VidMan: Exploiting Implicit Dynamics from Video Diffusion Model for Effective Robot Manipulation
作者: Youpeng Wen, Junfan Lin, Yi Zhu, Jianhua Han, Hang Xu, Shen Zhao, Xiaodan Liang
分类: cs.CV, cs.RO
发布日期: 2024-11-14
备注: Accepted to NeurIPS 2024
💡 一句话要点
VidMan:利用视频扩散模型中的隐式动力学,提升机器人操作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 视频扩散模型 隐式动力学 迁移学习 逆动力学模型
📋 核心要点
- 现有机器人数据量小,直接拟合数据而不考虑视觉观察和动作之间的关系,导致数据利用率低。
- VidMan通过两阶段训练,首先学习环境动力学,然后利用自注意力适配器预测动作,提升数据利用率。
- 实验表明,VidMan在CALVIN和OXE数据集上优于现有方法,证明了世界模型对机器人动作预测的有效性。
📝 摘要(中文)
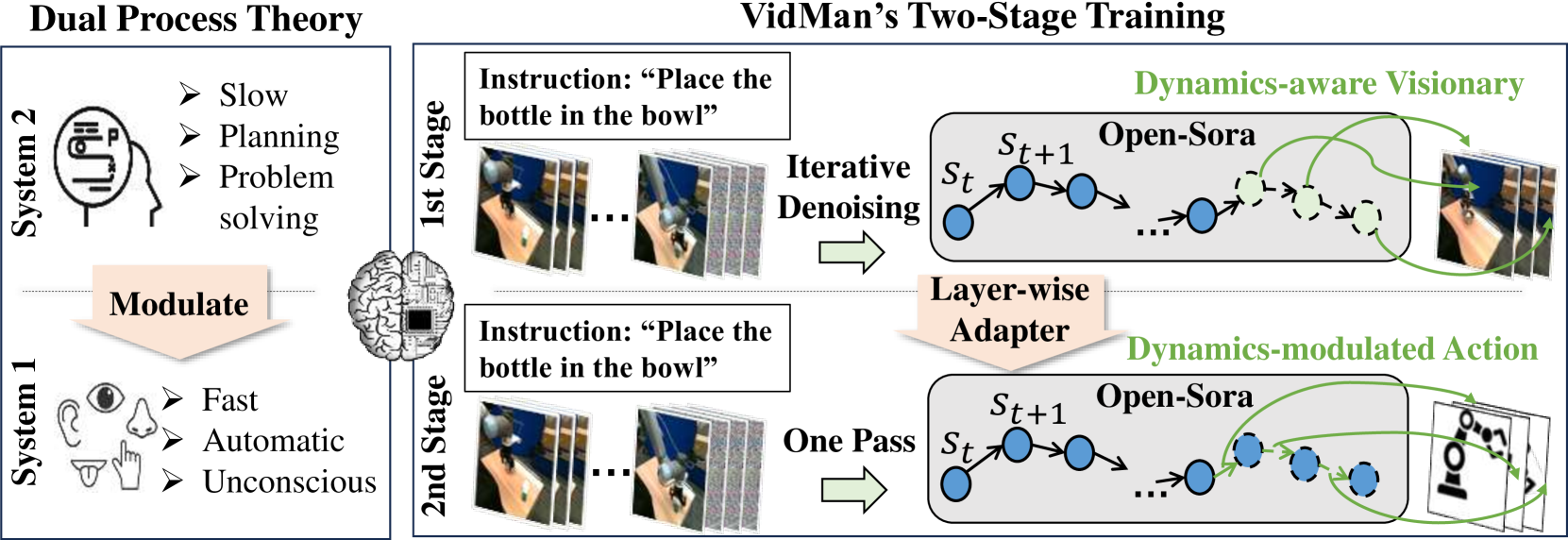
本文提出VidMan(Video Diffusion for Robot Manipulation),一个新颖的框架,它采用受神经科学双过程理论启发的两阶段训练机制,以增强稳定性和提高数据利用效率。第一阶段,VidMan在Open X-Embodiment数据集(OXE)上进行预训练,以视频去噪扩散的方式预测未来的视觉轨迹,使模型能够发展对环境动力学的长期水平感知。第二阶段,引入一个灵活而有效的层级自注意力适配器,通过参数共享将VidMan转换为高效的逆动力学模型,预测由隐式动力学知识调节的动作。在CALVIN基准测试中,VidMan框架优于最先进的基线模型GR-1,实现了11.7%的相对改进,并在OXE小规模数据集上展示了超过9%的精度提升。这些结果提供了令人信服的证据,表明世界模型可以显著提高机器人动作预测的精度。代码和模型将公开。
🔬 方法详解
问题定义:现有机器人操作方法面临数据量不足的挑战,直接从少量数据中学习视觉观察到动作的映射关系,容易过拟合,难以泛化到新的环境和任务。此外,忽略了视觉信息中蕴含的动力学信息,导致模型难以准确预测未来的状态和动作。
核心思路:VidMan的核心思路是利用大规模视频数据预训练的视频扩散模型,学习环境的隐式动力学信息,然后通过迁移学习的方式,将这些知识应用到机器人操作任务中。这种方法可以有效利用有限的机器人数据,提高模型的泛化能力和预测精度。
技术框架:VidMan框架包含两个主要阶段:1) 预训练阶段:使用Open X-Embodiment数据集(OXE)训练视频扩散模型,使其能够预测未来的视觉轨迹。2) 微调阶段:引入层级自注意力适配器,将预训练的视频扩散模型转换为逆动力学模型,预测由隐式动力学知识调节的动作。该适配器通过参数共享,有效利用了预训练模型学习到的动力学知识。
关键创新:VidMan的关键创新在于利用视频扩散模型学习环境的隐式动力学信息,并将其迁移到机器人操作任务中。与传统的直接学习视觉到动作的映射关系的方法相比,VidMan能够更好地利用数据,提高模型的泛化能力和预测精度。此外,层级自注意力适配器的设计,使得模型能够灵活地调整预训练模型的参数,适应不同的机器人操作任务。
关键设计:VidMan使用视频去噪扩散模型作为预训练模型,该模型能够生成高质量的未来视觉轨迹。层级自注意力适配器包含多个自注意力层,每一层都能够学习不同的动力学信息。在微调阶段,使用逆动力学损失函数,使得模型能够准确预测执行特定动作所需的控制信号。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
VidMan在CALVIN基准测试中,相对于最先进的基线模型GR-1,取得了11.7%的相对改进。在OXE小规模数据集上,VidMan的精度提升超过9%。这些实验结果表明,VidMan能够有效地利用视频扩散模型学习到的动力学信息,提高机器人动作预测的精度。
🎯 应用场景
VidMan框架具有广泛的应用前景,可以应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过学习环境的动力学信息,机器人可以更好地理解周围环境,从而做出更准确、更有效的决策。此外,VidMan还可以应用于虚拟现实、游戏等领域,生成更逼真的虚拟环境和角色动作。
📄 摘要(原文)
Recent advancements utilizing large-scale video data for learning video generation models demonstrate significant potential in understanding complex physical dynamics. It suggests the feasibility of leveraging diverse robot trajectory data to develop a unified, dynamics-aware model to enhance robot manipulation. However, given the relatively small amount of available robot data, directly fitting data without considering the relationship between visual observations and actions could lead to suboptimal data utilization. To this end, we propose VidMan (Video Diffusion for Robot Manipulation), a novel framework that employs a two-stage training mechanism inspired by dual-process theory from neuroscience to enhance stability and improve data utilization efficiency. Specifically, in the first stage, VidMan is pre-trained on the Open X-Embodiment dataset (OXE) for predicting future visual trajectories in a video denoising diffusion manner, enabling the model to develop a long horizontal awareness of the environment's dynamics. In the second stage, a flexible yet effective layer-wise self-attention adapter is introduced to transform VidMan into an efficient inverse dynamics model that predicts action modulated by the implicit dynamics knowledge via parameter sharing. Our VidMan framework outperforms state-of-the-art baseline model GR-1 on the CALVIN benchmark, achieving a 11.7% relative improvement, and demonstrates over 9% precision gains on the OXE small-scale dataset. These results provide compelling evidence that world models can significantly enhance the precision of robot action prediction. Codes and models will be public.