Latent Knowledge-Guided Video Diffusion for Scientific Phenomena Generation from a Single Initial Frame
作者: Qinglong Cao, Xirui Li, Ding Wang, Chao Ma, Yuntian Chen, Xiaokang Yang
分类: cs.CV, stat.AP
发布日期: 2024-11-18 (更新: 2025-11-13)
💡 一句话要点
提出基于潜在知识引导的视频扩散模型,用于从单帧生成科学现象视频
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频扩散模型 科学现象生成 潜在知识提取 CLIP模型 伪语言提示
📋 核心要点
- 现有视频扩散模型难以泛化到受科学规律约束的科学现象生成,面临领域差距大、数据少、缺乏标注等挑战。
- 该论文提出一种新框架,通过提取静态和动态的潜在科学知识,引导视频扩散模型从单帧生成科学现象视频。
- 实验表明,该方法在流体模拟和台风观测等场景中,生成视频的保真度和一致性优于现有方法。
📝 摘要(中文)
视频扩散模型在自然场景生成方面取得了显著成果,但难以推广到流体模拟和气象过程等受科学规律支配的科学现象。这些任务面临着独特的挑战,包括严重的领域差距、有限的训练数据以及缺乏描述性语言标注。为了解决这一难题,我们提取了潜在的科学现象知识,并提出了一个新框架,该框架教导视频扩散模型从单个初始帧生成科学现象。具体而言,静态知识通过预训练的掩码自编码器提取,而动态知识则来自预训练的光流预测。随后,基于CLIP视觉和语言编码器之间对齐的空间关系,在潜在科学现象知识的指导下,科学现象的视觉嵌入被投影以在空间和频域中生成伪语言提示嵌入。通过结合这些提示并微调视频扩散模型,我们能够生成更好地遵守科学规律的视频。在计算流体动力学模拟和真实台风观测的大量实验表明了我们方法的有效性,在各种科学场景中实现了卓越的保真度和一致性。
🔬 方法详解
问题定义:现有视频扩散模型在生成自然场景视频方面表现出色,但在生成科学现象视频时面临挑战。科学现象视频通常需要遵循特定的物理规律,例如流体动力学或气象学定律。由于训练数据有限、领域差异大以及缺乏描述性语言标注,现有模型难以准确捕捉和模拟这些规律,导致生成结果不真实或不一致。
核心思路:该论文的核心思路是利用预训练模型提取科学现象的潜在知识,并将其作为指导信息融入到视频扩散模型的训练过程中。通过这种方式,模型可以学习到科学现象的内在规律,从而生成更符合物理规律的视频。核心在于将视觉信息转化为伪语言提示,利用CLIP模型对齐视觉和语言特征的能力。
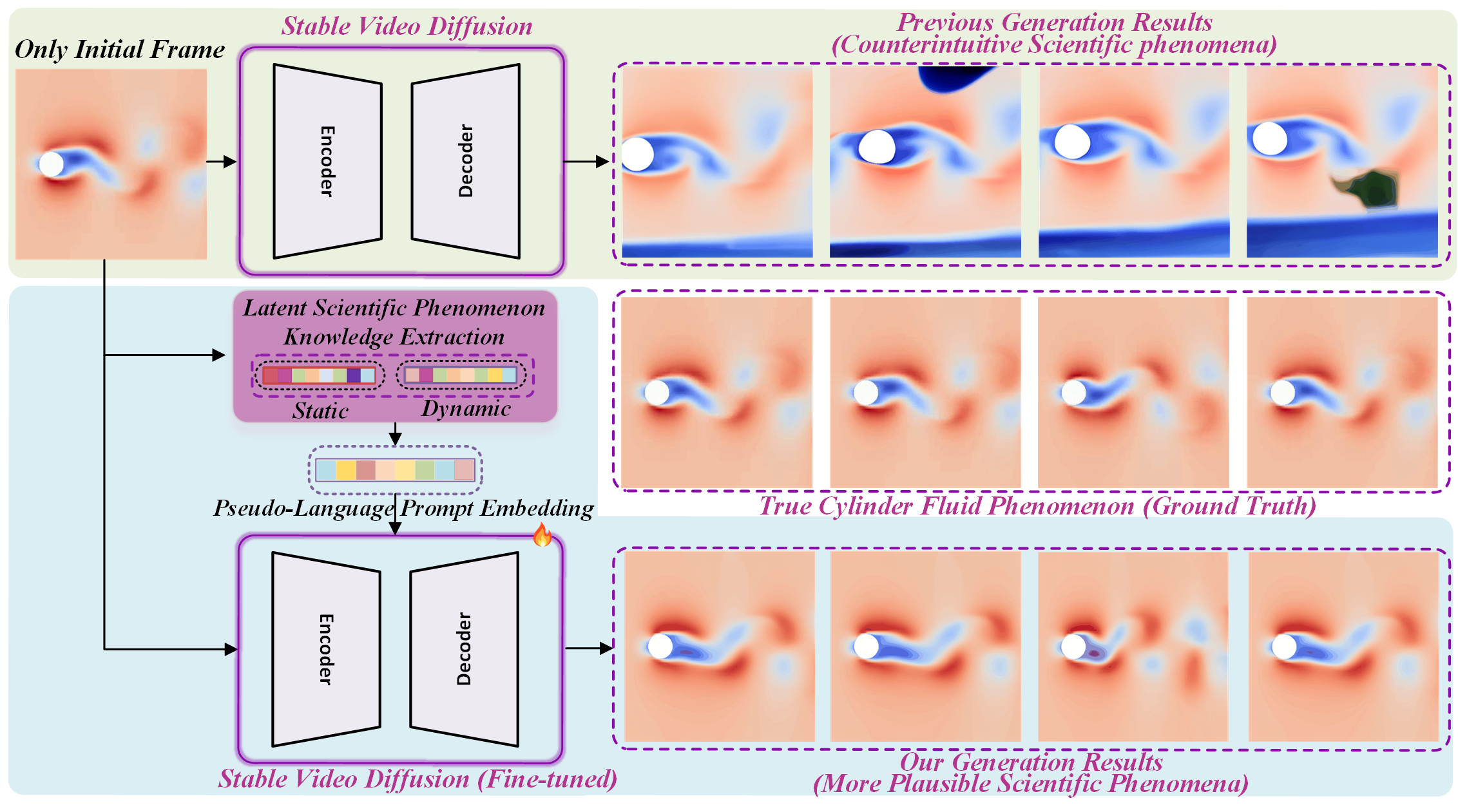
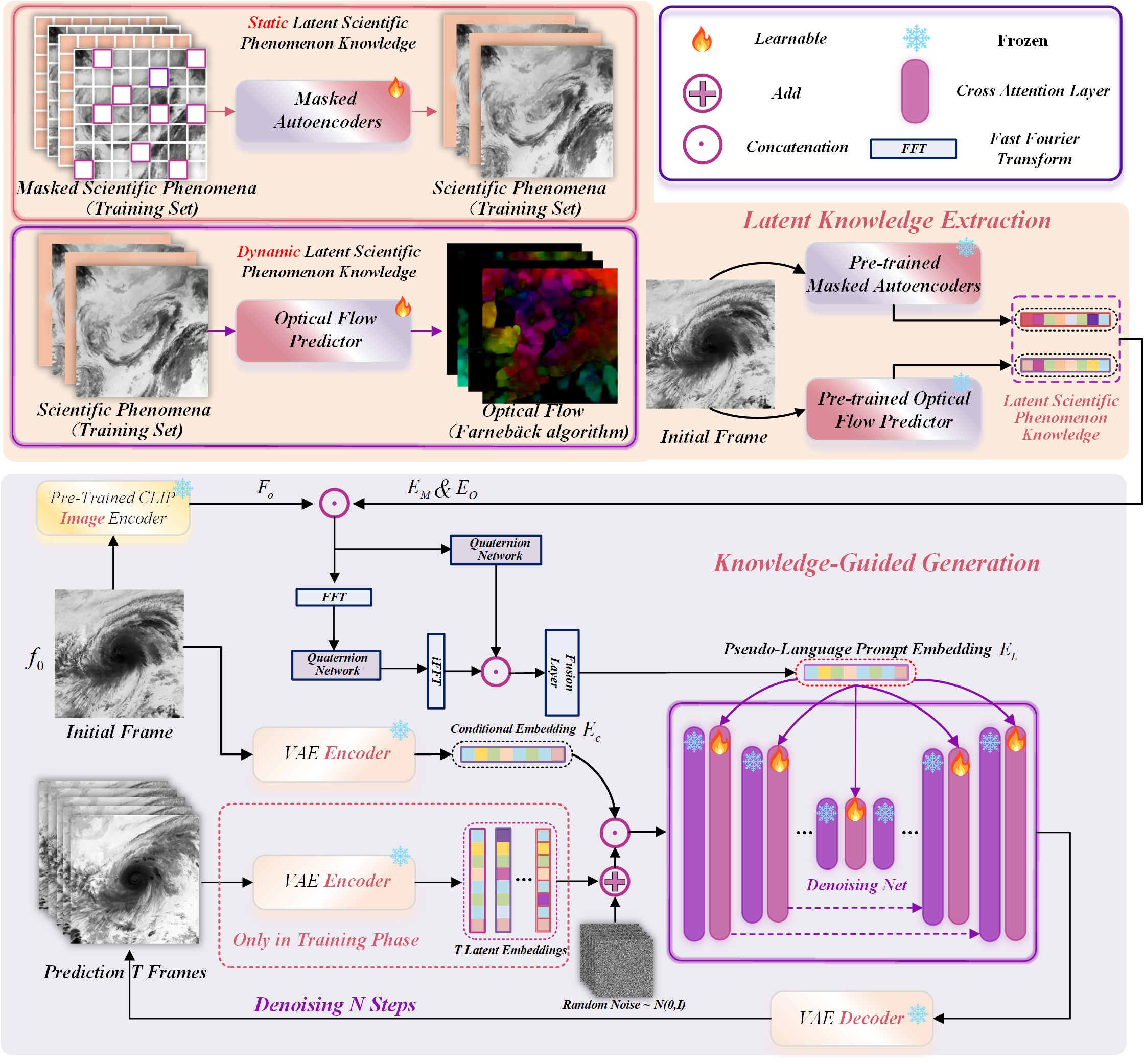
技术框架:该框架主要包含以下几个模块:1) 静态知识提取:使用预训练的掩码自编码器(MAE)从初始帧中提取静态视觉特征。2) 动态知识提取:使用预训练的光流预测模型提取视频中的动态信息。3) 伪语言提示生成:基于CLIP模型,将提取的静态和动态知识投影到语言嵌入空间,生成伪语言提示。4) 视频扩散模型微调:将生成的伪语言提示作为条件,微调视频扩散模型,使其能够生成符合科学规律的视频。
关键创新:该论文的关键创新在于将预训练模型提取的潜在科学知识融入到视频扩散模型的训练过程中。通过将视觉信息转化为伪语言提示,并利用CLIP模型对齐视觉和语言特征的能力,该方法能够有效地指导模型学习科学现象的内在规律。此外,该方法还解决了科学现象视频生成中数据有限和缺乏标注的问题。
关键设计:在静态知识提取方面,使用了预训练的MAE模型,该模型能够有效地捕捉图像的全局结构信息。在动态知识提取方面,使用了预训练的光流预测模型,该模型能够准确地估计视频中物体的运动轨迹。在伪语言提示生成方面,使用了CLIP模型,该模型能够将视觉特征映射到语言嵌入空间,从而生成具有语义信息的提示。在视频扩散模型微调方面,使用了标准的扩散模型架构,并采用了一种条件生成的方式,将伪语言提示作为条件输入到模型中。
🖼️ 关键图片

📊 实验亮点
该论文在计算流体动力学模拟和真实台风观测两个数据集上进行了实验。实验结果表明,该方法生成的视频在保真度和一致性方面均优于现有方法。例如,在流体模拟任务中,该方法能够生成更真实的漩涡和湍流效果。在台风观测任务中,该方法能够更准确地预测台风的路径和强度变化。具体性能提升数据未知,但论文强调了在多个科学场景下的卓越表现。
🎯 应用场景
该研究成果可应用于计算流体动力学、气象学、材料科学等领域,用于生成各种科学现象的模拟视频。例如,可以用于模拟流体在不同条件下的流动情况,预测台风的路径和强度变化,或者模拟材料在不同应力下的形变过程。该技术有助于科研人员更直观地理解和分析科学现象,加速科学研究的进程。
📄 摘要(原文)
Video diffusion models have achieved impressive results in natural scene generation, yet they struggle to generalize to scientific phenomena such as fluid simulations and meteorological processes, where underlying dynamics are governed by scientific laws. These tasks pose unique challenges, including severe domain gaps, limited training data, and the lack of descriptive language annotations. To handle this dilemma, we extracted the latent scientific phenomena knowledge and further proposed a fresh framework that teaches video diffusion models to generate scientific phenomena from a single initial frame. Particularly, static knowledge is extracted via pre-trained masked autoencoders, while dynamic knowledge is derived from pre-trained optical flow prediction. Subsequently, based on the aligned spatial relations between the CLIP vision and language encoders, the visual embeddings of scientific phenomena, guided by latent scientific phenomena knowledge, are projected to generate the pseudo-language prompt embeddings in both spatial and frequency domains. By incorporating these prompts and fine-tuning the video diffusion model, we enable the generation of videos that better adhere to scientific laws. Extensive experiments on both computational fluid dynamics simulations and real-world typhoon observations demonstrate the effectiveness of our approach, achieving superior fidelity and consistency across diverse scientific scenarios.