How Good is ChatGPT at Audiovisual Deepfake Detection: A Comparative Study of ChatGPT, AI Models and Human Perception
作者: Sahibzada Adil Shahzad, Ammarah Hashmi, Yan-Tsung Peng, Yu Tsao, Hsin-Min Wang
分类: cs.CV, cs.AI, cs.HC, cs.LG, cs.MM
发布日期: 2024-11-14
💡 一句话要点
评估ChatGPT在音视频深度伪造检测中的能力,并与AI模型和人类感知进行对比
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度伪造检测 大型语言模型 ChatGPT 多模态分析 提示工程
📋 核心要点
- 现有的音视频深度伪造检测方法,如多模态取证模型,计算成本高昂且泛化能力不足,难以应对新型伪造。
- 本研究探索利用大型语言模型ChatGPT,通过分析音视频内容中的伪影和不一致性,进行深度伪造检测。
- 实验结果表明,结合领域知识和提示工程,ChatGPT在音视频伪造检测中展现出潜力,但仍存在局限性。
📝 摘要(中文)
多模态深度伪造,特别是涉及音视频操纵的,正日益成为一种威胁,因为它们难以用肉眼或基于单模态深度学习的伪造检测方法检测。音视频取证模型虽然比单模态模型更强大,但需要大量的训练数据集,并且训练和推理的计算成本很高。此外,这些模型缺乏可解释性,并且通常不能很好地泛化到未见过的操纵。本研究探讨了大型语言模型(LLM)(即ChatGPT)的检测能力,以识别和解释音视频深度伪造内容中任何可能的视觉和听觉伪影和操纵。在基准多模态深度伪造数据集中的视频上进行了广泛的实验,以评估ChatGPT的检测性能,并将其与最先进的多模态取证模型和人类的检测能力进行比较。实验结果表明,领域知识和提示工程对于使用LLM进行视频伪造检测任务的重要性。与基于端到端学习的方法不同,ChatGPT可以解释可能存在于模态内部或跨模态的空间和时空伪影和不一致。此外,我们还讨论了ChatGPT在多媒体取证任务中的局限性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM),特别是ChatGPT,在检测音视频深度伪造方面的能力。现有方法,如基于深度学习的音视频取证模型,虽然有效,但存在计算成本高、需要大量训练数据、缺乏可解释性以及泛化能力差等问题。这些模型难以适应新的、未见过的伪造技术,并且难以解释其检测结果。
核心思路:论文的核心思路是利用LLM的自然语言理解和推理能力,将音视频深度伪造检测问题转化为一个文本理解和推理问题。通过精心设计的提示(prompt),引导ChatGPT分析音视频内容中的视觉和听觉伪影、不一致性以及其他可疑特征,从而判断视频是否为深度伪造。这种方法避免了传统深度学习模型对大量训练数据的依赖,并具有更好的可解释性。
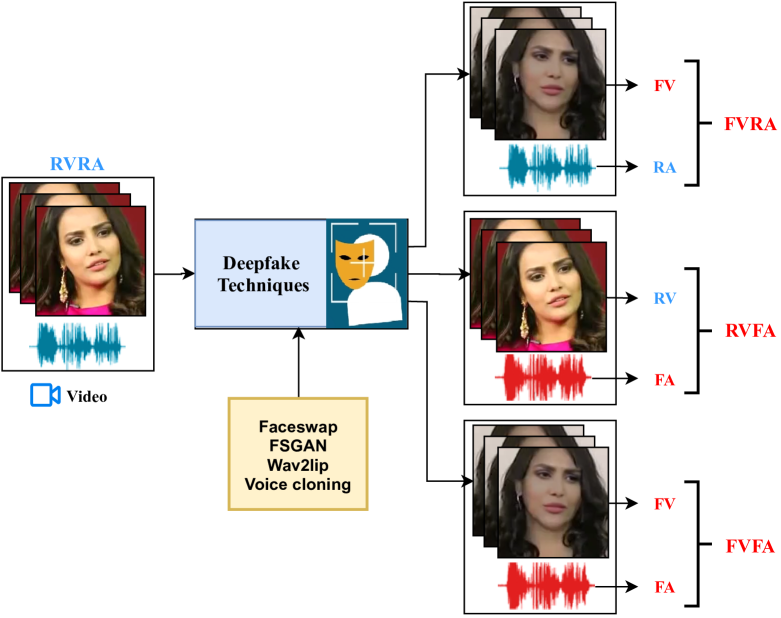
技术框架:论文的技术框架主要包括以下几个步骤:1) 数据准备:从基准多模态深度伪造数据集中选择视频样本。2) 提示工程:设计合适的提示,引导ChatGPT分析视频内容,例如“这段视频中是否存在视觉或听觉上的不一致?”。3) ChatGPT推理:将视频描述和提示输入ChatGPT,获取其对视频真伪的判断。4) 结果评估:将ChatGPT的判断结果与真实标签进行比较,评估其检测性能。同时,与最先进的多模态取证模型和人类的判断结果进行对比。
关键创新:论文的关键创新在于将大型语言模型应用于音视频深度伪造检测领域。与传统的端到端学习方法不同,ChatGPT能够利用其预训练的知识和推理能力,分析视频内容中的语义信息和上下文关系,从而发现潜在的伪造痕迹。此外,通过提示工程,可以灵活地调整ChatGPT的检测策略,使其适应不同的伪造类型。
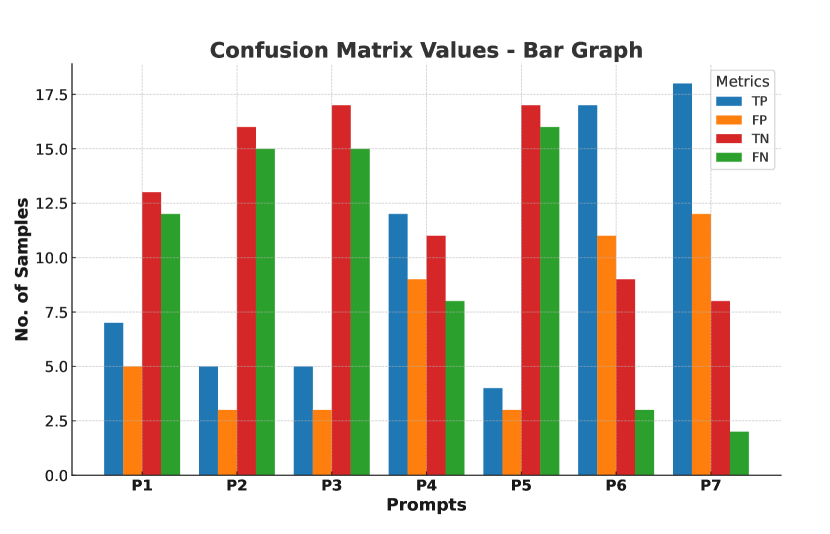
关键设计:论文的关键设计包括:1) 提示工程:设计了多种类型的提示,包括通用提示和特定提示,以引导ChatGPT从不同角度分析视频内容。2) 对比实验:将ChatGPT的检测性能与最先进的多模态取证模型和人类的判断结果进行对比,全面评估其优缺点。3) 误差分析:分析ChatGPT的错误判断案例,找出其在深度伪造检测方面的局限性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ChatGPT在音视频深度伪造检测方面具有一定的潜力,尤其是在识别跨模态的不一致性方面。通过精心设计的提示,ChatGPT的检测性能可以接近甚至超过某些传统的多模态取证模型。然而,ChatGPT在处理复杂的伪造场景和细微的伪影时仍存在局限性,需要进一步改进。
🎯 应用场景
该研究成果可应用于多媒体内容安全、新闻真实性验证、社交媒体监管等领域。通过利用大型语言模型辅助检测深度伪造内容,可以有效减少虚假信息的传播,维护社会稳定和公众利益。未来,该技术有望集成到自动化内容审核系统中,提高深度伪造检测的效率和准确性。
📄 摘要(原文)
Multimodal deepfakes involving audiovisual manipulations are a growing threat because they are difficult to detect with the naked eye or using unimodal deep learningbased forgery detection methods. Audiovisual forensic models, while more capable than unimodal models, require large training datasets and are computationally expensive for training and inference. Furthermore, these models lack interpretability and often do not generalize well to unseen manipulations. In this study, we examine the detection capabilities of a large language model (LLM) (i.e., ChatGPT) to identify and account for any possible visual and auditory artifacts and manipulations in audiovisual deepfake content. Extensive experiments are conducted on videos from a benchmark multimodal deepfake dataset to evaluate the detection performance of ChatGPT and compare it with the detection capabilities of state-of-the-art multimodal forensic models and humans. Experimental results demonstrate the importance of domain knowledge and prompt engineering for video forgery detection tasks using LLMs. Unlike approaches based on end-to-end learning, ChatGPT can account for spatial and spatiotemporal artifacts and inconsistencies that may exist within or across modalities. Additionally, we discuss the limitations of ChatGPT for multimedia forensic tasks.