Dual-Head Knowledge Distillation: Enhancing Logits Utilization with an Auxiliary Head
作者: Penghui Yang, Chen-Chen Zong, Sheng-Jun Huang, Lei Feng, Bo An
分类: cs.CV, cs.LG
发布日期: 2024-11-13 (更新: 2025-05-28)
备注: Accepted by KDD 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出双头知识蒸馏(DHKD),解决logits信息利用不充分及分类头坍塌问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 双头网络 logits蒸馏 梯度冲突
📋 核心要点
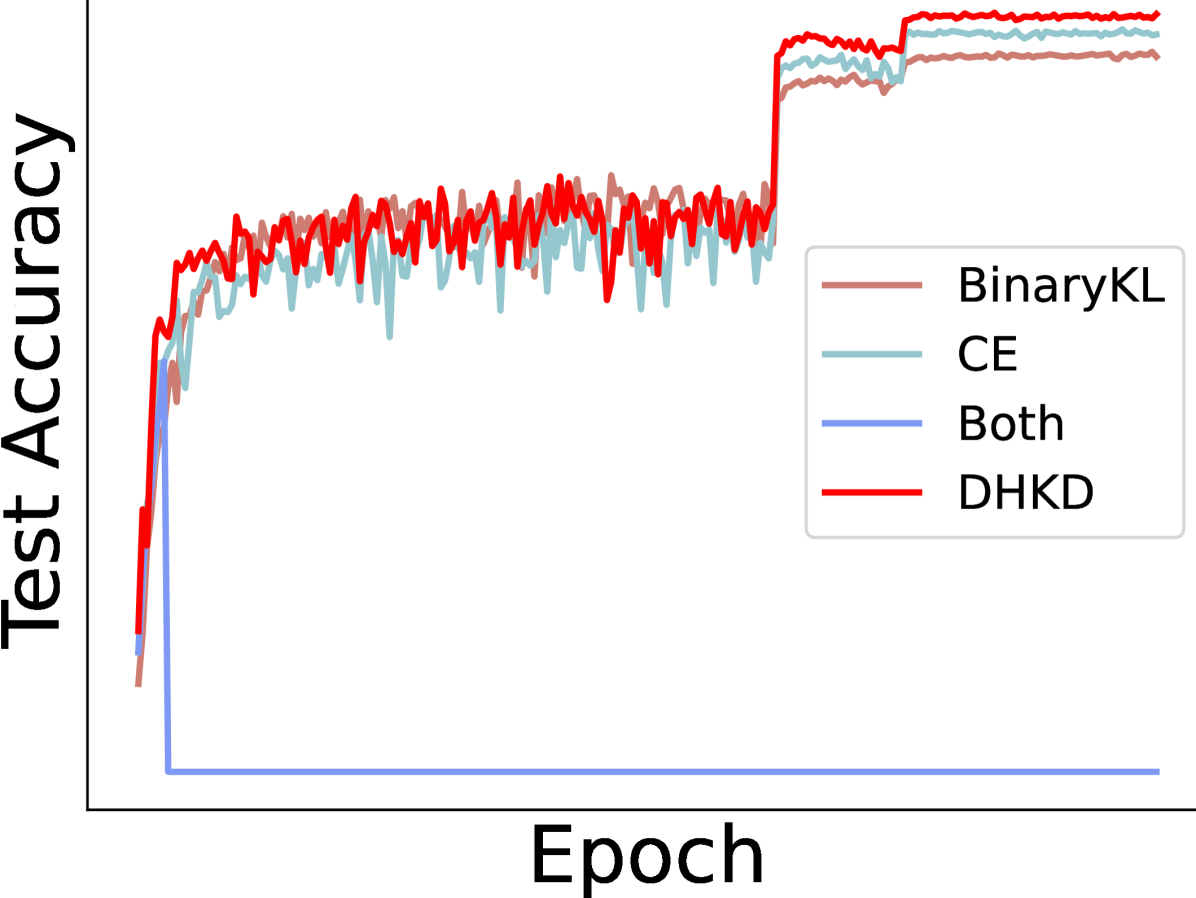
- 传统知识蒸馏忽略logits中的潜在信息,直接融合概率级别和logits级别损失会导致性能下降。
- 提出双头知识蒸馏,将线性分类器分成两个头,分别负责概率级别和logits级别损失,避免梯度冲突。
- 实验表明,DHKD能有效利用logits信息,显著提升学生模型的性能,优于现有知识蒸馏方法。
📝 摘要(中文)
传统的知识蒸馏方法侧重于使学生模型的预测概率与真实标签和教师模型的预测概率对齐。然而,从logits到预测概率的转换会掩盖一些不可或缺的信息。为了解决这个问题,很自然地引入一个logit级别的损失函数,作为广泛使用的概率级别损失函数的补充,以挖掘logits的潜在信息。然而,我们通过实验发现,新引入的logit级别损失与之前的概率级别损失的结合会导致性能下降,甚至落后于单独使用其中任何一个损失的性能。我们将这种现象归因于分类头的坍塌,这可以通过基于神经崩溃理论的理论分析来验证。具体而言,两个损失函数的梯度在线性分类器中表现出矛盾,但在backbone中没有这种冲突。从理论分析出发,我们提出了一种名为双头知识蒸馏的新方法,该方法将线性分类器划分为两个分类头,分别负责不同的损失,从而保留了两种损失对backbone的有益影响,同时消除了对分类器的不利影响。大量的实验验证了我们的方法可以有效地利用logits中的信息,并获得优于现有技术水平的性能。代码已开源。
🔬 方法详解
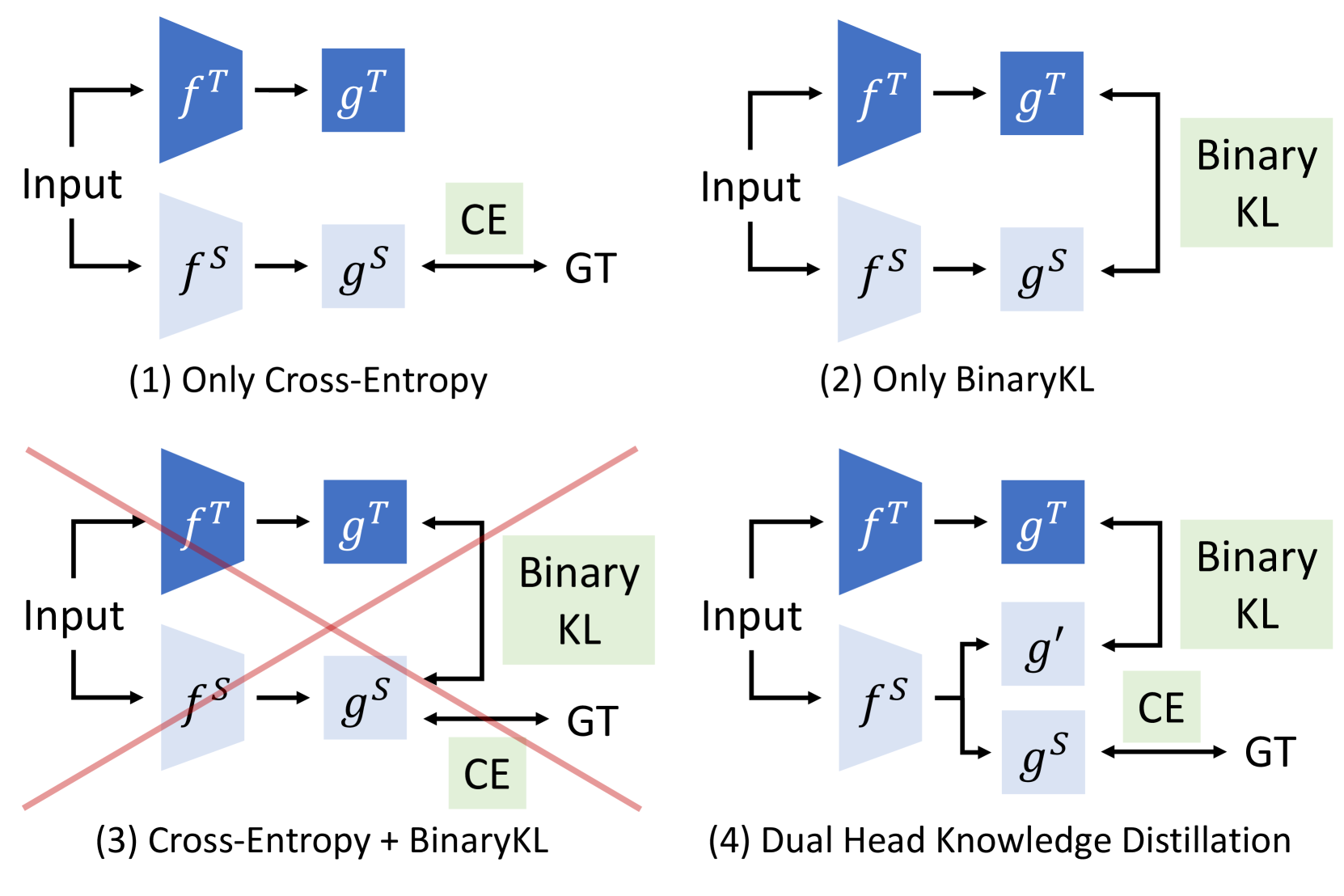
问题定义:现有知识蒸馏方法主要关注概率层面的知识迁移,忽略了logits中包含的更丰富的信息。直接将概率层面的损失和logits层面的损失结合使用,反而会导致性能下降,作者将其归因于分类头的坍塌现象,即两个损失函数的梯度在分类器层面存在冲突。
核心思路:论文的核心思路是将线性分类器分成两个独立的分类头,一个负责概率层面的知识蒸馏,另一个负责logits层面的知识蒸馏。这样可以避免两个损失函数梯度之间的直接冲突,从而保留两种损失函数对backbone的积极影响,同时避免对分类头的负面影响。
技术框架:DHKD方法包含一个教师模型和一个学生模型。学生模型的backbone与教师模型相似,但线性分类器被替换为两个独立的分类头。一个分类头用于计算概率层面的损失(例如,KL散度损失),另一个分类头用于计算logits层面的损失(例如,L2损失)。两个损失函数分别作用于对应的分类头,然后将两个分类头的输出进行融合,用于最终的预测。
关键创新:该方法最重要的创新点在于双头分类器的设计,它有效地解决了直接融合概率层面和logits层面损失导致的梯度冲突问题,从而能够充分利用logits中包含的知识。
关键设计: 1. 双头分类器结构:线性分类器被划分为两个独立的分类头,每个分类头负责不同的损失函数。 2. 损失函数设计:概率层面的损失通常采用KL散度损失,logits层面的损失通常采用L2损失。 3. 融合策略:两个分类头的输出可以通过加权平均或其他融合策略进行组合,以获得最终的预测结果。权重的选择可以根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DHKD方法在多个图像分类数据集上取得了显著的性能提升,超越了现有的知识蒸馏方法。例如,在CIFAR-100数据集上,DHKD方法相比于基线方法提升了超过2个百分点。此外,DHKD方法在不同的网络结构和数据集上都表现出良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于模型压缩和加速领域,特别是在资源受限的设备上部署高性能深度学习模型。通过知识蒸馏,可以将大型教师模型的知识迁移到小型学生模型,从而在保持性能的同时降低计算成本和内存占用。例如,可应用于移动设备上的图像识别、目标检测等任务。
📄 摘要(原文)
Traditional knowledge distillation focuses on aligning the student's predicted probabilities with both ground-truth labels and the teacher's predicted probabilities. However, the transition to predicted probabilities from logits would obscure certain indispensable information. To address this issue, it is intuitive to additionally introduce a logit-level loss function as a supplement to the widely used probability-level loss function, for exploiting the latent information of logits. Unfortunately, we empirically find that the amalgamation of the newly introduced logit-level loss and the previous probability-level loss will lead to performance degeneration, even trailing behind the performance of employing either loss in isolation. We attribute this phenomenon to the collapse of the classification head, which is verified by our theoretical analysis based on the neural collapse theory. Specifically, the gradients of the two loss functions exhibit contradictions in the linear classifier yet display no such conflict within the backbone. Drawing from the theoretical analysis, we propose a novel method called dual-head knowledge distillation, which partitions the linear classifier into two classification heads responsible for different losses, thereby preserving the beneficial effects of both losses on the backbone while eliminating adverse influences on the classification head. Extensive experiments validate that our method can effectively exploit the information inside the logits and achieve superior performance against state-of-the-art counterparts. Our code is available at: https://github.com/penghui-yang/DHKD.