Architect: Generating Vivid and Interactive 3D Scenes with Hierarchical 2D Inpainting
作者: Yian Wang, Xiaowen Qiu, Jiageng Liu, Zhehuan Chen, Jiting Cai, Yufei Wang, Tsun-Hsuan Wang, Zhou Xian, Chuang Gan
分类: cs.CV
发布日期: 2024-11-14
💡 一句话要点
Architect:利用分层2D图像修复生成生动交互式3D场景
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景生成 图像修复 扩散模型 具身智能 深度估计
📋 核心要点
- 现有3D场景生成方法存在人工成本高、依赖预定义规则和3D空间推理能力有限等问题。
- Architect框架利用2D图像修复生成3D场景,通过视觉感知模型提取对象,深度估计模型提升至3D空间。
- 该方法采用分层迭代修复流程,可从文本、平面图等多种起点生成或优化场景,具有灵活性。
📝 摘要(中文)
创建大规模交互式3D环境对于机器人和具身人工智能的研究至关重要。目前的方法,包括手动设计、程序生成、基于扩散的场景生成以及大型语言模型(LLM)引导的场景设计,都受到过度的人工投入、依赖于预定义的规则或训练数据集以及有限的3D空间推理能力等限制。由于预训练的2D图像生成模型比LLM更好地捕捉场景和对象配置,我们通过引入Architect来解决这些挑战,Architect是一个生成框架,它利用基于扩散的2D图像修复来创建复杂而逼真的3D具身环境。具体来说,我们利用基础视觉感知模型从图像中获得每个生成的对象,并利用预训练的深度估计模型将生成的2D图像提升到3D空间。我们的流程进一步扩展到分层和迭代的修复过程,以不断生成大型家具和小型对象的放置,从而丰富场景。这种迭代结构为我们的方法带来了灵活性,可以从各种起点(例如文本、平面图或预先安排的环境)生成或改进场景。
🔬 方法详解
问题定义:论文旨在解决大规模交互式3D环境生成的问题。现有方法,如手动设计、程序生成、基于扩散的场景生成以及LLM引导的场景设计,存在人工成本高昂、依赖预定义规则或训练数据、以及3D空间推理能力不足等痛点。这些限制阻碍了机器人和具身智能研究的发展。
核心思路:论文的核心思路是利用预训练的2D图像生成模型,特别是基于扩散的图像修复模型,来生成3D场景。作者认为,相比于LLM,2D图像生成模型在捕捉场景和对象配置方面表现更好。通过将2D图像提升到3D空间,并采用分层迭代的修复过程,可以生成更复杂和逼真的3D环境。
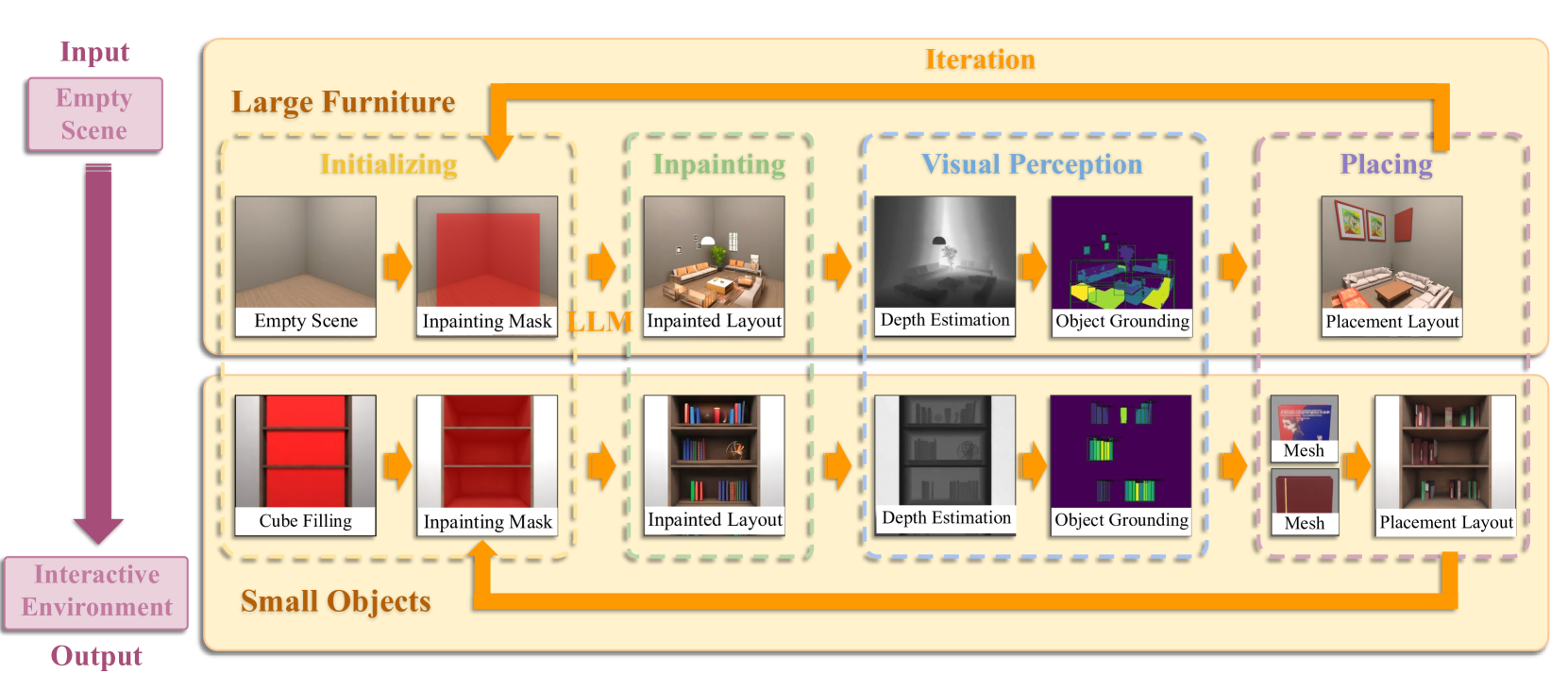
技术框架:Architect框架主要包含以下几个阶段:1) 利用基础视觉感知模型从图像中提取对象;2) 利用预训练的深度估计模型将2D图像提升到3D空间;3) 采用分层迭代的修复过程,首先生成大型家具的布局,然后逐步添加小型对象,以丰富场景。该框架支持从多种起点(如文本、平面图或预先安排的环境)生成或改进场景。
关键创新:该方法最重要的创新点在于将2D图像修复技术应用于3D场景生成,并结合分层迭代的生成策略。与传统的3D场景生成方法相比,该方法能够更好地利用预训练的2D图像生成模型的优势,从而生成更逼真、更复杂的3D环境。此外,该方法还具有更高的灵活性,可以从多种起点生成或改进场景。
关键设计:论文中关键的设计包括:1) 使用预训练的视觉感知模型(具体模型未知)进行对象提取;2) 使用预训练的深度估计模型(具体模型未知)进行2D到3D的转换;3) 设计分层迭代的修复流程,具体的分层策略和迭代次数未知;4) 如何将文本、平面图等信息融入到图像修复过程中,具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
论文提出了一个新颖的3D场景生成框架Architect,该框架利用2D图像修复技术生成高质量的3D场景。虽然论文摘要中没有提供具体的性能数据,但强调了该方法能够生成复杂和逼真的3D环境,并且具有从多种起点生成或改进场景的灵活性。与现有方法相比,Architect在3D空间推理和场景复杂度方面具有潜在的优势。(具体实验数据未知)
🎯 应用场景
该研究成果可广泛应用于机器人、具身智能、虚拟现实、游戏开发等领域。例如,可以用于创建逼真的虚拟训练环境,帮助机器人学习如何在复杂环境中导航和操作。此外,还可以用于游戏开发,快速生成各种风格的3D场景,提高游戏开发的效率和质量。未来,该技术有望进一步发展,实现更加智能和自动化的3D场景生成。
📄 摘要(原文)
Creating large-scale interactive 3D environments is essential for the development of Robotics and Embodied AI research. Current methods, including manual design, procedural generation, diffusion-based scene generation, and large language model (LLM) guided scene design, are hindered by limitations such as excessive human effort, reliance on predefined rules or training datasets, and limited 3D spatial reasoning ability. Since pre-trained 2D image generative models better capture scene and object configuration than LLMs, we address these challenges by introducing Architect, a generative framework that creates complex and realistic 3D embodied environments leveraging diffusion-based 2D image inpainting. In detail, we utilize foundation visual perception models to obtain each generated object from the image and leverage pre-trained depth estimation models to lift the generated 2D image to 3D space. Our pipeline is further extended to a hierarchical and iterative inpainting process to continuously generate placement of large furniture and small objects to enrich the scene. This iterative structure brings the flexibility for our method to generate or refine scenes from various starting points, such as text, floor plans, or pre-arranged environments.