助于改善临床结果。
🔬 方法详解
问题定义:放射报告生成旨在根据医学影像自动生成诊断报告。现有方法通常直接使用图像特征,忽略了图像中关键结构的像素级信息,导致模型难以进行细粒度的图像理解和推理,从而影响报告的准确性和完整性。
核心思路:论文的核心思路是将语义分割信息融入到多模态大语言模型中,使模型能够关注图像中的特定区域和结构。通过利用分割掩码,模型可以更好地理解图像内容,从而生成更准确、更详细的放射报告。这种方法旨在弥合图像特征和文本描述之间的语义鸿沟。
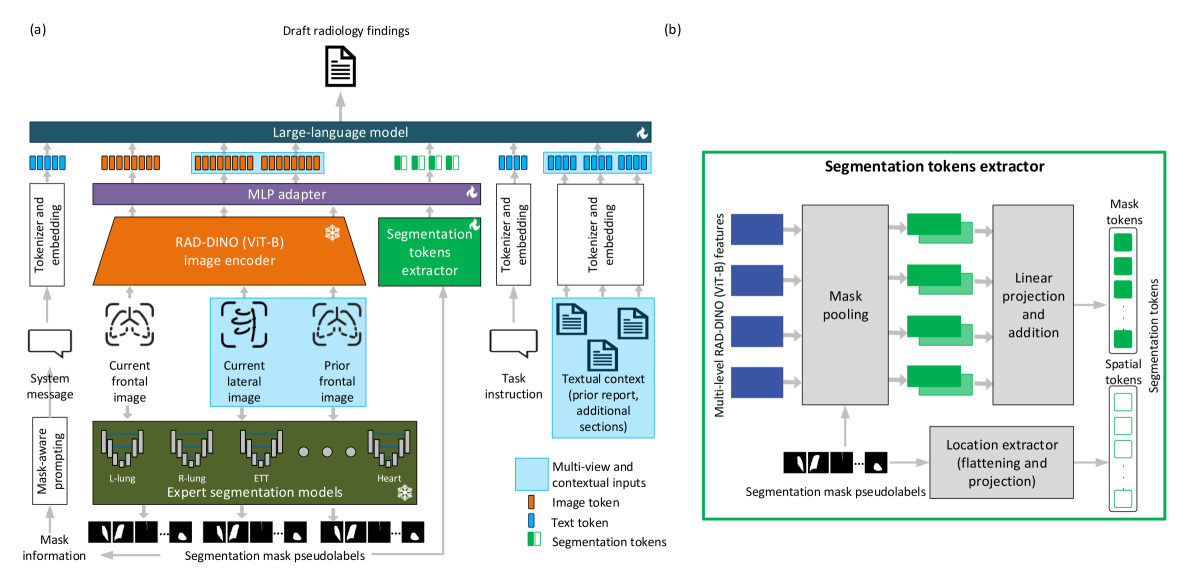
技术框架:MAIRA-Seg框架主要包含以下几个模块:1) 专家分割模型:用于生成胸部X光片中放射结构的伪标签掩码。2) 分割token提取器:一个可训练的模块,用于从分割掩码中提取特征表示。3) 多模态大语言模型(MLLM):基于MAIRA架构,将图像特征和分割token融合,并生成放射报告。4) 掩码感知提示:利用分割信息引导MLLM生成更准确的报告。整体流程是先利用分割模型生成掩码,然后通过分割token提取器提取特征,最后将特征输入到MLLM中生成报告。
关键创新:该论文的关键创新在于将语义分割信息显式地融入到多模态大语言模型中,从而提升了模型对图像的细粒度理解能力。与现有方法相比,MAIRA-Seg能够更好地利用图像中的结构信息,生成更准确、更详细的放射报告。此外,可训练的分割token提取器也是一个创新点,它能够自适应地学习分割掩码的有效表示。
关键设计:论文的关键设计包括:1) 使用专家分割模型生成高质量的伪标签掩码。2) 设计可训练的分割token提取器,使其能够有效地提取分割掩码的特征。3) 采用掩码感知提示,引导MLLM生成更准确的报告。具体来说,分割token提取器可能包含卷积神经网络或Transformer结构,用于将分割掩码转换为向量表示。损失函数可能包括交叉熵损失或对比学习损失,用于训练分割token提取器和MLLM。
🖼️ 关键图片


📊 实验亮点
MAIRA-Seg在MIMIC-CXR数据集上的实验结果表明,其性能优于非分割基线模型,证明了分割信息对放射报告生成的有效性。此外,MAIRA-Seg在集合标记提示方法下也表现出可比或更优越的性能,进一步验证了该方法的鲁棒性和泛化能力。具体性能提升数据未知,但结论是优于基线。
🎯 应用场景
MAIRA-Seg在放射报告生成领域具有广泛的应用前景,可以辅助放射科医生进行诊断,提高诊断效率和准确性,减少人为误差。该技术还可以应用于医学影像教学和研究,帮助学生和研究人员更好地理解医学影像。未来,该技术有望推广到其他医学影像类型和疾病诊断领域。
📄 摘要(原文)
There is growing interest in applying AI to radiology report generation, particularly for chest X-rays (CXRs). This paper investigates whether incorporating pixel-level information through segmentation masks can improve fine-grained image interpretation of multimodal large language models (MLLMs) for radiology report generation. We introduce MAIRA-Seg, a segmentation-aware MLLM framework designed to utilize semantic segmentation masks alongside CXRs for generating radiology reports. We train expert segmentation models to obtain mask pseudolabels for radiology-specific structures in CXRs. Subsequently, building on the architectures of MAIRA, a CXR-specialised model for report generation, we integrate a trainable segmentation tokens extractor that leverages these mask pseudolabels, and employ mask-aware prompting to generate draft radiology reports. Our experiments on the publicly available MIMIC-CXR dataset show that MAIRA-Seg outperforms non-segmentation baselines. We also investigate set-of-marks prompting with MAIRA and find that MAIRA-Seg consistently demonstrates comparable or superior performance. The results confirm that using segmentation masks enhances the nuanced reasoning of MLLMs, potentially contributing to better clinical outcomes.