Explanation for Trajectory Planning using Multi-modal Large Language Model for Autonomous Driving
作者: Shota Yamazaki, Chenyu Zhang, Takuya Nanri, Akio Shigekane, Siyuan Wang, Jo Nishiyama, Tao Chu, Kohei Yokosawa
分类: cs.CV, cs.RO
发布日期: 2024-11-15
备注: Accepted and presented at ECCV 2024 2nd Workshop on Vision-Centric Autonomous Driving (VCAD) on September 30, 2024. 13 pages, 5 figures
💡 一句话要点
提出基于多模态大语言模型的轨迹规划解释方法,提升自动驾驶决策透明度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 轨迹规划 可解释性 大语言模型 多模态学习
📋 核心要点
- 端到端自动驾驶模型缺乏决策过程的可解释性,导致乘客对其信任度较低。
- 该论文提出一种新的推理模型,以车辆的未来规划轨迹作为输入,生成描述车辆行为及其原因的文本。
- 通过新收集的数据集进行训练,该模型能够更准确地反映车辆的未来规划,提升解释的质量。
📝 摘要(中文)
本文提出了一种新的自动驾驶轨迹规划解释模型,旨在解决端到端自动驾驶模型决策过程缺乏可解释性的问题。现有方法通常使用瞬时控制信号作为输入来生成解释文本,导致生成的解释未能充分反映车辆的未来规划。为了克服这一局限性,本文提出的模型以车辆的未来规划轨迹作为输入,并为此收集了一个新的数据集。该模型能够生成更准确地描述车辆未来行为及其原因的解释。
🔬 方法详解
问题定义:端到端自动驾驶模型虽然性能优异,但其决策过程如同黑盒,缺乏可解释性。现有方法尝试生成解释文本,但通常以瞬时控制信号作为输入,无法准确反映车辆的未来规划,导致生成的解释与实际行为不符,难以提升乘客的信任感。
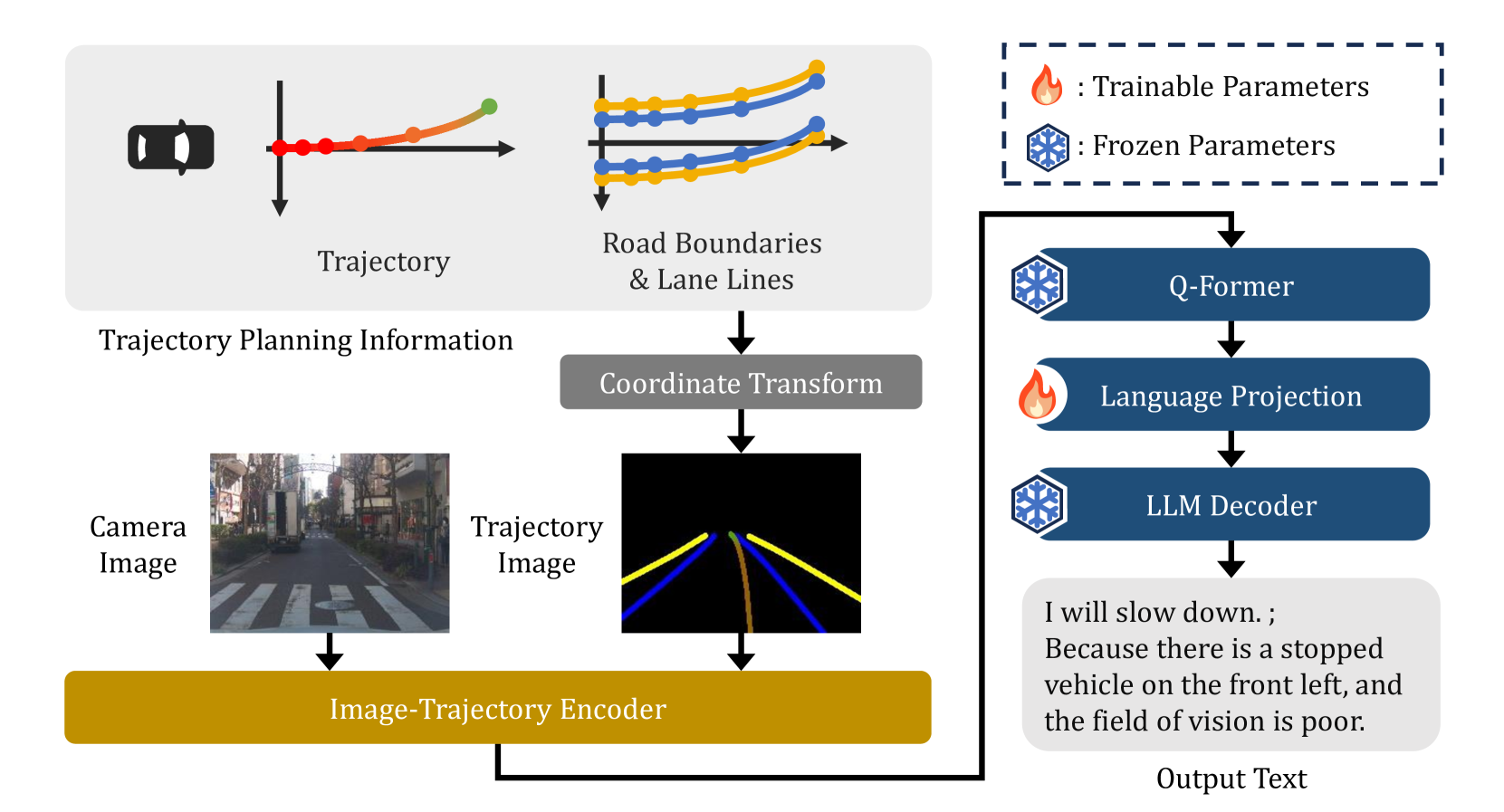
核心思路:论文的核心思路是将车辆的未来规划轨迹作为输入,让模型直接学习轨迹与解释之间的关系。通过预测未来轨迹,模型能够更好地理解车辆的意图,从而生成更准确、更全面的解释文本。这种方法避免了仅依赖瞬时控制信号的局限性。
技术框架:该模型采用多模态大语言模型作为核心架构,输入包括车辆的未来规划轨迹和其他相关信息(例如,交通规则、周围环境信息等)。模型首先对输入信息进行编码,然后利用大语言模型生成描述车辆未来行为及其原因的解释文本。整体流程包括数据收集、模型训练和推理三个阶段。
关键创新:该论文的关键创新在于将未来轨迹规划作为解释模型的输入,从而克服了现有方法仅依赖瞬时控制信号的局限性。此外,论文还构建了一个新的数据集,用于训练和评估该模型。这种方法能够更准确地反映车辆的未来规划,提升了解释的质量和可信度。
关键设计:论文中涉及的关键设计包括:(1) 如何有效地编码未来轨迹信息,使其能够被大语言模型理解和利用;(2) 如何设计损失函数,以鼓励模型生成更准确、更全面的解释文本;(3) 如何选择合适的大语言模型,并对其进行微调,以适应自动驾驶场景的需求。具体参数设置和网络结构等细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
由于摘要中没有明确提及实验结果,因此无法总结实验亮点。具体性能数据、对比基线和提升幅度等信息未知。需要查阅论文全文才能进行更详细的总结。
🎯 应用场景
该研究成果可应用于提升自动驾驶系统的透明度和可信度,增强乘客对自动驾驶车辆的信任感。此外,该技术还可用于自动驾驶系统的调试和验证,帮助开发人员更好地理解和改进自动驾驶算法。未来,该技术有望应用于自动驾驶出租车、物流配送等领域。
📄 摘要(原文)
End-to-end style autonomous driving models have been developed recently. These models lack interpretability of decision-making process from perception to control of the ego vehicle, resulting in anxiety for passengers. To alleviate it, it is effective to build a model which outputs captions describing future behaviors of the ego vehicle and their reason. However, the existing approaches generate reasoning text that inadequately reflects the future plans of the ego vehicle, because they train models to output captions using momentary control signals as inputs. In this study, we propose a reasoning model that takes future planning trajectories of the ego vehicle as inputs to solve this limitation with the dataset newly collected.