Multimodal Instruction Tuning with Hybrid State Space Models
作者: Jianing Zhou, Han Li, Shuai Zhang, Ning Xie, Ruijie Wang, Xiaohan Nie, Sheng Liu, Lingyun Wang
分类: cs.CV
发布日期: 2024-11-13
💡 一句话要点
提出混合Transformer-MAMBA模型,高效处理多模态长上下文输入。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 长上下文处理 Transformer MAMBA 高分辨率图像 高帧率视频 混合模型 计算效率
📋 核心要点
- 现有MLLM处理高分辨率图像和高帧率视频时,面临计算量大和信息损失的挑战。
- 论文提出混合Transformer-MAMBA模型,旨在高效处理长上下文,避免信息损失。
- 实验结果表明,该模型在处理长上下文时,推理效率显著提升,且具有跨分辨率推理能力。
📝 摘要(中文)
为了增强多模态大语言模型(MLLM)在处理高分辨率图像或高帧率视频等应用中的识别和理解能力,处理长上下文至关重要。图像分辨率和帧率的提高显著增加了计算需求,而自注意力机制的复杂度随序列长度呈二次方增长,进一步加剧了这一挑战。现有工作要么预训练具有长上下文的模型,忽略了效率问题,要么尝试通过下采样(例如,识别关键图像块或帧)来减少上下文长度,这可能导致信息丢失。为了规避这个问题,同时保持MLLM的卓越有效性,我们提出了一种使用混合Transformer-MAMBA模型的新方法,以有效地处理多模态应用中的长上下文。我们的多模态模型可以有效地处理超过10万个token的长上下文输入,在各种基准测试中优于现有模型。值得注意的是,与当前模型相比,我们的模型将高分辨率图像和高帧率视频的推理效率提高了约4倍,并且随着图像分辨率或视频帧的增加,效率增益也会增加。此外,我们的模型是第一个在低分辨率图像或低帧率视频上进行训练,同时能够在高分辨率图像和高帧率视频上进行推理的模型,为不同场景下的推理提供了灵活性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在处理高分辨率图像和高帧率视频等长上下文输入时面临的计算效率瓶颈和信息损失问题。现有方法要么直接使用长上下文进行预训练,计算成本高昂;要么通过下采样减少上下文长度,导致关键信息丢失。
核心思路:论文的核心思路是利用MAMBA模型的线性复杂度来替代Transformer中的自注意力机制,从而降低计算复杂度,提高处理长上下文的效率。同时,保留Transformer的全局建模能力,通过混合Transformer-MAMBA架构,在效率和性能之间取得平衡。
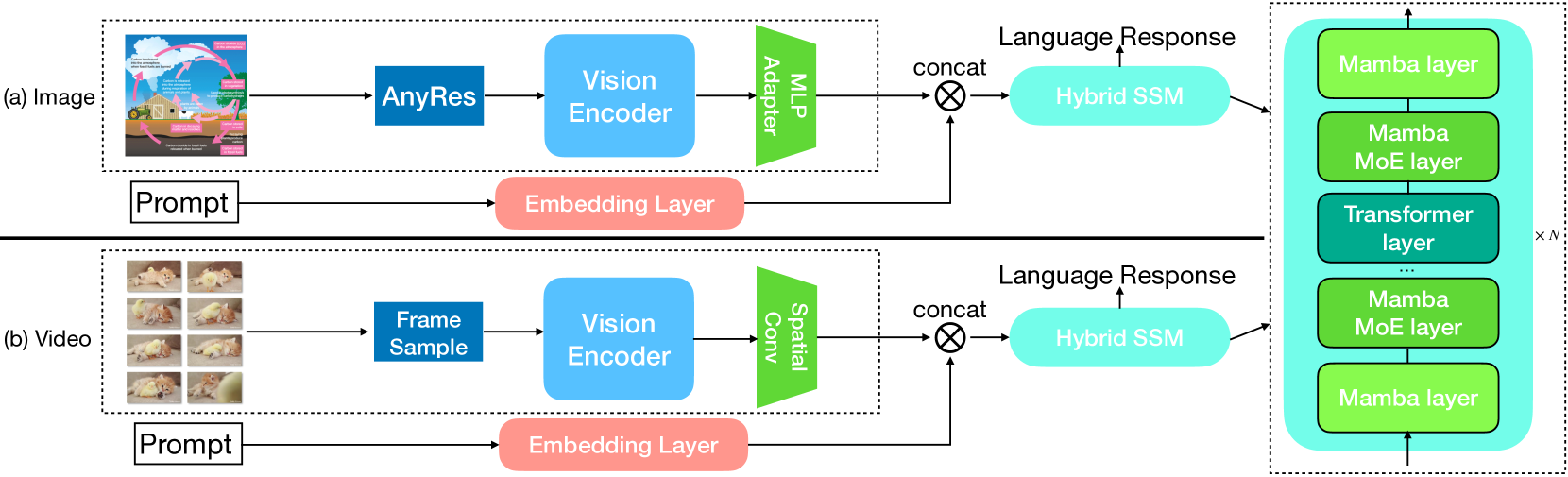
技术框架:整体架构是一个混合的Transformer-MAMBA模型。该模型可能包含以下模块:1. 视觉编码器:用于提取图像或视频帧的特征。2. Transformer层:用于捕捉全局上下文信息。3. MAMBA层:用于高效处理长序列的局部信息。4. 多模态融合模块:将视觉特征和文本信息进行融合。5. 语言模型头:用于生成文本输出。
关键创新:最重要的技术创新点在于混合Transformer-MAMBA架构的应用。MAMBA模型以其线性复杂度,显著降低了处理长序列的计算成本,使得模型能够处理超过10万token的上下文。此外,该模型还具备在低分辨率图像/低帧率视频上训练,在高分辨率图像/高帧率视频上推理的能力,提供了更大的灵活性。
关键设计:论文可能涉及的关键设计包括:1. Transformer层和MAMBA层的数量比例。2. 多模态融合的方式,例如使用注意力机制或简单的拼接。3. 训练策略,例如是否采用预训练和微调的方式。4. 损失函数的设计,可能包括语言模型损失和多模态对齐损失。
🖼️ 关键图片


📊 实验亮点
该模型能够有效处理超过10万token的长上下文输入,并在多个基准测试中优于现有模型。与现有模型相比,该模型将高分辨率图像和高帧率视频的推理效率提高了约4倍,并且随着图像分辨率或视频帧的增加,效率增益也会增加。此外,该模型首次实现了在低分辨率图像/低帧率视频上训练,在高分辨率图像/高帧率视频上推理的能力。
🎯 应用场景
该研究成果可广泛应用于需要处理高分辨率图像或高帧率视频的场景,例如智能监控、自动驾驶、医学影像分析、视频编辑等。通过提高处理长上下文的效率,可以提升这些应用在实际场景中的性能和用户体验,并降低计算成本。未来,该方法有望进一步推广到其他多模态任务中,例如视频问答、视频摘要等。
📄 摘要(原文)
Handling lengthy context is crucial for enhancing the recognition and understanding capabilities of multimodal large language models (MLLMs) in applications such as processing high-resolution images or high frame rate videos. The rise in image resolution and frame rate substantially increases computational demands due to the increased number of input tokens. This challenge is further exacerbated by the quadratic complexity with respect to sequence length of the self-attention mechanism. Most prior works either pre-train models with long contexts, overlooking the efficiency problem, or attempt to reduce the context length via downsampling (e.g., identify the key image patches or frames) to decrease the context length, which may result in information loss. To circumvent this issue while keeping the remarkable effectiveness of MLLMs, we propose a novel approach using a hybrid transformer-MAMBA model to efficiently handle long contexts in multimodal applications. Our multimodal model can effectively process long context input exceeding 100k tokens, outperforming existing models across various benchmarks. Remarkably, our model enhances inference efficiency for high-resolution images and high-frame-rate videos by about 4 times compared to current models, with efficiency gains increasing as image resolution or video frames rise. Furthermore, our model is the first to be trained on low-resolution images or low-frame-rate videos while being capable of inference on high-resolution images and high-frame-rate videos, offering flexibility for inference in diverse scenarios.