CCExpert: Advancing MLLM Capability in Remote Sensing Change Captioning with Difference-Aware Integration and a Foundational Dataset
作者: Zhiming Wang, Mingze Wang, Sheng Xu, Yanjing Li, Baochang Zhang
分类: cs.CV
发布日期: 2024-11-18
🔗 代码/项目: GITHUB
💡 一句话要点
CCExpert:通过差异感知集成和基础数据集提升MLLM在遥感变化描述中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像变化描述 多模态大语言模型 差异感知 多尺度特征 数据集构建
📋 核心要点
- 现有遥感图像变化描述方法缺乏数据支持,易改变MLLM特征传输路径,限制其性能。
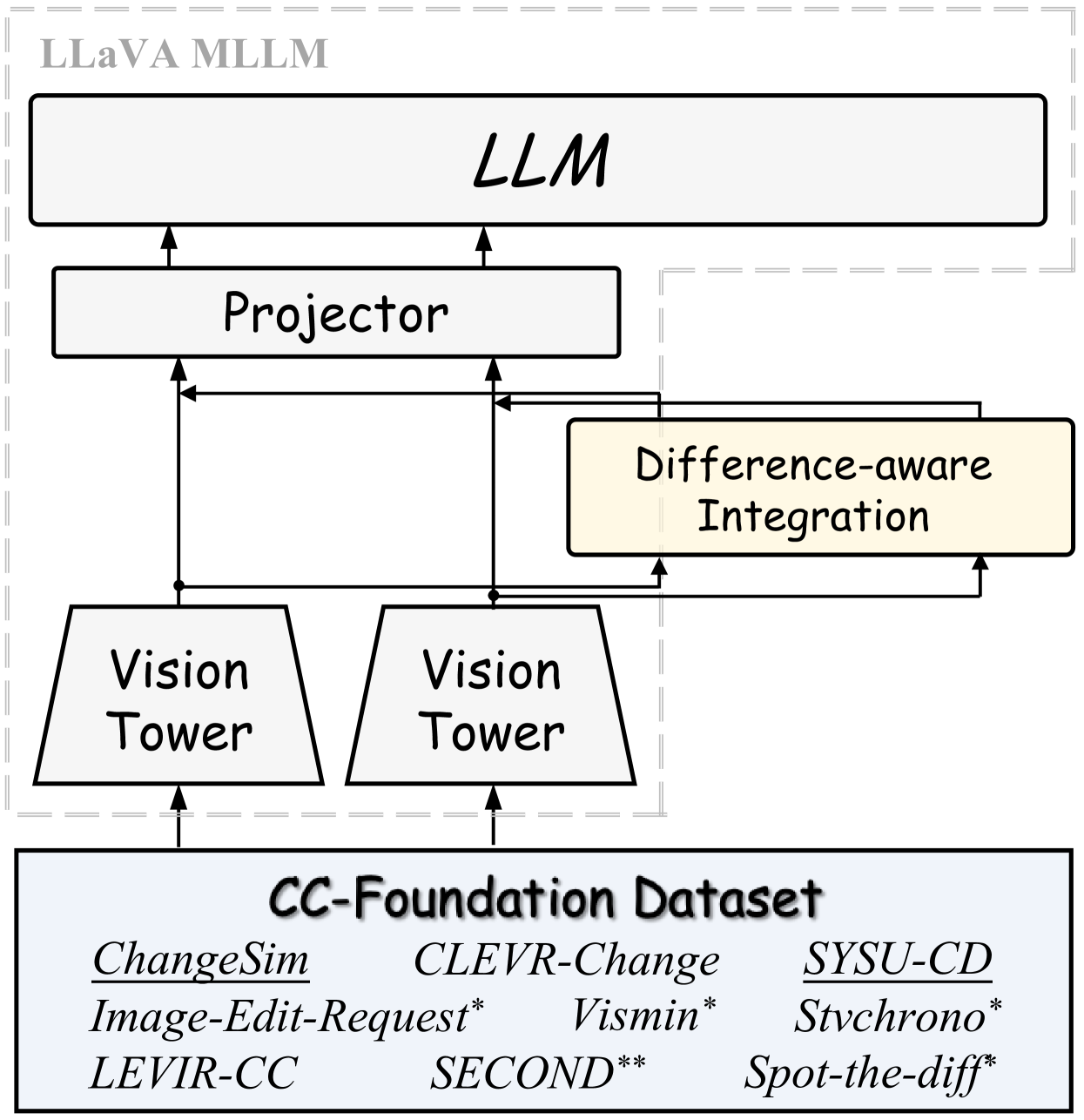
- CCExpert通过差异感知集成模块增强差异特征,并构建大规模数据集CC-Foundation进行预训练。
- CCExpert在LEVIR-CC上取得S*_m=81.80的显著性能,超越现有方法,证明了其有效性。
📝 摘要(中文)
遥感图像变化描述(RSICC)旨在生成自然语言描述,用于描述多时相遥感图像之间的地表变化,详细说明变化对象的类别、位置和动态(例如,新增或消失)。目前许多方法试图利用多模态大型语言模型(MLLM)的长序列理解和推理能力来完成这项任务。然而,在缺乏全面数据支持的情况下,这些方法通常会改变MLLM的基本特征传输路径,扰乱模型内部的固有知识,并限制其在RSICC中的潜力。本文提出了一个基于新型先进多模态大型模型框架的模型CCExpert。首先,我们设计了一个差异感知集成模块,以捕获双时相图像之间的多尺度差异,并将其整合到原始图像上下文中,从而提高差异特征的信噪比。其次,我们构建了一个高质量、多样化的数据集CC-Foundation,包含20万个图像对和120万个描述,为该领域的持续预训练提供大量数据支持。最后,我们采用了一个三阶段渐进式训练过程,以确保差异感知集成模块与预训练的MLLM的深度集成。CCExpert在LEVIR-CC基准测试中取得了显著的性能,S*_m=81.80,显著超过了以前的最先进方法。代码和部分数据集即将开源。
🔬 方法详解
问题定义:遥感图像变化描述(RSICC)旨在根据多时相遥感图像生成自然语言描述,精确描述地表变化,包括变化类型、位置和动态。现有方法依赖MLLM,但缺乏针对RSICC的数据支持,容易破坏MLLM的固有知识,限制其在该任务上的表现。
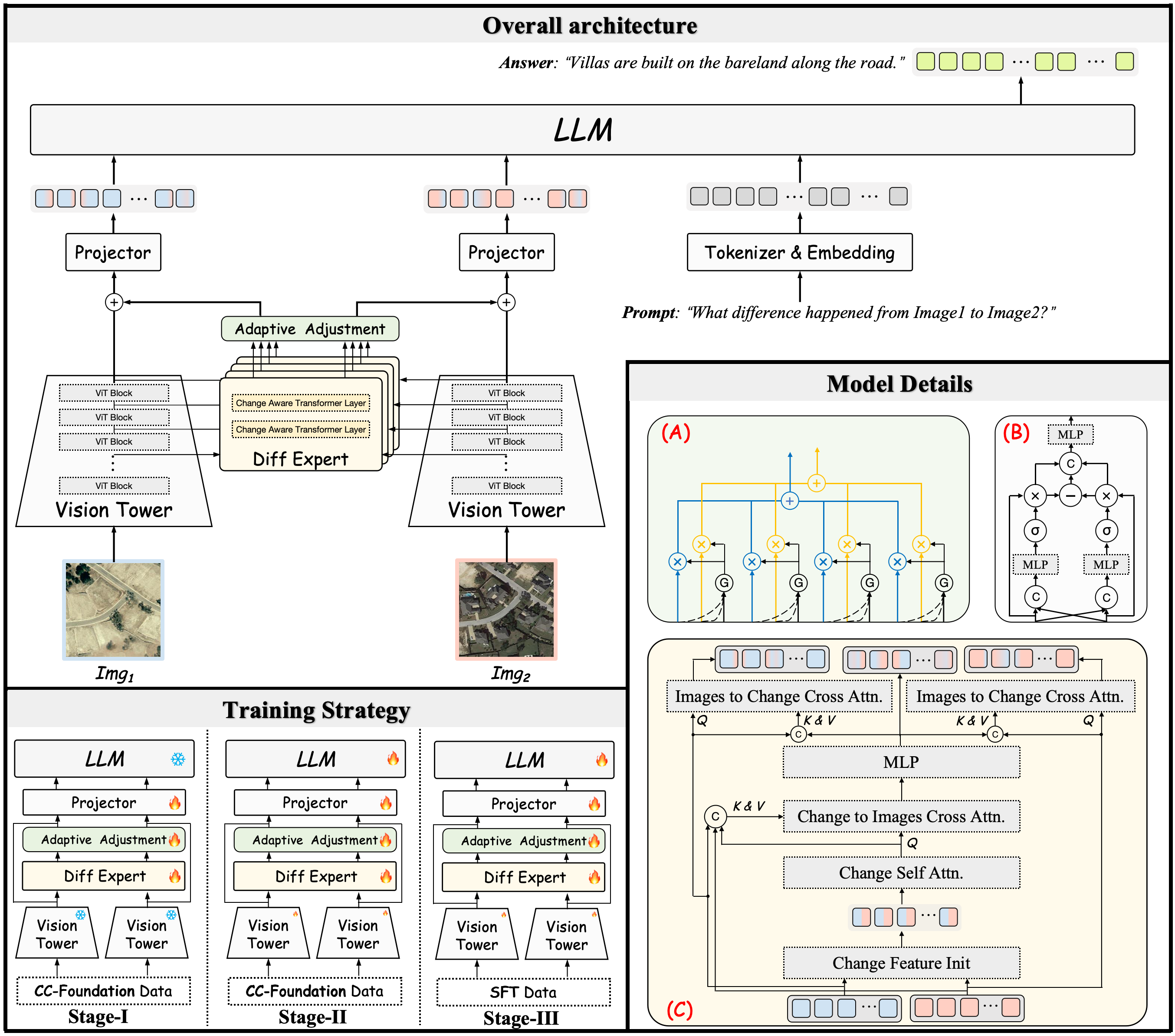
核心思路:CCExpert的核心思路是增强MLLM对遥感图像差异的感知能力,并提供充足的数据支持。通过差异感知集成模块提取多尺度差异特征,提高差异特征的信噪比。同时,构建大规模数据集CC-Foundation,为MLLM的预训练提供数据基础。
技术框架:CCExpert包含三个主要模块:差异感知集成模块、预训练的MLLM和三阶段渐进式训练流程。差异感知集成模块负责提取双时相图像的差异特征,并将其融入原始图像上下文。预训练的MLLM作为基础模型,负责生成自然语言描述。三阶段渐进式训练流程确保差异感知集成模块与MLLM的深度融合。
关键创新:CCExpert的关键创新在于差异感知集成模块和CC-Foundation数据集。差异感知集成模块能够有效提取多尺度差异特征,提高差异特征的信噪比,从而提升MLLM对变化的感知能力。CC-Foundation数据集为RSICC任务提供了大规模、高质量的数据支持,解决了现有方法缺乏数据的问题。
关键设计:差异感知集成模块采用多尺度卷积和注意力机制,提取不同尺度的差异特征。CC-Foundation数据集包含20万个图像对和120万个描述,覆盖了多种地表变化类型。三阶段渐进式训练流程包括:第一阶段,预训练差异感知集成模块;第二阶段,将差异感知集成模块与MLLM进行初步融合;第三阶段,对整个模型进行微调。
🖼️ 关键图片

📊 实验亮点
CCExpert在LEVIR-CC基准测试中取得了S*_m=81.80的显著性能,相比之前的SOTA方法有显著提升。这一结果表明,CCExpert提出的差异感知集成模块和CC-Foundation数据集能够有效提升MLLM在遥感图像变化描述任务中的性能。
🎯 应用场景
CCExpert可应用于城市规划、灾害监测、环境评估等领域。通过自动生成地表变化描述,能够帮助用户快速了解地表变化情况,为决策提供支持。未来,该技术可进一步应用于自动驾驶、智能农业等领域,实现更广泛的应用。
📄 摘要(原文)
Remote Sensing Image Change Captioning (RSICC) aims to generate natural language descriptions of surface changes between multi-temporal remote sensing images, detailing the categories, locations, and dynamics of changed objects (e.g., additions or disappearances). Many current methods attempt to leverage the long-sequence understanding and reasoning capabilities of multimodal large language models (MLLMs) for this task. However, without comprehensive data support, these approaches often alter the essential feature transmission pathways of MLLMs, disrupting the intrinsic knowledge within the models and limiting their potential in RSICC. In this paper, we propose a novel model, CCExpert, based on a new, advanced multimodal large model framework. Firstly, we design a difference-aware integration module to capture multi-scale differences between bi-temporal images and incorporate them into the original image context, thereby enhancing the signal-to-noise ratio of differential features. Secondly, we constructed a high-quality, diversified dataset called CC-Foundation, containing 200,000 image pairs and 1.2 million captions, to provide substantial data support for continue pretraining in this domain. Lastly, we employed a three-stage progressive training process to ensure the deep integration of the difference-aware integration module with the pretrained MLLM. CCExpert achieved a notable performance of $S^*_m=81.80$ on the LEVIR-CC benchmark, significantly surpassing previous state-of-the-art methods. The code and part of the dataset will soon be open-sourced at https://github.com/Meize0729/CCExpert.