Advancing Fine-Grained Visual Understanding with Multi-Scale Alignment in Multi-Modal Models
作者: Wei Wang, Zhaowei Li, Qi Xu, Linfeng Li, YiQing Cai, Botian Jiang, Hang Song, Xingcan Hu, Pengyu Wang, Li Xiao
分类: cs.CV
发布日期: 2024-11-14
💡 一句话要点
提出多尺度对齐方法,提升多模态模型在细粒度视觉理解任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 细粒度视觉理解 知识对齐 数据增强 Grounding任务
📋 核心要点
- 现有MLLM在细粒度视觉理解中,对细粒度知识的对齐不足,限制了模型捕捉局部细节和全局感知的能力。
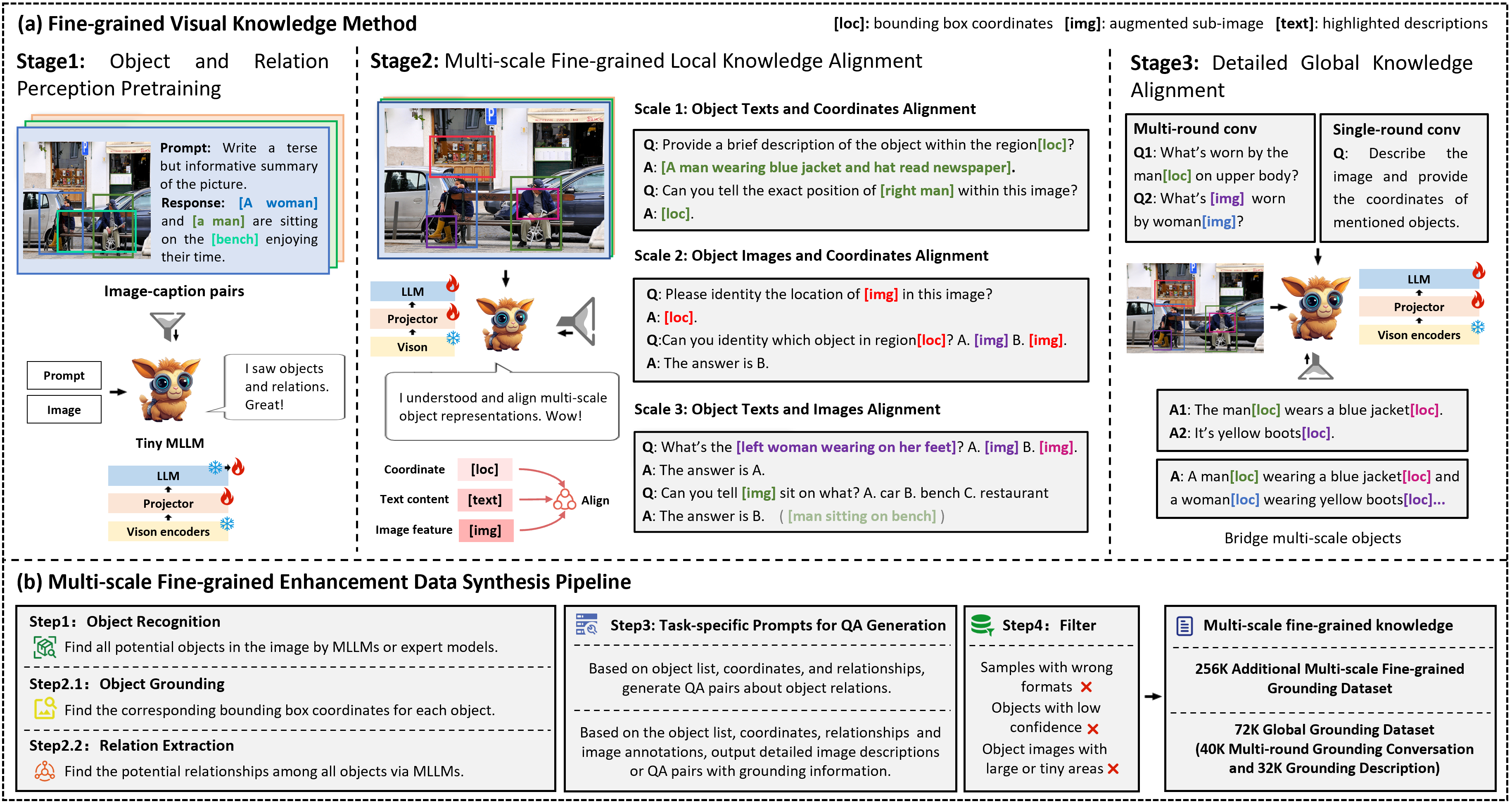
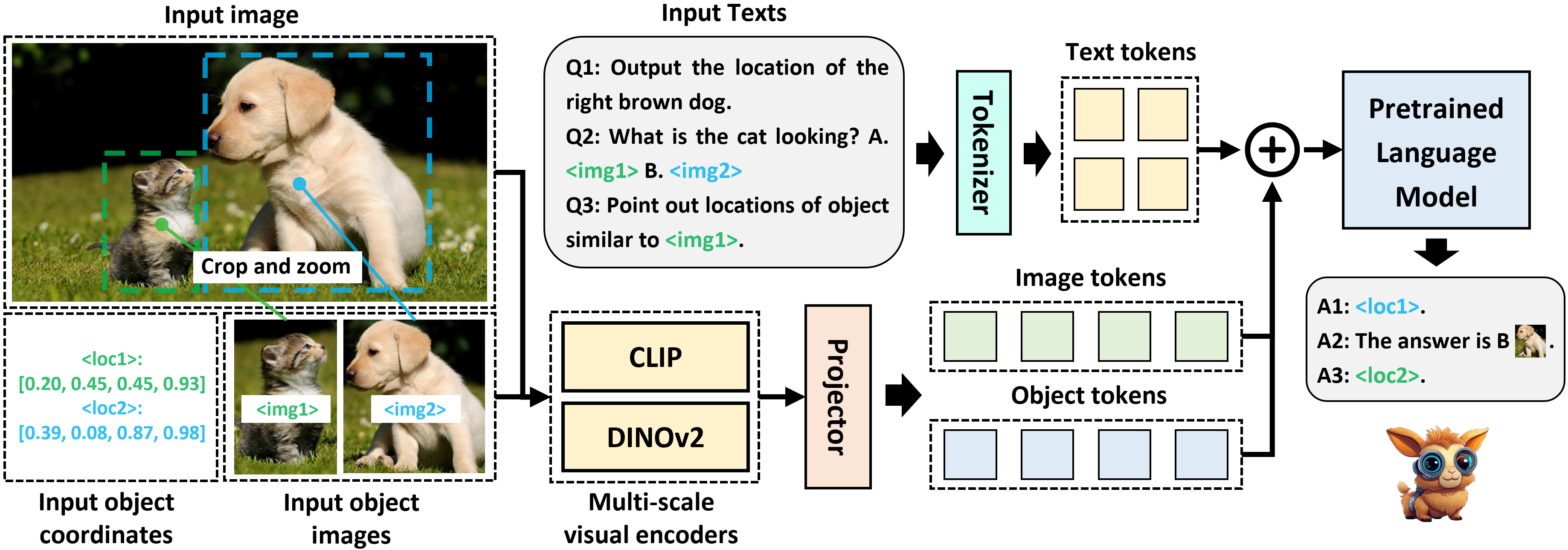
- 论文提出一种多尺度细粒度视觉知识对齐方法,有效对齐和集成对象的多尺度知识,包括文本、坐标和图像。
- 论文构建了包含超过30万条数据的多尺度细粒度增强数据合成管道,并提出了TinyGroundingGPT模型,提升了grounding任务的性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)在细粒度视觉理解的各项任务中取得了显著成功。然而,由于缺乏对细粒度知识的充分对齐,它们经常面临重大挑战,这限制了它们准确捕捉局部细节和获得全面全局感知的能力。虽然最近的进展集中在将对象表达与 grounding 信息对齐,但它们通常缺乏对象图像的显式集成,而对象图像包含比文本或坐标更丰富的信息。为了弥合这一差距,我们引入了一种新颖的细粒度视觉知识对齐方法,该方法有效地对齐和集成对象的多尺度知识,包括文本、坐标和图像。这种创新方法以我们的多尺度细粒度增强数据合成管道为基础,该管道提供超过 30 万个基本训练数据,以增强对齐并提高整体性能。此外,我们提出了 TinyGroundingGPT,这是一系列针对高级对齐优化的紧凑模型。TinyGroundingGPT 的规模约为 30 亿个参数,在 grounding 任务中取得了出色的成果,同时在复杂的视觉场景中提供了与更大的 MLLM 相当的性能。
🔬 方法详解
问题定义:现有的多模态大型语言模型在处理细粒度视觉理解任务时,面临着知识对齐不足的问题。具体来说,模型难以有效地整合文本描述、坐标信息以及图像本身所包含的丰富信息,从而限制了其准确捕捉局部细节和进行全局推理的能力。现有方法通常侧重于文本和坐标的对齐,而忽略了图像信息的显式集成,导致视觉理解能力受限。
核心思路:论文的核心思路是通过多尺度对齐的方式,将文本、坐标和图像三种模态的信息进行有效融合。作者认为,不同模态的信息在不同尺度上都包含着重要的细粒度知识,因此需要设计一种方法,能够充分利用这些信息,从而提升模型的视觉理解能力。这种多尺度对齐的思路旨在弥补现有方法在图像信息利用方面的不足。
技术框架:论文提出的方法主要包含两个部分:多尺度细粒度增强数据合成管道和TinyGroundingGPT模型。数据合成管道用于生成包含文本、坐标和图像信息的训练数据,以增强模型的对齐能力。TinyGroundingGPT模型则是一个针对高级对齐优化的紧凑模型,用于执行grounding任务。整体流程是首先利用数据合成管道生成训练数据,然后利用这些数据训练TinyGroundingGPT模型,最后利用训练好的模型进行细粒度视觉理解任务。
关键创新:论文的关键创新在于提出了多尺度细粒度视觉知识对齐方法,该方法能够有效地对齐和集成对象的多尺度知识,包括文本、坐标和图像。与现有方法相比,该方法更加注重图像信息的利用,并且能够将不同模态的信息在不同尺度上进行有效融合。此外,论文还提出了多尺度细粒度增强数据合成管道,为模型的训练提供了充足的数据支持。
关键设计:论文的关键设计包括:(1) 多尺度特征提取模块,用于从文本、坐标和图像中提取不同尺度的特征;(2) 多模态融合模块,用于将不同模态的特征进行融合;(3) 对齐损失函数,用于约束不同模态特征之间的对齐关系;(4) TinyGroundingGPT模型的网络结构设计,使其能够在保持性能的同时,尽可能地减小模型规模。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
TinyGroundingGPT模型在 grounding 任务中取得了出色的成果,在参数规模约为 30 亿的情况下,性能与更大的 MLLM 相当。论文构建的多尺度细粒度增强数据合成管道,提供了超过 30 万个基本训练数据,显著提升了模型的对齐能力和整体性能。实验结果表明,该方法在细粒度视觉理解任务上具有显著优势。
🎯 应用场景
该研究成果可广泛应用于智能零售、自动驾驶、医学影像分析等领域。例如,在智能零售中,可以利用该技术实现对商品细节的精准识别和定位;在自动驾驶中,可以提升车辆对复杂交通场景的理解能力;在医学影像分析中,可以辅助医生进行疾病诊断和病灶定位。该研究的实际价值在于提升了多模态模型在细粒度视觉理解任务上的性能,未来有望推动相关领域的技术发展。
📄 摘要(原文)
Multi-modal large language models (MLLMs) have achieved remarkable success in fine-grained visual understanding across a range of tasks. However, they often encounter significant challenges due to inadequate alignment for fine-grained knowledge, which restricts their ability to accurately capture local details and attain a comprehensive global perception. While recent advancements have focused on aligning object expressions with grounding information, they typically lack explicit integration of object images, which contain affluent information beyond mere texts or coordinates. To bridge this gap, we introduce a novel fine-grained visual knowledge alignment method that effectively aligns and integrates multi-scale knowledge of objects, including texts, coordinates, and images. This innovative method is underpinned by our multi-scale fine-grained enhancement data synthesis pipeline, which provides over 300K essential training data to enhance alignment and improve overall performance. Furthermore, we present TinyGroundingGPT, a series of compact models optimized for high-level alignments. With a scale of approximately 3B parameters, TinyGroundingGPT achieves outstanding results in grounding tasks while delivering performance comparable to larger MLLMs in complex visual scenarios.