Multimodal Object Detection using Depth and Image Data for Manufacturing Parts
作者: Nazanin Mahjourian, Vinh Nguyen
分类: cs.CV, cs.AI, cs.RO
发布日期: 2024-11-13 (更新: 2025-06-30)
💡 一句话要点
提出一种基于深度和图像数据的多模态目标检测方法,用于提升制造零件识别的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 目标检测 深度学习 智能制造 Faster R-CNN
📋 核心要点
- 传统方法依赖单一传感器,RGB图像缺乏深度信息,3D传感器缺乏颜色信息,限制了目标检测的可靠性和鲁棒性。
- 提出一种多模态目标检测方法,融合RGB图像和深度数据,利用校准后的多传感器系统,提升检测性能。
- 实验结果表明,该多模态模型在mAP和平均精度上显著优于仅使用RGB或深度的基线模型,提升效果明显。
📝 摘要(中文)
为了在制造过程中精确地拾取和处理各种制造零件和组件,需要可靠的目标检测方法。传统的目标检测方法通常只使用来自相机的2D图像或来自激光雷达等3D传感器的数据。然而,这些传感器各有优缺点。相机缺乏深度感知能力,而3D传感器通常不包含颜色信息。这些弱点会降低工业制造系统的可靠性和鲁棒性。为了解决这些挑战,本文提出了一种多传感器系统,该系统结合了红绿蓝(RGB)相机和3D点云传感器。对这两个传感器进行校准,以精确对齐从两个硬件设备捕获的多模态数据。开发了一种新的多模态目标检测方法来处理RGB和深度数据。该目标检测器基于最初设计为仅处理相机图像的Faster R-CNN。结果表明,多模态模型在既定的目标检测指标上明显优于仅使用深度和仅使用RGB的基线模型。更具体地说,与仅使用RGB的基线模型相比,多模态模型将mAP提高了13%,平均精度提高了11.8%。与仅使用深度的基线模型相比,它将mAP提高了78%,平均精度提高了57%。因此,该方法有助于在智能制造应用中实现更可靠和鲁棒的目标检测。
🔬 方法详解
问题定义:论文旨在解决制造环境中目标检测的可靠性和鲁棒性问题。现有方法要么仅依赖RGB图像,缺乏深度信息,导致对光照变化敏感;要么仅依赖3D数据,缺乏颜色信息,难以区分相似物体。这些局限性影响了智能制造系统中零件的精确拾取和处理。
核心思路:论文的核心思路是融合RGB图像和深度数据,利用多模态信息互补的优势,提高目标检测的准确性和鲁棒性。通过精确校准RGB相机和3D传感器,将两种数据对齐,然后设计一种能够同时处理RGB和深度数据的目标检测器。
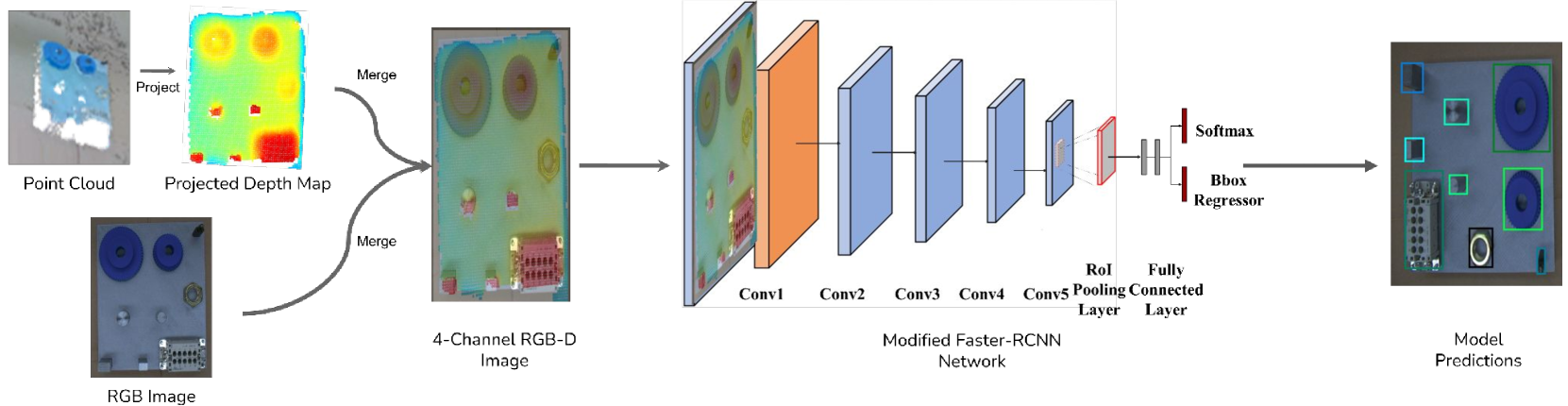
技术框架:整体框架包括数据采集、传感器校准、特征提取和目标检测四个主要阶段。首先,使用RGB相机和3D传感器同时采集数据。然后,通过传感器校准,将RGB图像和3D点云数据对齐。接着,从RGB图像和深度数据中提取特征。最后,使用改进的Faster R-CNN进行目标检测。
关键创新:论文的关键创新在于提出了一种能够有效融合RGB和深度数据的多模态目标检测方法。该方法扩展了Faster R-CNN,使其能够同时处理RGB图像和深度数据,从而充分利用了两种模态的信息。
关键设计:论文基于Faster R-CNN框架,并对其进行了修改以适应多模态输入。具体的技术细节包括:使用校准后的RGB图像和深度图作为输入;设计了能够同时处理RGB和深度特征的网络结构;可能使用了特定的融合策略,例如特征级别的拼接或注意力机制(具体细节未知)。损失函数沿用Faster R-CNN的损失函数,包括分类损失和回归损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该多模态模型在目标检测性能上取得了显著提升。与仅使用RGB的基线模型相比,多模态模型将mAP提高了13%,平均精度提高了11.8%。与仅使用深度的基线模型相比,它将mAP提高了78%,平均精度提高了57%。这些数据表明,多模态融合能够有效提高目标检测的准确性和鲁棒性。
🎯 应用场景
该研究成果可广泛应用于智能制造领域,例如机器人自动抓取、零件识别与定位、质量检测等。通过提高目标检测的可靠性和鲁棒性,可以提升生产效率,降低人工成本,并实现更智能化的生产流程。未来,该方法可以进一步扩展到其他多传感器融合的场景,例如自动驾驶、安防监控等。
📄 摘要(原文)
Manufacturing requires reliable object detection methods for precise picking and handling of diverse types of manufacturing parts and components. Traditional object detection methods utilize either only 2D images from cameras or 3D data from lidars or similar 3D sensors. However, each of these sensors have weaknesses and limitations. Cameras do not have depth perception and 3D sensors typically do not carry color information. These weaknesses can undermine the reliability and robustness of industrial manufacturing systems. To address these challenges, this work proposes a multi-sensor system combining an red-green-blue (RGB) camera and a 3D point cloud sensor. The two sensors are calibrated for precise alignment of the multimodal data captured from the two hardware devices. A novel multimodal object detection method is developed to process both RGB and depth data. This object detector is based on the Faster R-CNN baseline that was originally designed to process only camera images. The results show that the multimodal model significantly outperforms the depth-only and RGB-only baselines on established object detection metrics. More specifically, the multimodal model improves mAP by 13% and raises Mean Precision by 11.8% in comparison to the RGB-only baseline. Compared to the depth-only baseline, it improves mAP by 78% and raises Mean Precision by 57%. Hence, this method facilitates more reliable and robust object detection in service to smart manufacturing applications.